Correlations Analysis
We have further conducted correlations analysis and found relatively strong relationships between these variables:
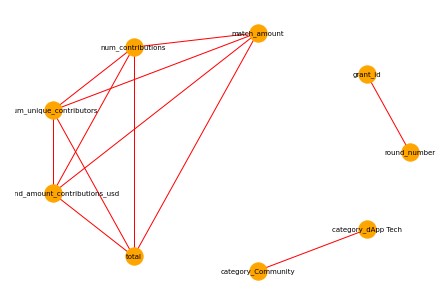
Interesting Findings:
There is negative low correlation between grant round and match_amount, meaning that as time passes the matching amount decreases
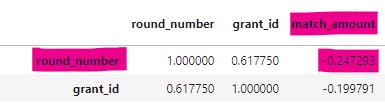
Also a similar relationship between grant_id and match_amount. Since new grants have higher number, the new grants are likely to get lower funding.
For the observation with region none there is a negative somewhat mild correlation -0.35 with the number of unique contributors. For this region it is also notable that it has negative correlation of -.27 with total funding raised. However, very similar region undefined has a positive correlation of .17 to total.
The structured heatmap for the variables is as follows:
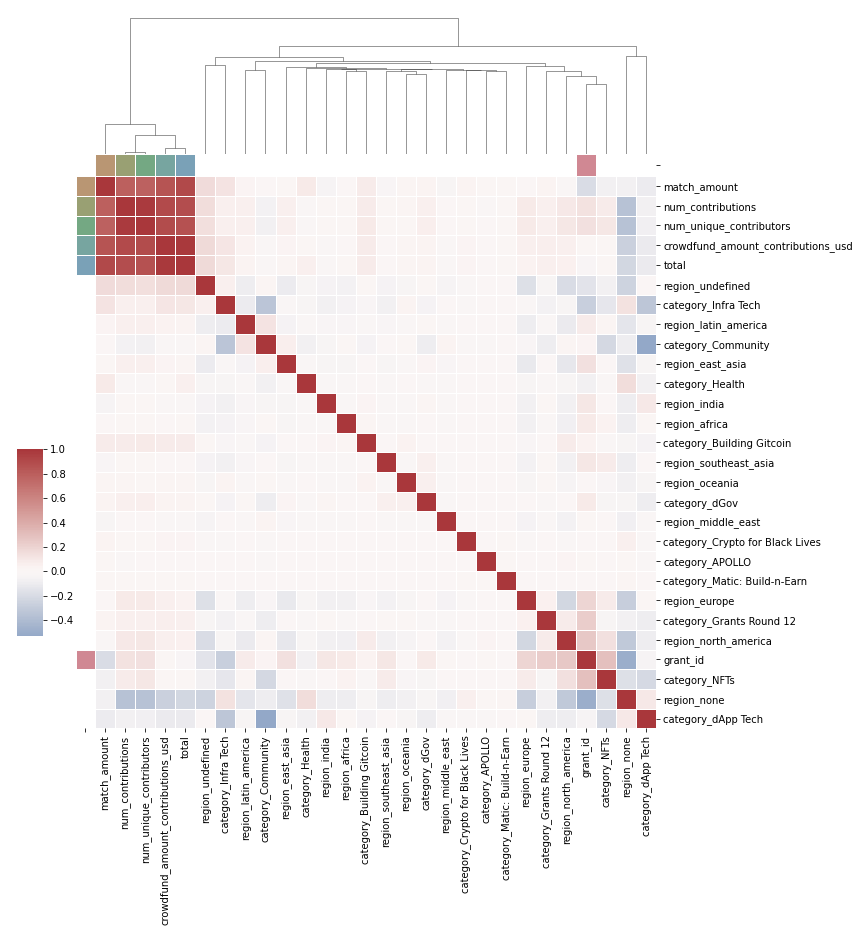
Modeling
We modeled grouped by round and weighted by count of unique grants. We found that on weighted average a mean contribution of 1$ per grant would result into $660 total funding per average grant.

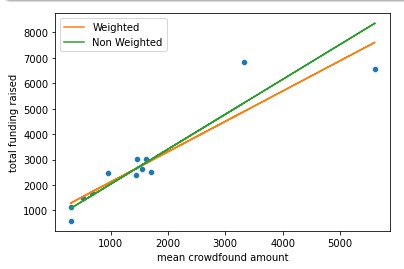
In turn, when we add another parameter - average number of unique contributors per round, we get coefficients and results that demonstrate the value of a large amount of unique contributors and the crowdsourced funds:
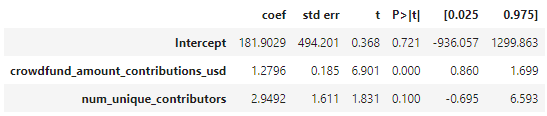
For instance, if only 1 person donates 1$ to each grant, the grant owners would get around 185$ per grant. But if 1000 people donate a sum that would be equal to .001$ to each available grant, an average total raised per grant would be around 3130$.
In round 12 there were 882 such grants, hence each of the 1000 would only need to spend 80 cents.
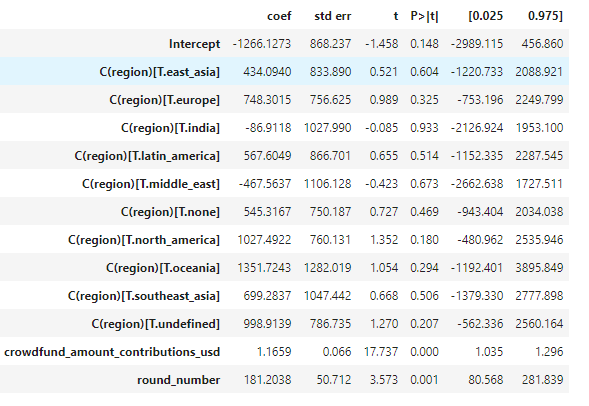
Next we group by region as well as round and weight by the number of unique grants.
Since we found that mean_crowdfund is highly significant we will include dummies for each region except one to avoid bias. In addition we include the number of grant round to estimate the effect of the trend.
We find that the most penalized region is Africa followed by Middle East.
Synthetic Controls
The effect of the separating Africa in GR11 as its own matching pool.
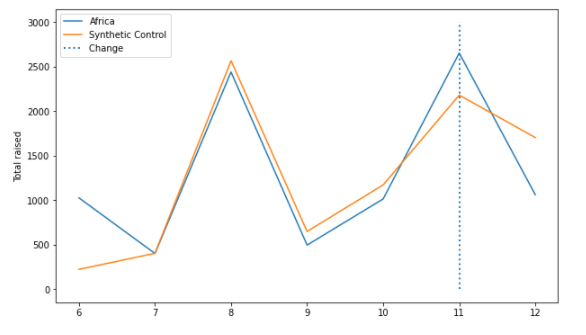
The initial effect of the policy seems to have an immediate positive impact on the Africa in GR 11, but a large negative effect in round 12.