Gitcoin Grants Data Portal
This is a Request For Feedback for the Gitcoin Grants Data Portal Gitcoin Citizens Innovate grant proposal.
 Proposal Description
Proposal Description
The proposal ask for $20k in funding over four months to enhance access to curated datasets on the Gitcoin Grants Data Portal, aiming to foster community engagement, network effects, and cost efficiency in decision-making and analysis across the ecosystem.
The Data Portal has had a significantly impact already through collaborations, better directories, analysis (e.g: clustering, visualizations), Sybil hunting, and supporting adjaccent communities (e.g: Arbitrum), enhancing data access and utility across multiple initiatives (see Impact).
For context, the Gitcoin Data Portal is an open source, serverless, and local-first open Data Platform for Gitcoin Grants Data. It has evolved into the schelling point for open and permissionless datasets around Gitcoin Grants and related areas.
 Motivation
Motivation
Frictionless access to Community Curated Gitcoin Grants Datasets
More analysis work gets done
Accessing and analyzing clean and curateed Gitcoin Grants data has been historically time-consuming and complex task. Gitcoin Data Portal removes those obstacles by providing a central hub where community curated Gitcoin Grants datasets are accessible to everybody!
By lowering the barrier of entry and having more people look into the data, we expect to see more people re-using the curated datasets to make better decisions and produce interesting reports and tools!
 Specifications
Specifications
Proposal is split into two stages. First we improve data portal by making it more accessible. Then, focus on increasing its utility and profile by opening it to relevant data from other communities.
Stage 1: Provide Gitcoin with single place to get all interesting Gitcoin datasets in easy-to-consume format. We are already doing this, but we want to make the project better, easier to use and seen by more people!
Stage 2: Extend Gitcoin Data Portal to become Grants Data Portal holding up-to-date information about multiple Web3 Grant communities (Arbitrum, Optimism, Giveth etc.) in a single place!
 Technical Details
Technical Details
For a short overview on how the Gitcoin Grants Data Portal works, see the about-page. You can think of it as a lightweight data pipeline built using Dagster, dbt, and DuckDB, with additional module that allows us to publish website to Github pages and render Jupyer notebooks.
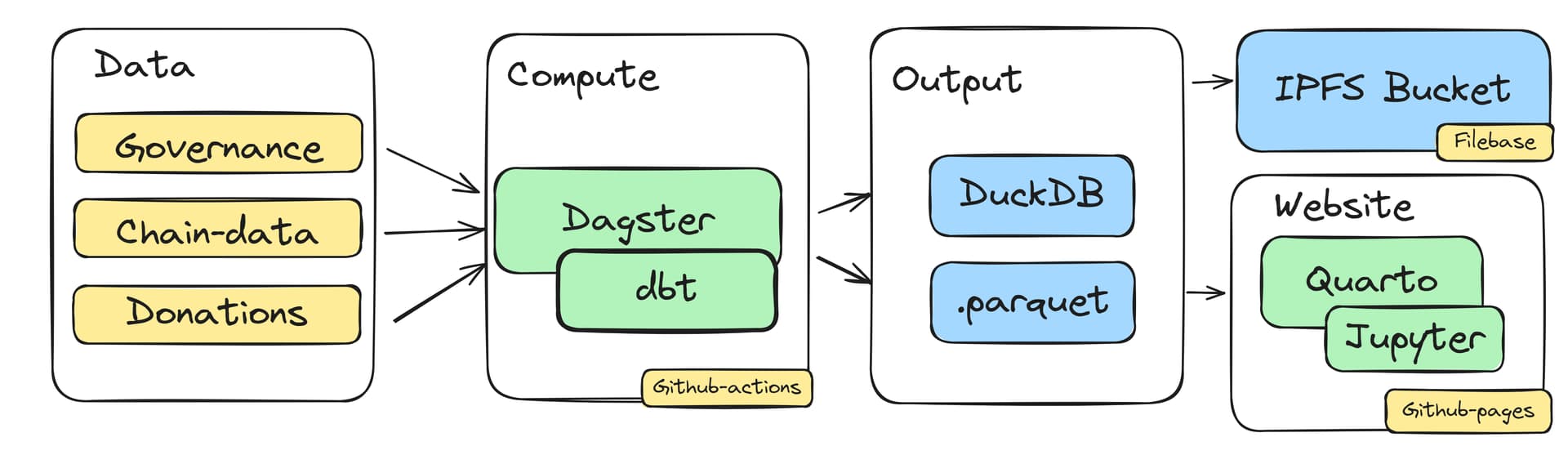
The pipeline fetches raw data from various sources, transforms it using dagster and dbt up and materializes the tables it into .parquet files which are then pushed to IPFS.
Example datasets for gitcoins include all Allo v1+v2 (donations, projects, rounds) as well as some more technical data taken from other sources (e.g. list of Allo Contract deployments or gas consumed by mainnet project registry)
The scope of the technical work is to design and build:
- Robust pipelines to ingest, clean and join new datasets
- Notebooks and models to analyze and curate existing datasets
- Multiple improvements on the DX side; CI, CD, Contributing Guides, …
- Tests to ensure data quality across datasets
 Roadmap
Roadmap
Stage 1
$8k, 2 months
- Better documentation
- improve overall documentation
- add contributor guides
- Better datasets
- evolve dbt models
- unify schemas
- add tests
- add new Gitcoin datasets to portal (e.g. Snapshot, Discourse stats)
- introduce basic support for
project profilesdata coming from other communities (e.g. Giveth, Drips, Octant)
- Better UX
- add Jupyter and Obervable notebooks as examples showing how to use portal data
- promote portal on X by publishing analysis, notebooks
- serve data in multiple formats to make it more accessible (e.g. checkout a spreadsheet via simple streamlit site)
Stage 2
$12k, 2 months
Extend scope of portal to serve multiple communities and become THE place to go to find open datasets about projects/donations in crypto-grants ecosystem. Gitcoin Data Portal => Grants Data Portal
- Add more non-gitcoin datasets to the portal (e.g. Octant, Giveth, Drips)
- Create shared tables by reconciling multiple schemas e.g.
all_project_profiles(Giveth + Gitcoin + RetroPGF) - In addition to
project profilestrackdonations datacoming from other communities (tricky - everyone has different way of doing that) - Experiment with various forms of serving data (e.g. S3 bucket)
Stretch goals we may implement, but it depends on collab with external actors:
- Transfer data to/from OS-Observer, RegenData.xyz
- Publish impact blog post(s) on OS-Observer
- Export (some) data to Dune/Flipside. [we can do this easily, just for some small datasets]
- if there is interest from LLM groups, serve tokenized text/embeddings in a format that can be easily consumed by NLP/LLM models (but we need to know which models)
 Budget & Milestones
Budget & Milestones
We ask for payments to be delivered in four monthly installments at end of each month. Expenses would cover development effort by @DistributedDoge and @davidgasquez. We will set aside some funds ($1000~) for maintenance and infrastructure costs (around $20/month currently for the IPFS pinning service).
| Month | Payout | Milestone |
|---|---|---|
| 1 | $4000 | Better pipeline |
| 2 | $4000 | Better UX |
| – | – | REVIEW |
| 3 | $6000 | More data |
| 4 | $6000 | Grants Data Portal |
Between milestones 2 and 3, we can review the state of the portal and evaluate the best way to continue with further funding.
Essential Intents & Benefits
In this combined section, we map each community intent to percieved benefits of funding this proposal. Some of those can be used as KPIs.
Community Engagement
- Make Gitcoin data easier to access and use.
- Attract new analysts interested in working with Gitcoin Data.
- Save time for existing analysts and developers in Gitcoin Community .
Network Effects
- Support other Citizen and Core initiatives.
- Support Gitcoin adjacent communities.
- Help Gitcoin identify high-potential grantees from other ecosystems.
- Help Gitcoin understand current market trends.
- Let community collaborate on curated models ala Dune Spellbok, but for Grants data.
Cost Efficiency
- Assume average analyst is paid 50$/h
- Assume portal turns 5 hour of data preparation and cleaning into 1 hour
- Saves 200$ per single use of portal
10 users ==> $2k savings
100 users ==> $20k saving
1000 users ==> $200k savings
On top of that:
- Community is incentivized to work on shared datasets instead of re-building the same data pipelines over and over for each project.
- Thanks to the project modularity other Python codebases can borrow our data-fetching pipelines
- The final curated datasets are available for free to anyone!
 Drawbacks
Drawbacks
Portal may publish incorrect data
Mitigating this by writing dbt models to ensure data quality + improving CI-pipelines. For Gitcoin we have RegenData.xyz to spot check our datasets for inconsistency. Exposing datasets to as many users as we can will also make them more resilient.
Portal may become more costly to run due to changes
One of the portal tenets is to be “lean” and “cheap”. At the moment we need no long-running server so the only cost for public version is $20/month Filebase subscription to publish data on IPFS. Running local stack on local machine (within Github codespace) will always stay completely free.
Portal may be hard to use
The only thing you need to use the portal is knowing which datasets will cover your needs and be able to read/use them. We are actively (1) talking to anyone interested in using Gitcoin data and (2) publishing datasets in open and standard formats to make sure things move in the right direction!
Developing (e.g: pipeline for a very large dataset) might become more complex in the future. At that point we’ll evaluate the best approach to keep things lean.
Portal won’t be maintained once funding runs out
At the end of the day, the portal is “just” a batch processing pipeline that generates some static files. That means that you press button, get the data and then forget it exists untill next time you need data. No long lived servers to maintain! If at a certain point the portal is not maintained and someone needs it, it’ll only need to clone and run it from their computer to get up to date datasets.
That said, some maintenance will be needed to deal with changing models and the natural evolution of APIs but we are already doing that with no funding for last 4 months so it is not that time consuming.
 Impact
Impact
List of collaborations using Gitcoin Data Portal or data coming from it:
- Providing data for OS-Observer impact-tracking research
- Growing OS-Observer grantee directory (~30% of Github projects imported using)
- Providing data for Grantee-clustering POC
- Providing data for Gitcoin-end-of-year visualization
- Sybil hunting in Citizens#2 round
- Arbitrum-led Open Data Community hackathon
Data Portal positions itself in a strategic place as smoothing access to quality and curated datasets can support many different iniatives in very cost-efficient manner.
 Conclusions
Conclusions
We are asking for $20k funding over the period of four months to improve the Gitcoin Grants Data Portal. Funding will be used in the development and iteration of existing data-platform. First stage of the proposal requires $8k over two months.
This proposal now enters community feedback period until end of the month, so we encourage everyone to share feedback here, or on the project Github! Thanks for reading. ![]()