The prioritization through impact and feasibility here is great. I think the entire community can help and that this is likely something the Open Data Community will be perfectly set up to execute!
I see the OODA loop your refer to involving the following pieces:
- Crafted experimentation using the Gitcoin Program - Based on business intelligence and understanding of optimal capital allocation
- Prioritized wish lists for DevRel to help get built - Based on business intelligence combining our highest impact levers and our program managers most pressing needs
- Simulation experimentation where funding mechanism code can basically be swapped from simulation to live round calculations with ease
I’m sure there are plenty of others. Exciting time to be building Supermodular on the Gitcoin ecosystem.
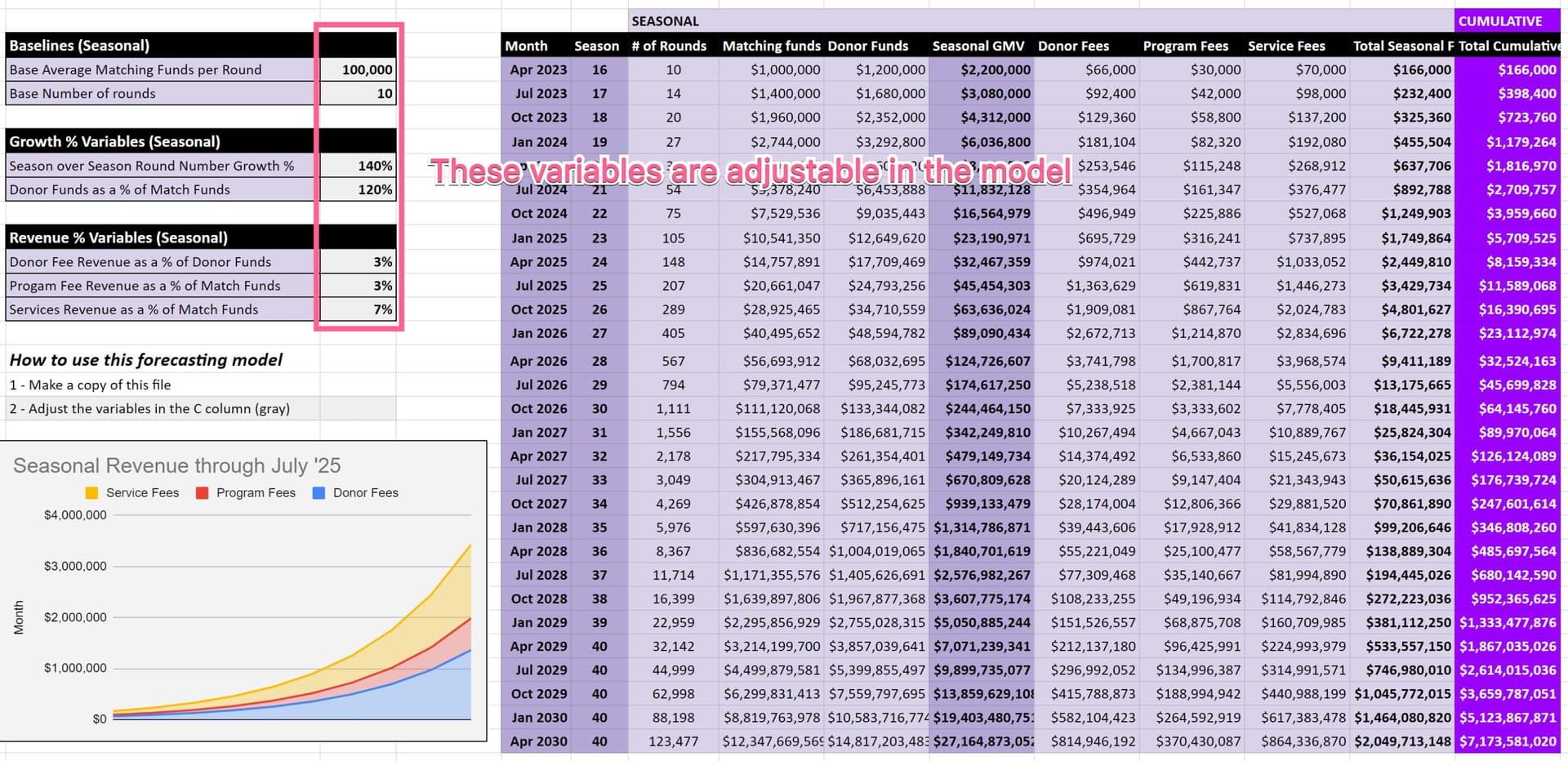
I also just posted this growth and revenue forecasting model.