Systematic Exploration of the Coordination Mechanism Design Space
Shrey Jain and Kevin Owocki
Gitcoin recently released Grants Stack, which is a set of modular tools that act as the scaffolding for any capital allocation construction. It acts as a structure to modularize all components of grants into standardized open-source modules for any DAO. It is with this modularity that any Grants module can slip-n-out of any Grants program without hurting the rest of the funding stack.
In traditional organizations, it is very challenging to replace governance mechanisms with new ones, even if the members that make up the organization desire a new tool. The modularity of governance mechanisms seen with the Gitcoin Grants stack enables iteration on such mechanisms that human coordination has never experienced.
With all of these new tools, a question remains, what combination of modules is right for our community?
Of course, Gitcoin is known for Quadratic Funding (specifically, pairwise Quadratic Funding), but what other coordination mechanisms could be built into Grants Stack.
This post aims at providing a pragmatic approach on how Gitcoin can run an experiment to better understand which mechanisms work for different types of communities.
Hyperparameter sweep on coordination mechanisms
In machine learning, a hyperparameter sweep is the process of training machine learning models with various different values of hyperparameters (learning rate, activation functions, training data size, etc.). For a given model, the calibration of one set of hyperparameters may work very well in one context but very poorly in another.
We want to apply this concept to figuring out what models of coordination mechanisms work best in a given community. There are many different types of mechanisms that can be used for resource allocation, some of which include: quadratic funding, MACI quadratic funding, cluster-wise quadratic funding, subscriptions, demurrage, dominant assurance contracts, ranked-choice voting, and much more.
Gitcoin founder Kevin Owocki and Giveth founder Griff Green recently did a podcast in which they discussed ~30 Coordination mechanisms [link]. The mechanisms listed in this podcast could serve as a backlog of mechanisms that could be built into Grants Stack.

A parameter sweep for coordination mechanisms would first require us to build all of the various different mechanisms that could be incorporated into an upcoming Grants round.
We could then run simulated rounds on each of these different combinations to see how capital is allocated and determine what mechanism is most optimal for a given setting.

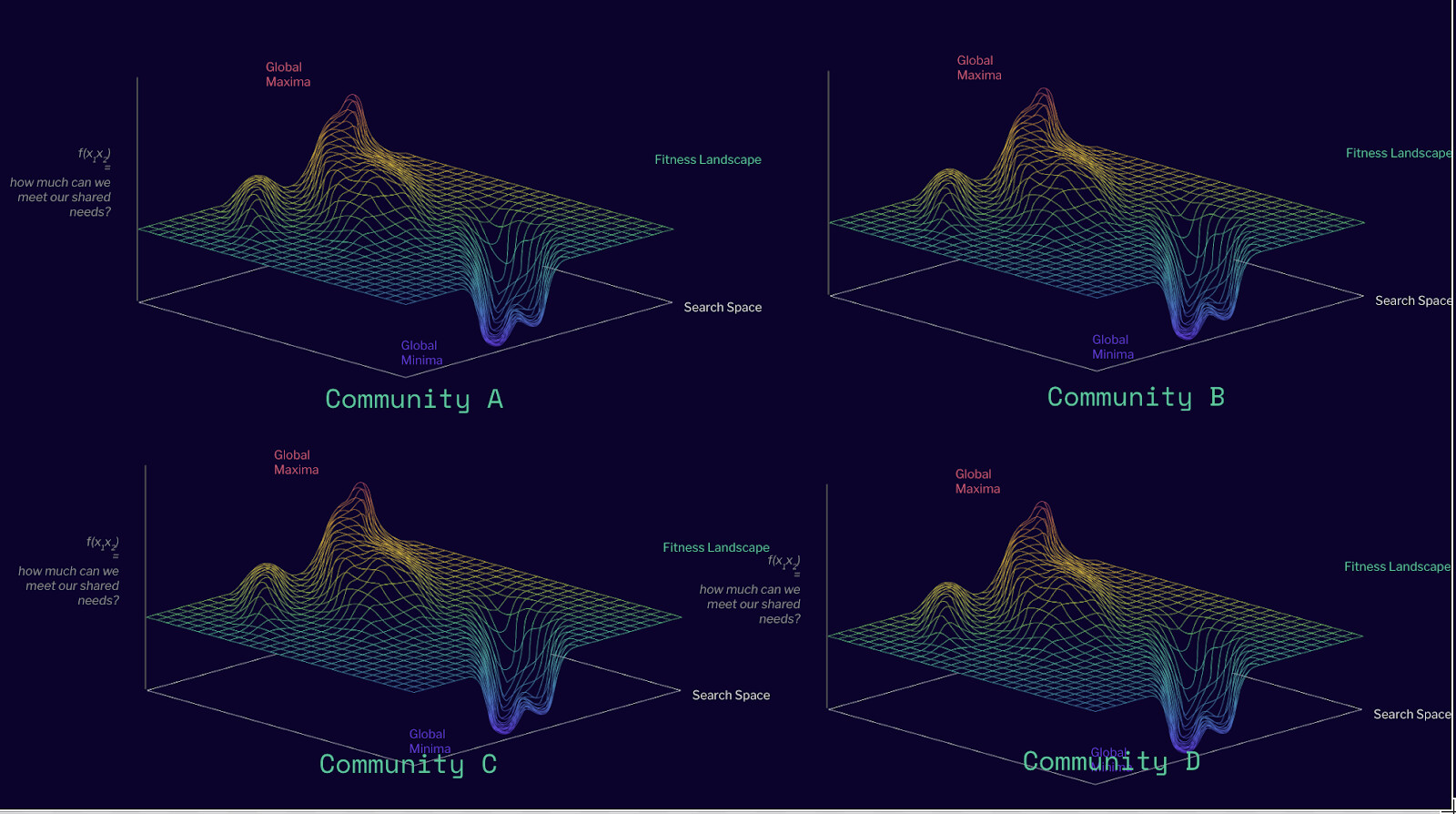
The creation of these simulated rounds and the testing of which ones meet the heuristic of funding our shared needs, is essentially exploring the fitness landscape within this search space.
Once the fitness landscape is mapped, we could then look for the global maxima of coordination mechanisms that help us meet the heuristic.
Of course, different communities will have different value sets so they will have different fitness landscapes. Part of the exploration of this design space will mean figuring out different types of communities and how they define their heuristics of what they want to fund.
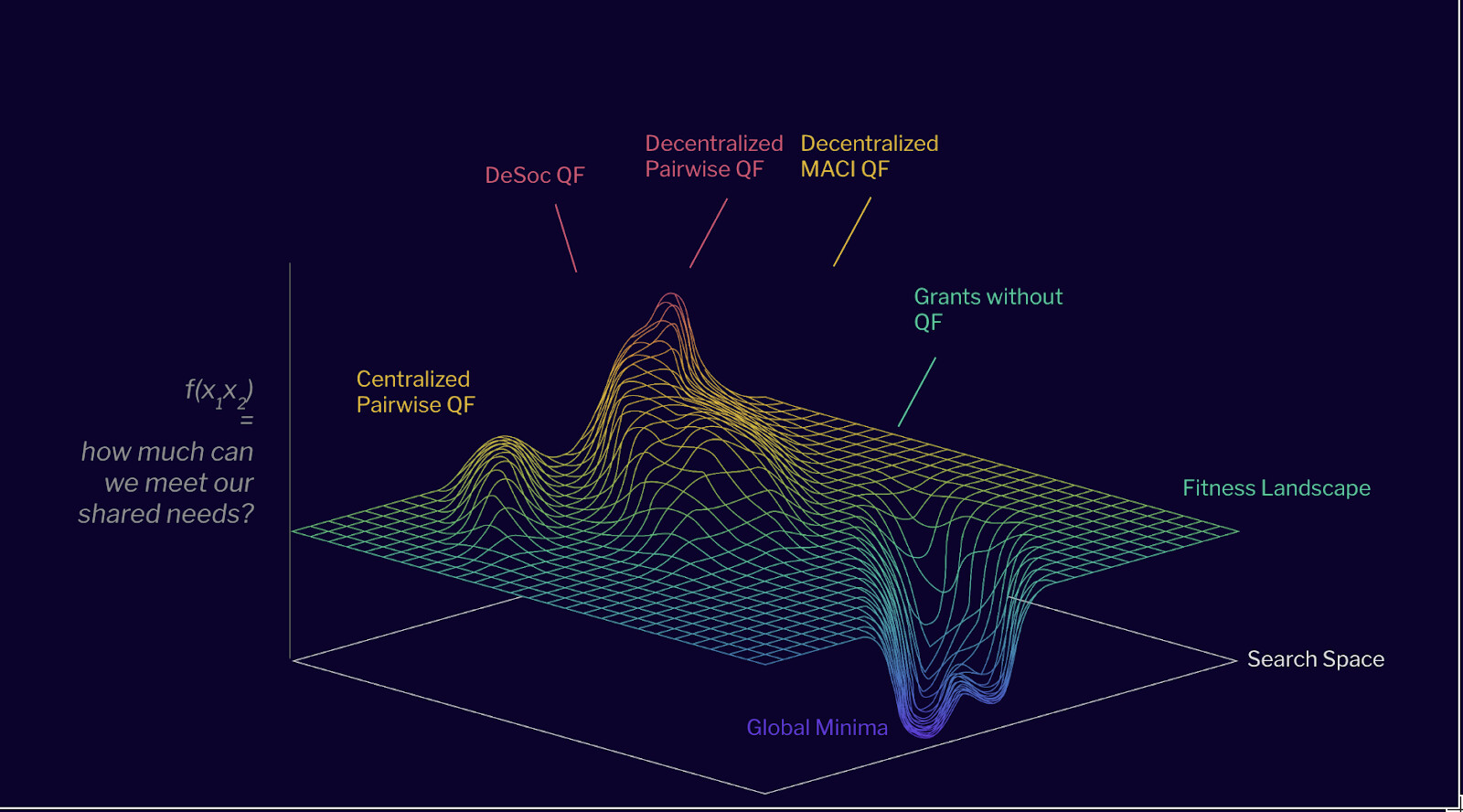
Right now, we know that the fitness landscape for the Ethereum ecosystem (Grants v1 explored this design space) looks kind of like this:
Future Work
If there is consensus that this is a direction of research that is worth exploring, then we recommend that
- GitcoinDAO create a prioritized backlog of coordination mechanisms to be built
- Gitcoin’s community of developers can build these coordination mechanisms
- Simulated Rounds will be run on top of these coordination mechanisms
- We will have started to traverse the design the design space of coordination mechanisms
- (Repeat 1-4 in an OODA loop until we’ve fully traversed the design space)
In addition to the process we outline to determine a given social spaces coordination global maxima, we can reference the many tools created by https://metagov.org/ and https://www.radicalxchange.org/ along with what we can expect to see from https://supermodular.xyz/.