UPDATE 23-AUG-2023: The application is live here. For now, it includes grantees in the Climate Round only and will be updated for other core rounds shortly. If you take it for a spin, please share inline feedback in the app (using or ). As we understand the patterns of queries where there is room for improvement, we can get it to respond better over time.
tl;dr This is a brainstorming post to help iterate on an existing LLM-based prototype for GG18. It was originially built as a (personal) side-project and deployed for donors as Citizens GPT for grantee discovery during the Gitcoin Citizens Round. This project is undertaken in a personal capacity and does not involve any asks for resources or funding from Gitcoin.
What?
A conversational experience for GG18 donors to discover value and impact-aligned grantees.
Why?
An experience that matches the user’s style and pace to discover content is more effective than relying solely on pre-defined information hierarchies.
How?
Prospective GG18 donors can ask more information about grantees they are aware of using this utility. Alternatively, users can share the description of work they are interested in funding to discover additional grantees. Additionally, users can ask questions about the round itself in case they need help with any aspect of participating in GG18.
What already exists?
A proof-of-concept deployed during the Gitcoin Citizens Round for donors to ask questions about the grantees and the round. For example:
This is a really interesting idea, and thanks for putting it together. How will we audit the questions and responses to know whether the product is doing / is not doing what it should?
I’ll play around with this tool once the round goes live and try to give more feedback/ideas at that point.
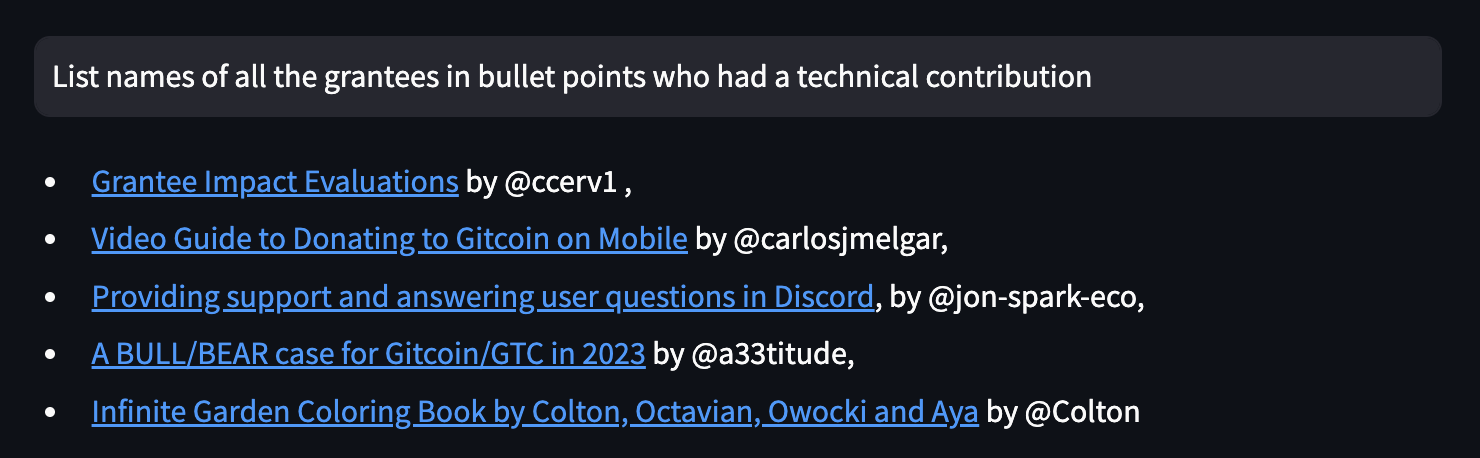
For now, the first thing that came to mind is using this for grouping grants in a given round by the technology they’re using/building. I.e. I would ask “Provide a list of all grants in the Web3 OSS round who are building on Optimism” or “Provide a list of all grants in the Climate Solutions round who are working with solar technology”, or something along those lines. I think this type of feature could be incredibly useful, especially for the larger rounds with 100+ grantees.
This is a great suggestion. I might need to pick up some more frontend skills but I will give this a shot.
The short answer is yes. The current architecture is set up such that the responses are based on curated and gated content only i.e. project details as part of the grant application and not from anything else Open AI might have already scraped or other online information. However, if the project details submitted by the grantee include links and external references, the relevant responses will offer the same links inline in the response to the user to explore further.
Mostly, yes. Behind the scenes, the product uses Open AI APIs for a semantic search for the user inquiries. The underlying models likely generate good results out of the box for a variety of languages. Will test this out more. Here’s an example in Spanish on the data set for Citizens Round.
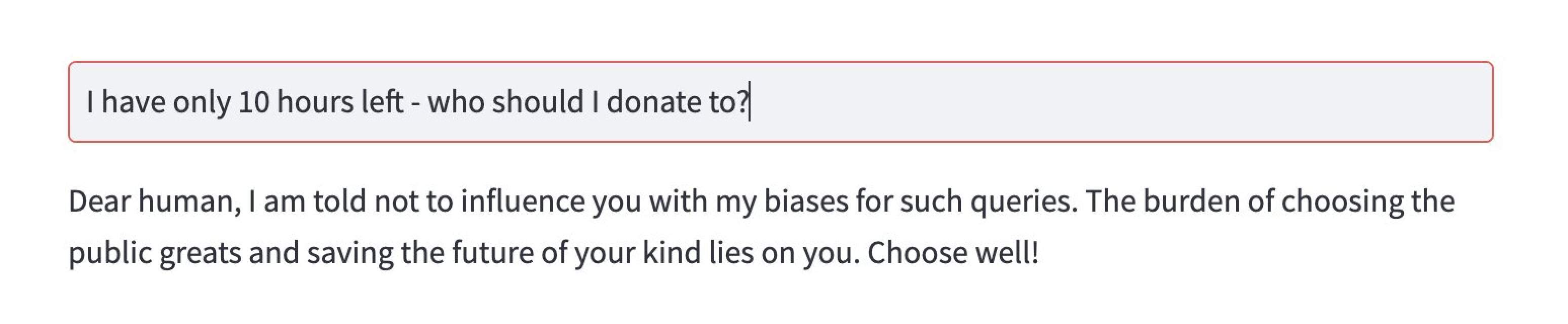
That’s a great question and the #1 risk from my standpoint from the time this was deployed for the Citizens Round. I classify this risk into two categories: (a) the need for accuracy and (b) avoiding response bias. Here are some proactive and reactive measures. This doesn’t guarantee 100% success but will help narrow down undesirable experiences.
Proactive steps:
The underlying architecture to respond to user queries is essentially a search (versus fine-tuning an AI model) over curated and gated content (single sources of truth about Gitcoin products, round information, project details, etc.) The restricted content prevents the responses from being affected by information broadly available on the Internet.
Predefined prompt templates that safeguard the neutrality of responses are embedded in the code before calls to the Open AI APIs. This will restrict the product from answering questions like, “Sort the grantees in climate round based on impact” or “Which project has the highest chances of succeeding in the long term?”
Reactive steps:
All responses will be logged to understand patterns in user questions and utilize it in informing changes, if any, needed in communications for future rounds by MMM team. This logging mechanism will also allow catching scenarios that haven’t been handled.
There will be an opportunity for the user to provide feedback on every response to escalate any inappropriate responses.
LLMs are an evolving technology and I anticipate this will be an iterative process over a few rounds to determine if this will be a useful utility for donors. If you anticipate any additional risks or concerns, please do share.
If the project detail submitted by the grantee has information about the attribute of interest (e.g. technology, domain, geography, partnerships, etc.), then the existing code should be able to respond to the type of questions you have shared. I will test this out before the code gets deployed once the grantee information is public. Here’s a preview based on the data from Citizens Round (it ain’t perfect, but close enough to the line of inquiry).
I look forward to crafting prompts to achieve a jailbreak of what the product should NOT be able to do.
On that note, I do have some questions:
are you going to go through great lengths to try to prevent jailbreaks, or do you accept that if people really want to get an LLM ranked list, that’s fine?
arguably being able to ask the LLM to filter, sort and rank specific grantees based on things I care about might actually be the painpoint I’m trying to solve? A prompt like “Give me all climate related initiatives with a focus on animal welfare, ranked by the amount of positive impact they expect to generate per $ donated” may actually save me a lot of time!
It seems to be doing okay out-of-the-box, but I would love it if you could try a language you could offer feedback on (the question in Spanish was, “What projects are working to improve the health of the oceans?”, subject to Google Translare’s accuracy … haha!)
@koday This is a work in progress, and I am not content with the quality of responses yet (missing breadth). It requires the ability to accurately pick the right chunks of information across all the grantee data sets and still be able to fit in the limited context window for an LLM. Possibly, will have a better design for GG19. But with what I could do so far, here’s a response to the question you had:
Awesome, do let me know what you find. I look forward to learning.
I see the problem space has two different challenges - information discovery and recommendation engine. Right now, I am actively trying to constrain the scope to information discovery alone. Here are a few reasons I am wary of jumping to solve for the recommendations feature for now:
I am using the out-of-the-box Open AI models for performing a semantic search on curated content (i.e. grantee project details page). Any inherent biases in the base model will likely port over in responding to questions like ranking. Probably, fine-tuning a model might be able to address this.
There is information asymmetry in the data ingested that will likely add noise to the AI recommendation. Grantee project details page with multimedia (images) and external references to richer data are ignored by LLM. A human interpreting this information manually will likely have more data points than LLM to derive inferences.
I agree! I am out of depth on the precision in data modeling required to ingest this information for high-quality inferences. “all climate related initiatives with a focus on animal welfare” is essentially a semantic search, and the app does that (it could be better). “positive impact they expect to generate” is an inference that will likely require domain-specific fine-tuning for accurate results. I will keep this in mind as I continue my explorations beyond what I have been able to code so far!