Lifetime Gitcoin Grants Data Analysis and Hypothesis Testing
This report is a submission for the Gitcoin Bounty: BuidlBox - Now part of HackQuest.
Summary
A drastic increase in the Gitcoin Matching Pools in Round 12 has not been close to any of the rounds historically.
The Gitcoin Platform successfully catches opportunistic behaviour in changing grant to a larger matching pool.
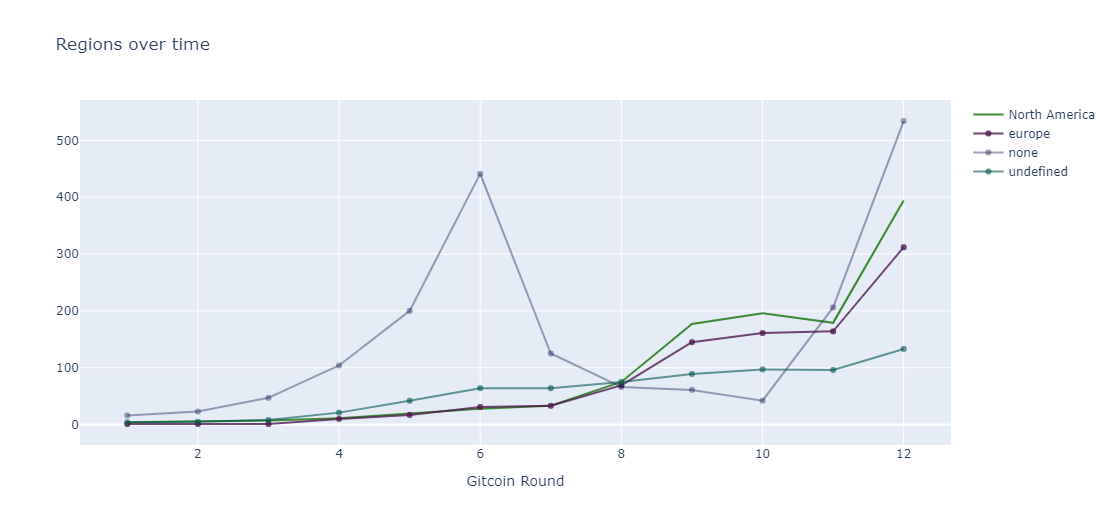
With the new matching pool strcuture in GR12 users have decided to not mention their region. North American grants have dominated the Gitcoin platform and Africa has been neglected.
On the technical side:
We have cleaned the dataset optimizing for the Gitcoin dataset and Gitcoin in particular. We have also provided an open-source code in Python that can be used for production.
Introduction
To understand how we can use the data to maximize its utility for the community at large and for decision makers in Gitcoin community, first we have researched the Gitcoin forum posts and the Quadratic Formula.
The posts for Reference:
- [Proposal] Gitcoin GR12 Matching Pool Allocations
- Grants Round 12 Governance Brief
- Gitcoin Round 11 Matching Pool Allocations 🤖 - #14 by makoto
- Sybil Report on Gitcoin Grants Rounds 12 - HackMD
Following these posts we outlined the areas of research that could be explored with the given data:
- The distribution patterns in the Gitcoin Grants data, for example, correlations between crowdsourced funding + matching to regions, grant category.
- The effect of changes in matching pools structure prior to GR12 and some insight into the changes that came up with GR12 one pool.
We also provide an account of the peculiarities of the given data such as missing values.
Structure of the report
First we provide an overview of the Gitcoin rounds data. Then, we deal with the technical side of working with data: filling in the missing values, correcting for artifacts and feature engineering.
The code is open-sourced and available on kaggle at
- EDA: GTC Bounty EDA | Kaggle
- Interactive Map: GTC_map | Kaggle
- Correlations and Modeling: GTC distribution + modeling | Kaggle
We have also uploaded the dataset on kaggle at GRallRounds | Kaggle
Data Cleaning and exploratory data analysis
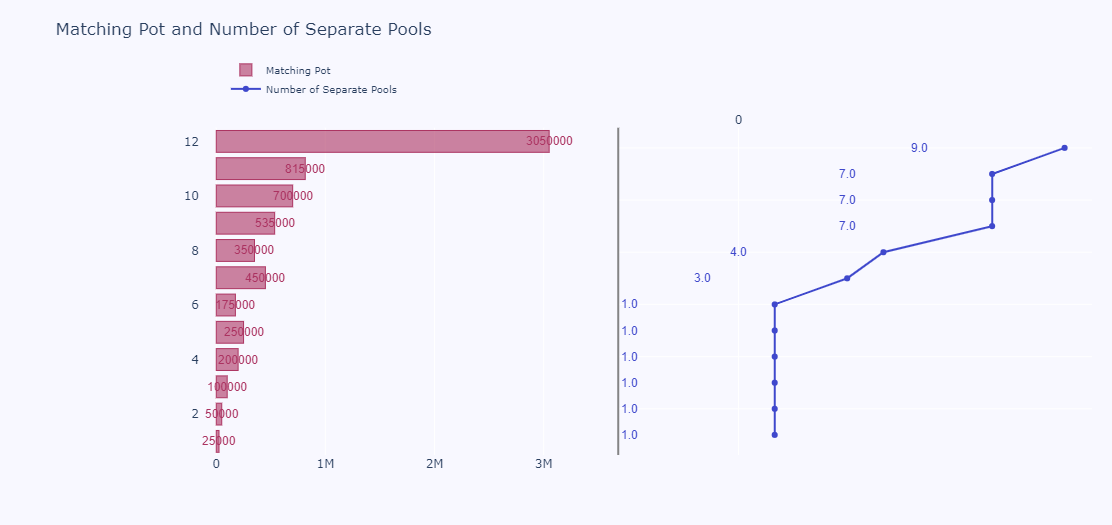
Rounds 1-12 Matching Pools and pot sizes
In the rounds data we have noticed that besides the official Gitcoin Rounds data includes the rounds data of its partners. Therefore, as the title of the bounty states 12 rounds we left only GR data and the partners rounds counted in the dataset as the GR.
GR data has the most common name of a matching pool in the data is ‘all’ since Gitcoin Core team (rounds 1-5) and later in consultation with the Funders League (rounds 6-9) has made more centralised decisions on the matching relative to the current state of governance.
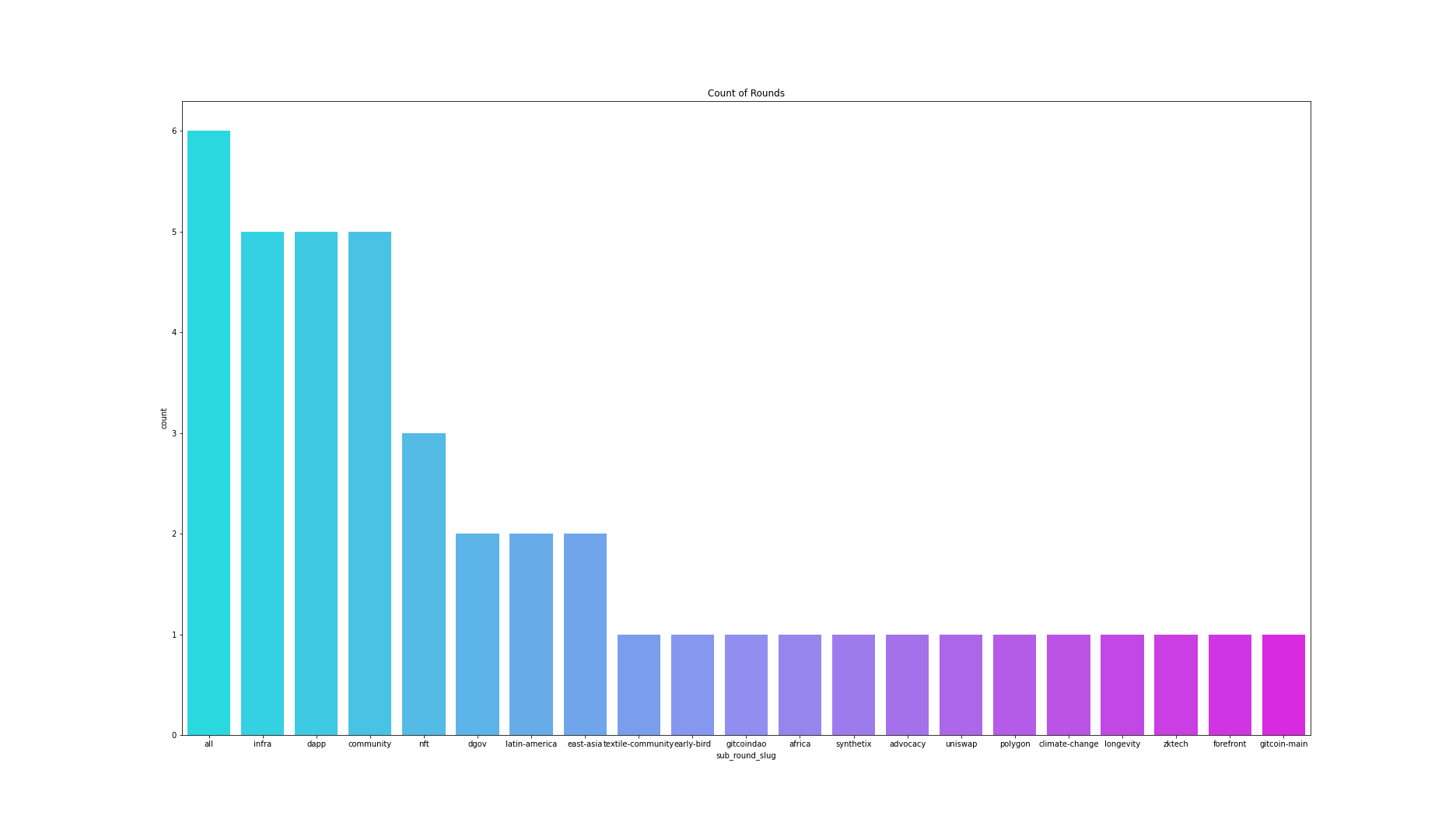
The second most common occurring round is Infra, Dapp and Community which took place from 7 to 11 round. Nft is the third most common value of the pot.
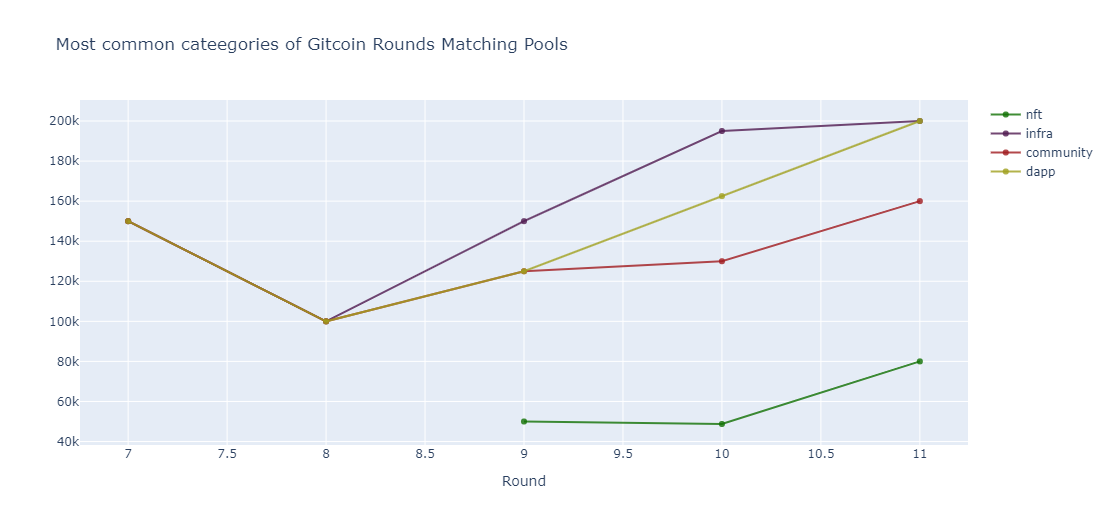
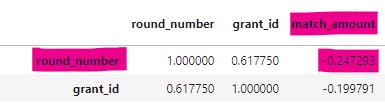
One of the notable developments in the round 12 was diffusion of the previous structure of matching pools and a trajectory towards one large single pool. Hence, on the graph above we do not see the common categories in round 12.
In the granular data we noticed that instead of the traditional matching pools that OG Gitcoin users likely got used to, the names have switched to “Uniswap”, “Polygon”, “ZkTech” among other names. To qualify for such pools the grants need to be in one of the 6 categories such as “dGov” or “dApp” and co-operate with the partner.
The new grant structure also introduced the new pools such as “Longevity” and “Climate Change” that have stricter qualifying requirements.
In total in round 12 this led to the historically largest amount of unique grant pools - 9. In part due to the amount of partners and available matching funds.
Rounds 1-12 Granular data missing values
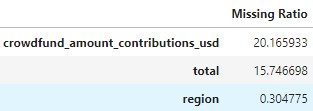
To begin with, we visualize the missing values to find interesting patterns:


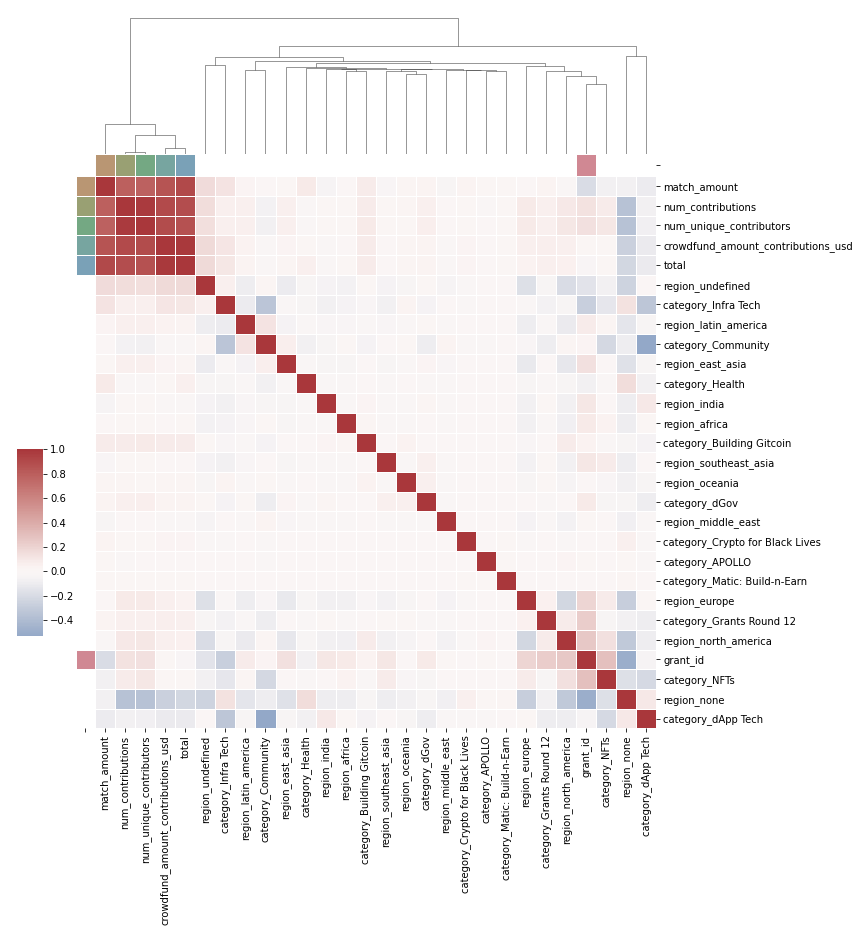
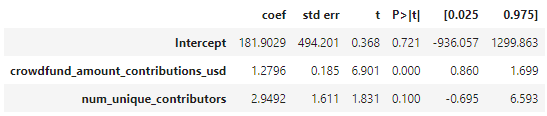
We can see that the column with the most missing values is crowdfund. On the more detailed analysis we find that rows with missing crowdfund values all contain zero unique contributors, which is very interesting. Some ideas on the underlying pattern: the owner of the grant contributing to the grant, error in data logging or a returning contributor.
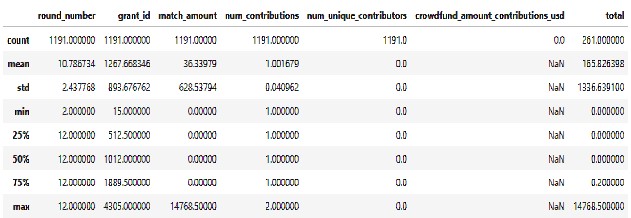
We also find that the rows that have nan for total have nan for crowdfund and therefore contain little useful information. In proportion its 15% of the total rows that we drop from the dataframe.
Exploring Gitcoin Detection of opportunistic behaviour
Next, it was particularly interesting to explore the patterns among the unique grants across time.
After we cleaned the data we found that the number of unique grants is 1886.
Personally, I was really interested in exploring the adaptation behaviour in changing the grant region and category and how often that has occurred per grant_id.
To my surprise less than 0.1% of the grants have been involved in such behaviour that we know from the data. Besides, most of actions that changed region involved actually mentioning the region for the first time.
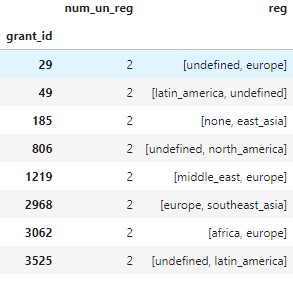
In turn, the grant_id is also connected to the same category across time and Gitcoin has successfully disabled such opportunistic behaviour.
Nevertheless, We decided to test the hypothesis that Gitcoin historically enables changing the grant details if the owner creates similar grant with new details. We assumed that the same grant title might be connected to the same grants. The number of such grants is 44.
On more detailed analysis we evaluated the changed details and it appeared to not be connected to the gaming the system since none of the detailed in the dataset were changed.
Therefore, we are confident that Gitcoin has historically caught opportunistic behaviour in adapting the same grant for more favourable matching pool.
Regions across time and Continent EDA
From the data, the most common region is none meaning that users in most of the cases decided not to mention the region out of the available options.
It is also interesting that none has coincided with the type of the round and whether there was a pool for a region. Notable that such grants received relatively low amount of matching funds, likely attributed to the Gitcoin penalizing this behaviour.
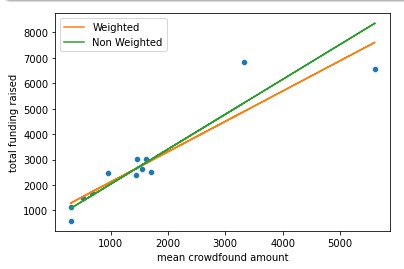
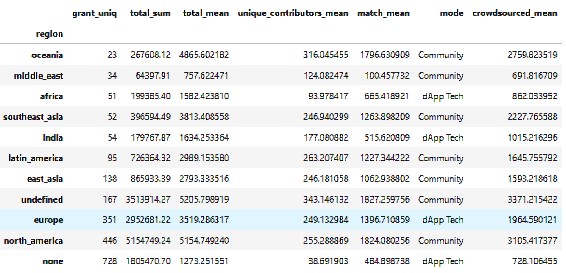
We also find that the mean total raised funding per grant per round favours Oceania and North America and neglects Africa and Asia to some extent.
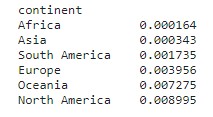
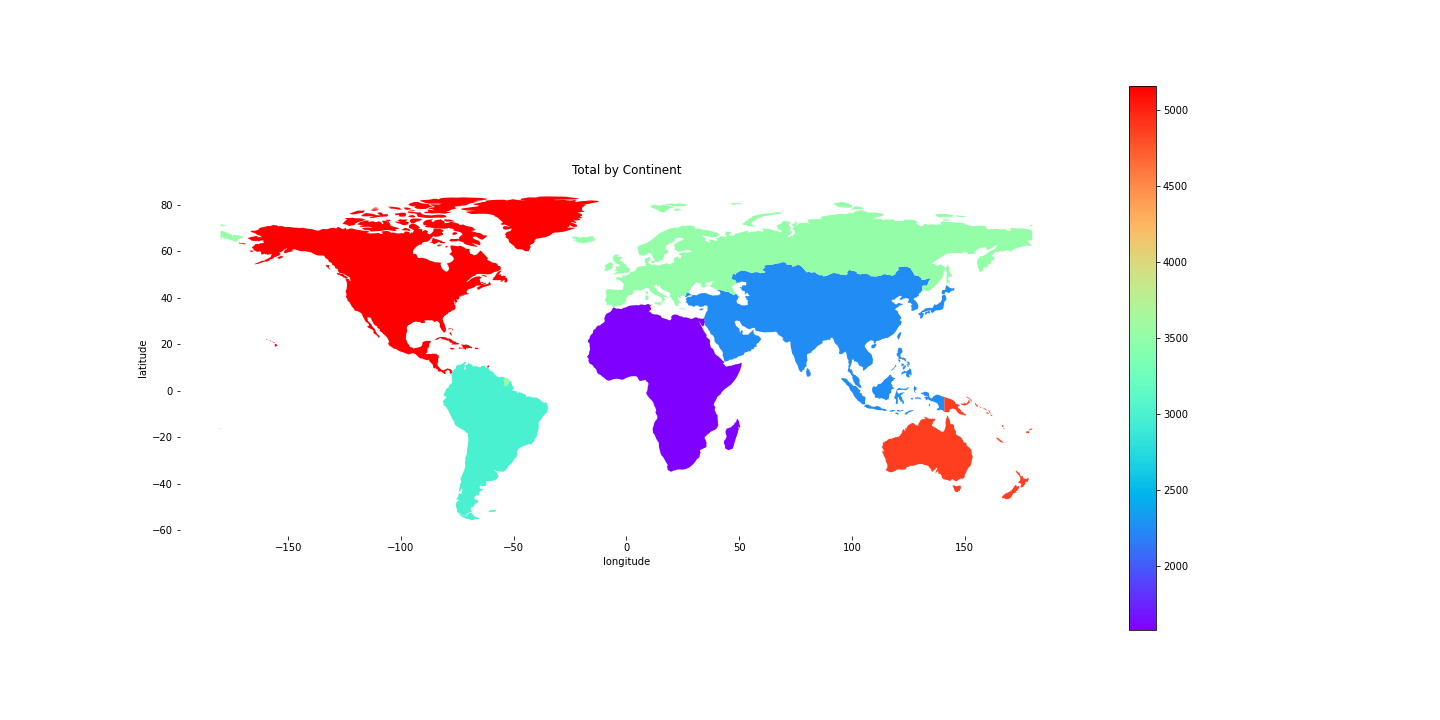
In fact, by capita NA is a strong favourite in terms of the raised funding.
We have also build an interactive map available at GTC_map | Kaggle
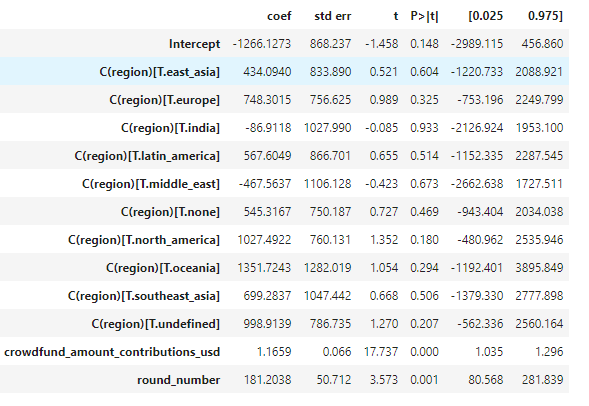
Moreover we explore the interaction between matching and the total for category and region variables for Round 11.
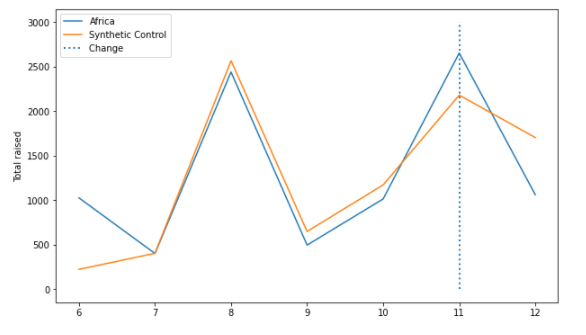
In Round 11 the over-subsidized region was Africa while under-subsidized was Middle East.

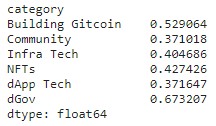
While for a category dGov was the most subsidized while dApp and Comms were not favoured by QF.