tl;dr Over 4 different rounds, GrantsScope (more context) has helped donors discover grantees through LLM-assisted conversations. As the next iteration in the quest to reduce information asymmetry for donors, the post explores two options to drive grantee recommendations in future Gitcoin Grants Rounds.
Ask
GrantsScope started as a bunch of Python scripts I used to make my decisions about contributions to Gitcoin Grants. As it found relevance and support in the community, I would love to incorporate your feedback on which direction the effort should evolve next. All feedback on the relevance and utility of the following features is welcome!
Motivation
While the use of LLMs to explore projects through questions and conversations is impactful in a variety of ways to find out about value-aligned grantees (latest examples here, here, and here), the onus to ask the relevant question is still on the user.
How might we further reduce the donor’s cognitive load when helping them discover grantees and the work they care about for rounds with a large (>100) number of participants?
OPTION 1: Personalized recommendations by tapping into historical donation data
Approach: Find the most supported projects by people who contribute to projects you most support
- Lookup user’s favorite projects based on who they contributed the most over the last year
- Tag all the voters who also supported the projects the user supported the most
- Find out what other projects this cluster of community contributed to that the user hasn’t donated for
- Sort these projects based on dollars contributed and the number of votes by the user’s cluster of community
Working Prototype: Enter your ETH address (you don’t need to sign anything) to view your personalized recommendations - https://2023-wrapped-gitcoin.streamlit.app/
Code: GitHub - grantsscope/2023wrapped: 2023 Wrapped for Gitcoin Donors
Sample: These are personalized recommendations for me based on how contributors who also support my favorite projects have donated through 2023.
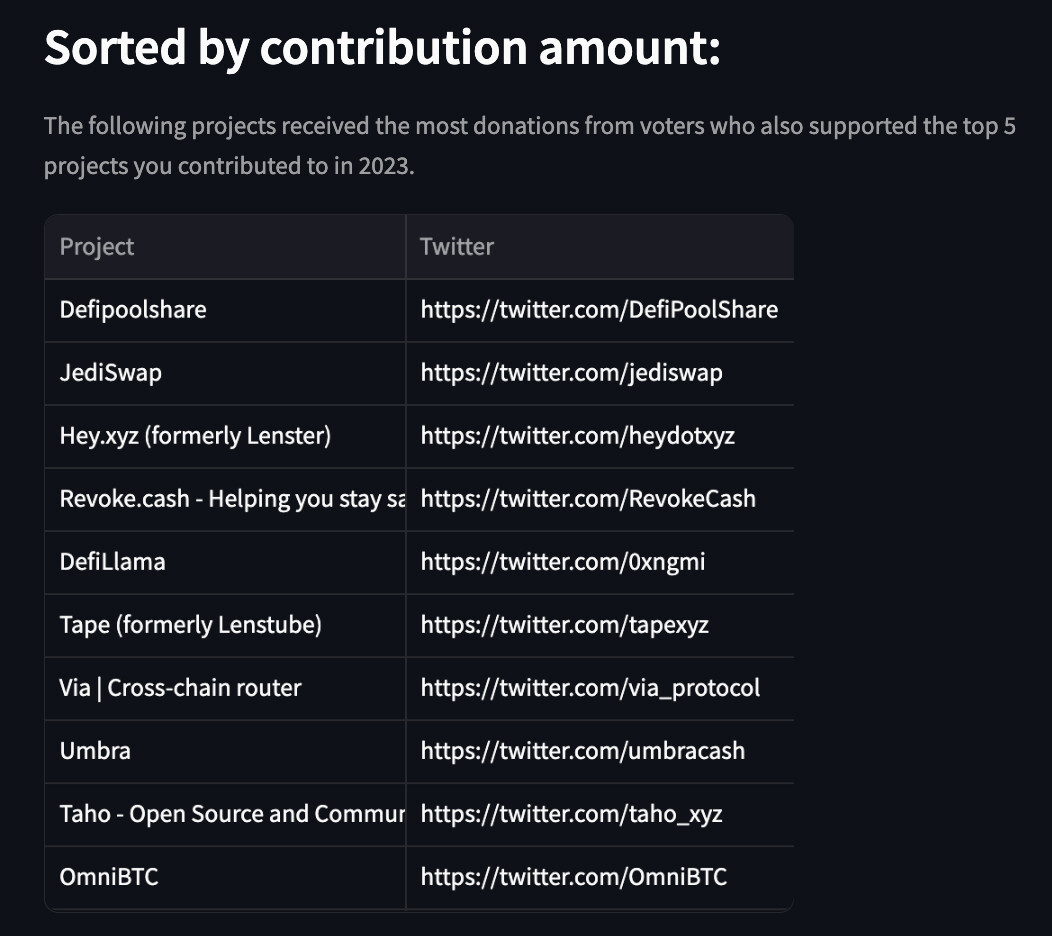
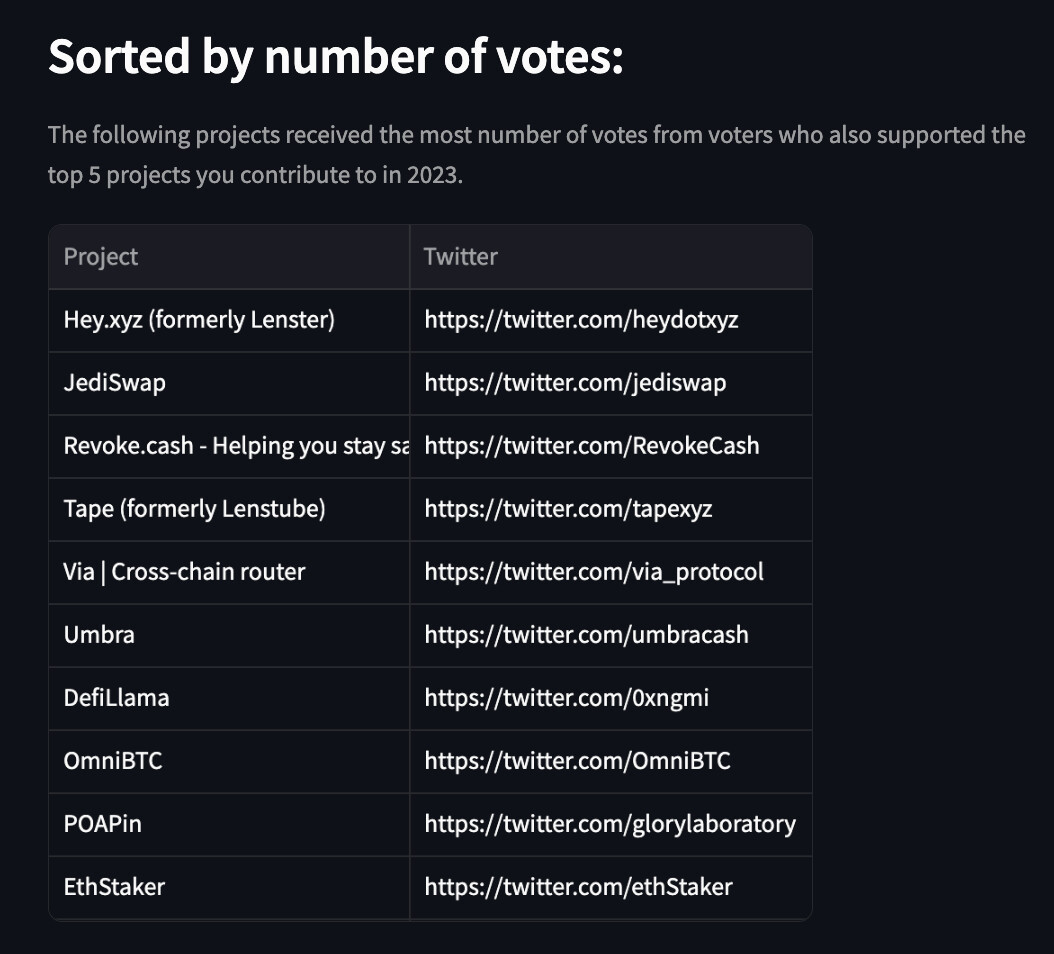
Next Steps: Deploy a round-specific personalized recommendation list for GG20 donors
Limitations:
- Since the recommendations are based on existing signals in data, they amplify existing biases too
- Does not factor impact in sorting recommendations
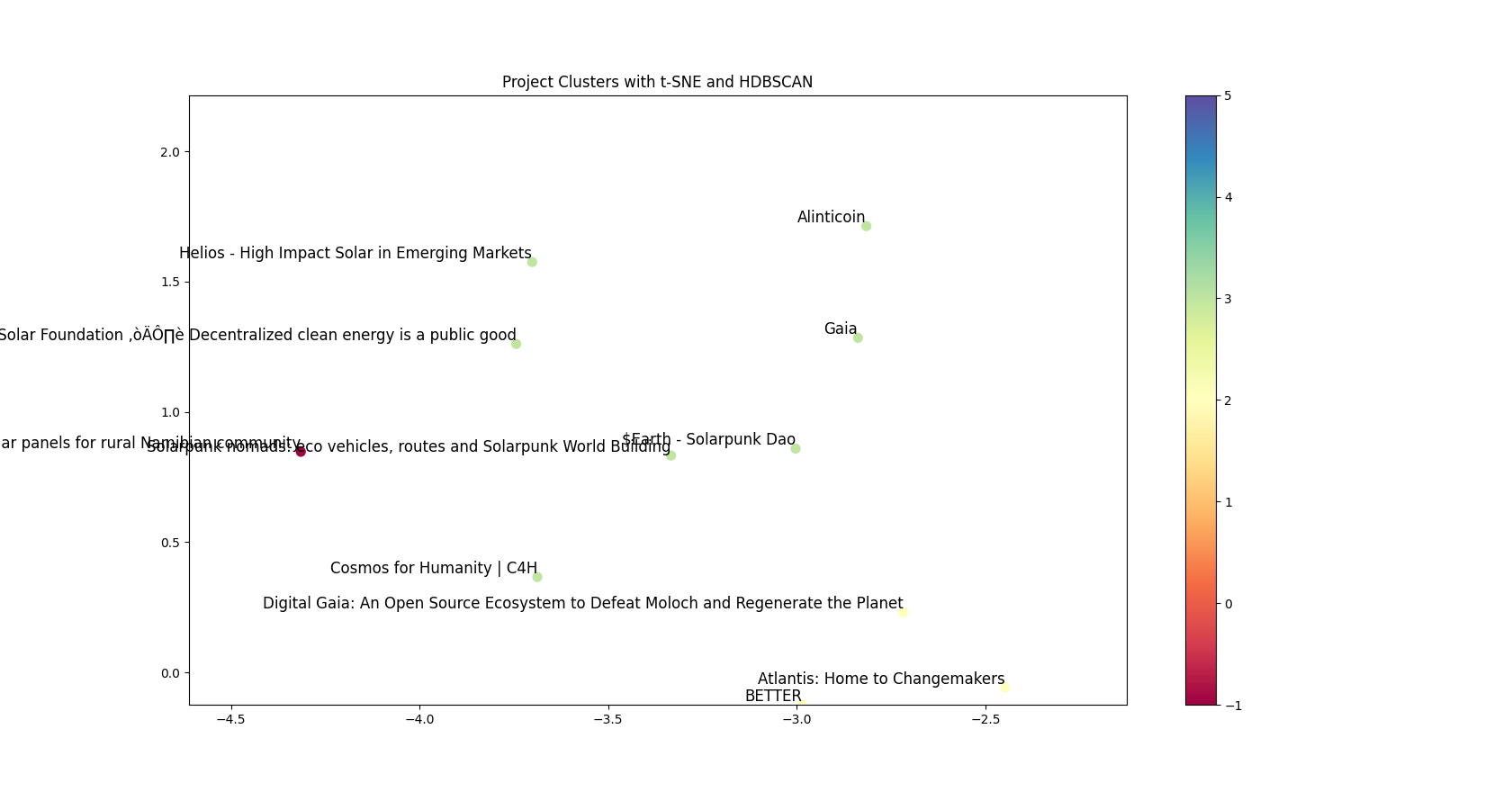
OPTION 2: Interactive visualization to discover similar projects based on clustering
Approach: One approach to exclude existing biases in contribution data for discovering new grantees is to limit the scope of data discovery to the grantee-submitted project description (and, in the future, impact). By classifying the nature of work and clustering related projects, donors can visually navigate through a crowded round based on their preferences.
As a donor, you can then overlay your investments on such a visual and choose to:
- Double down on investments in specific domains that you care about by discovering peer projects to teams you are already aware of
- Spread your funds across different clusters for a more diversified strategy
Code: For a sample set of Climate Round grantees GitHub - grantsscope/grantee-clustering: Use of HDBSCAN clustering to visualize the multi-dimensional public good space into well-defined groups of related projects in two dimensions.
Samples: Here are some algorithmically determined organic groupings of projects (a) saving water bodies, (b) protecting forests, (c) utilizing solar power, respectively
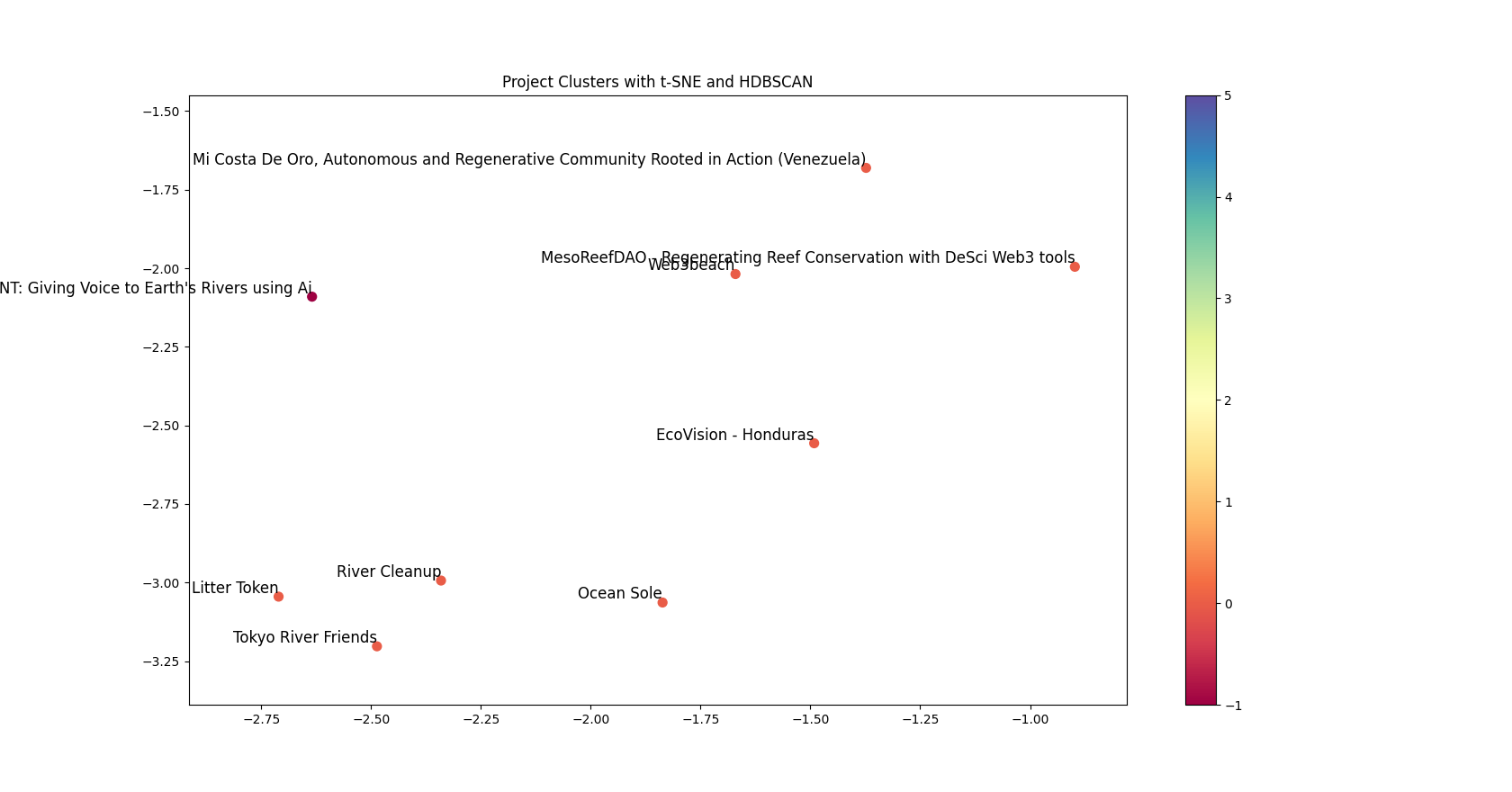
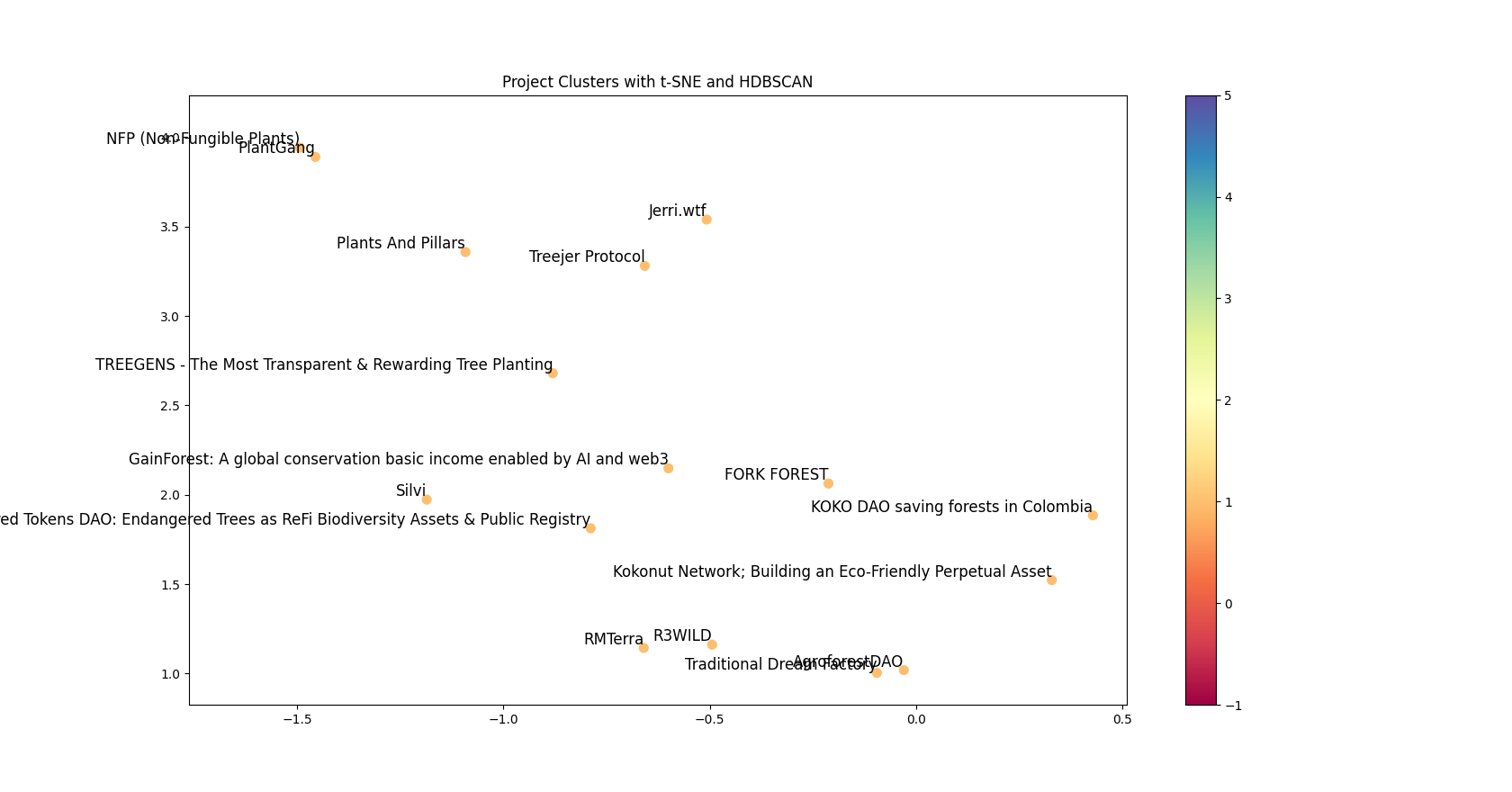
Next Steps:
- Abstract the complexity of the clustering algorithm for an intuitive interactive user experience
- Fine-tune the clustering method to suit the data and context
Limitations:
- Clustering cannot be 100% automated and requires human-in-the-loop to finalize results
- Does not factor impact yet. However, once impact data can be captured in a structured manner across grantees, performing clustering based on verified impact is worth a shot in the future.