This is a great post. I think the most under-rated metric for the Grant Stack UI is number of permutations of a Funding Stack available.
This slide still represents the functions where I see opportunities for experimentation and DevRel focus. Keeping the protocol unopinionated, but easily compatible with unique funding stacks should be a high priority.
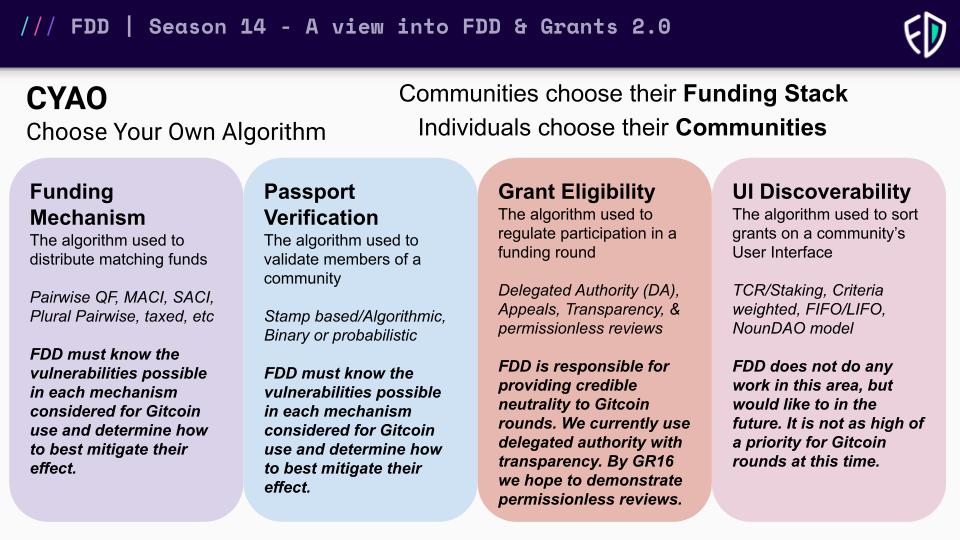
Each funding stack function has some tradeoffs. In experimentation, it will be important to recognize the consistency of the other functions. Simulation is a great way to do this.
Here are some of the tradeoffs I am aware of:
Funding Mechanism
- Taxation by fees vs Inflation
- DeSoc Incentivization of outgroup collaboration vs centralizing over time
- Sybil
User Moderation
- Universal (more errors, but economy of scale benefits) vs customized (pluralistic, but more costly)
- Gating & weighting (Creates systemic inequality which compounds over time) vs squelching (This is giving a 0 weight coefficient AFTER the vote is cast)
- Closed vs Open (Don’t let the attackers know your secrets vs Kerckoffs principle)
Grant Moderation
- Programmatic filtering on specific data points (universal) vs community scoring using aggregated data points (pluralist)
- Eligibility Reviews: Delegated authority (single point of failure, but cost efficient) vs intersubjective consensus (Like polis or ethelo). I HIGHLY believe that although delegated authority is more costly today, once a pluralistic review protocol is bootstrapped, it will provide minimum necessary decentralization for each community to trust the reviews at a lower cost per review.
- Crowdsourcing disputes and appeals: Incentivized (consistent, but likely to be gamed) vs UX driven (altruistic, but may not decentralize enough to be incorruptible)
- Appeals: Delegated authority vs decentralized and/or intersubjective consensus
- Eligibility Policy Evolution: Does the appeals judge use letter of the law and an appeal must change the law to overturn a decision that wasn’t an error in application of the law or a gray/novel interpretation? Or does the judge have freedom to judge the case as is and the legislation should consider legislative updates?
Grant & Round Discoverability
- Capital based decisions for social consensus based decisions