GR12 Governance Brief
Grants Round 12 presented new and old challenges including sybil attacks, collusion, and grant eligibility disputes. This post discusses how the Fraud Detection & Defense workstream (FDD) has worked to stay ahead in the red team versus blue team game. It also documents the decisions and reasons behind our subjective judgements. This workstream is tasked with minimizing the effect of these liabilities on the community.
Sybil Detection
FDD is responsible for detecting potential sybil accounts. We currently do this through a semi-supervised reinforcement machine learning algorithm run by BlockScience in addition to identity verification (trust bonus) and grant reviews.
During Q4, we made multiple advances including the overall system designs, the code for our ML algorithm, and devops/dataops improvements for the future. An overview of our vision for a community based sybil detection system can be found here. You can also watch our 1.5 hour event with Blockscience, Omnianalytics, Trueblocks, Kevin Owocki, and BrightID here.
The Blockscience algorithm runs and hosts the master ML algorithm used to sanction sybil accounts. The final run happens a few days after the round. The results are sent via csv to the Gitcoin Holdings team which then activates a heuristic to shut off the QF eligibility for the users determined sybil. (After GR11, the stewards voted to sanction the sybil accounts rather than paying the fraud tax. This norm will be followed until directed otherwise.)
In addition, their algorithm has been forked into the GitcoinDAO Github repo to be run by the DAO Devops team. We call this operational process the Anti-Sybil Operational Process (ASOP). This round, the DAO-initiated algorithm was only run in parallel to test our capacity to generate accurate results. Much of Blockscience’s work in Q4 was to ensure that proper documentation would enable the DAO to take over the running of the master ML pipeline.
Another big improvement was handled by Omnianalytics as the lead of the community effort. They developed a contributor data access framework including anonymization of data to allow more community members to participate in an open source feature engineering pipeline. The community run algorithm will be the data science playground where hypotheses are tested and can be added to the master when proven effective. They also began using on-chain data from Trueblocks to help identify sybil behavior.
For GR13, this stream will work to improve the contributor participation pipeline, improve the efficacy of the community algorithm, fully run the master pipeline, and work with other identity services for a framework to share data and results.
GR12 Sybil Incidence & Flagging
Blockscience Statistical Overview of GR12
Since GR11, the main performance metric for Sybil Detection is the Flagging Efficiency Estimate. This metric indicates how “efficient” the sybil detection process is for generating flags when compared to statistical estimates about how much sybil incidence we have for the round according to the human evaluators. Please note that some metrics are followed by a confidence interval in brackets, in keeping with statistical analysis practices.
GR12
- Estimated Sybil Incidence: 16.4% (between 14.5% and 18.3%)
- Number of Flagged Users: 8100 (27.9% of total)
- % of flags due to humans: 19.4%
- % of flags due to heuristics: 34.7%
- % of flags due to algorithms: 49.2%
- Total contributions flagged: 115k (21.7% of total)
- Estimated Flagging Per Incidence: 170% (between 118% and 249%)
GR11
- Estimated Sybil Incidence: 6.4% (between 3.6% and 9.3%)
- Number of Flagged Users: 853 (5.3% of total)
- % of flags due to humans: 46.1%
- % of flags due to heuristics 14.3%
- % of flags due to algorithms: 39.6%
- % of total contributions flagged: 29.3k (6.6% of total)
- Estimated Flagging Per Incidence: 83% (between 57% and 147%)
GR10
- Estimated Sybil Incidence: 36.2% (between 26.1% and 45.4%)
- note: this number is biased
- Number of Flagged Users: 1270 (8.9% of total)
- % of flags due to humans: 7.4%
- % of flags due to heuristics: N/A
- % of flags due to algorithms: N/A
- % of total contributions flagged: 31k (9.6% of total)
- Estimated Flagging Per Incidence: 25% (between 20% and 34%)
- note: this number is biased
GR09
- Estimated Sybil Incidence: N/A
- Number of Flagged Users: 1486 (11.6% of total)
- % of flags due to humans: 0%
- % of flags due to heuristics: 8.6%
- % of flags due to algorithms: 91.4%
- % of total contributions flagged: 16636 (9.4% of total)
- Estimated Flagging per Incidence: N/A
Compared to GR11, we had a large increase in detected sybil movements. According to human evaluation statistics, it has increased by a factor of 2.6x (between 1.6x and 5.0x). This was matched by a more than proportional response through flagged users, which seems to be “over efficient”. The interpretation of this is that the combo of using human evaluations, heuristics, squelches and algorithms is generating more flags than if we did flag the entire dataset of users using humans only.
GR12 Sybil Detection Details
Sybil Detection on GR12 depends on three fundamental inputs: survey answers as provided by the human evaluator squads, Blockscience provided heuristics, and a ML model that uses the previous two pieces in order to fill in “scores” of how likely an user is or is not sybil. With those pieces available, it is possible to compute an “aggregate score” that decides if a user is sybil or not. The distribution of those are in the following figure.
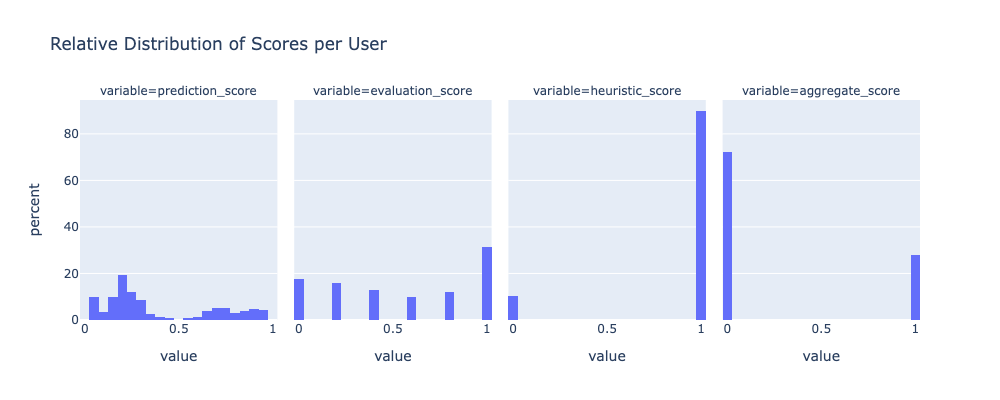
This aggregate score depends on a prioritization rule which works as follows:
- Has a user been evaluated by a human? If yes, and if his score is 1.0 (is_sybil = True & confidence = high), then flag it. If the score is 0 or 0.2, then do not flag.
- Else, has the user been evaluated by a heuristic? If yes, then simply use whenever score has been attributed
- For all remaining users, use the flag as evaluated by the ML prediction score.
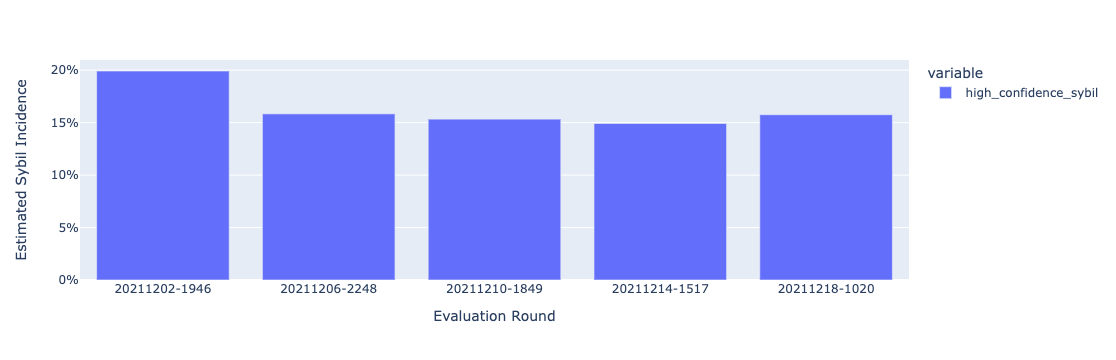
One highlight of GR12 is that this is the first time that we’re able to have a indirect proxy about how sybil incidence evolves during the round. We had 5 human evaluation rounds, and the estimated sybil incidence on each round is illustrated on the following figure. Notice that the incidence estimate on the beginning seems to be higher (almost 20%), and the it gets steady at around 15%.
Grant Eligibility
Grant eligibility is handled by a collaboration of multiple working groups. They review new grant applications and any grants which are flagged by the community. Feedback from the process feeds into the policy via an english common law method.
The highest court would be a steward vote, however, the role of the stewards is much more legislative than judicial. Disputed grants which end up needing an appeal will first be judged by an external panel of experts. We are also building a decentralized dispute resolution framework with Celeste. (It could use Kleros as well.)
Setting & Maintaining Policy
The policy squad exists to create and maintain policies affecting platform use and grant round participation. They set definitions based on reviewer feedback and advise on judgements for flags, disputes, appeals, and sanctions during the round.
The policy is held on a “living document” which can be found on our grants policy wiki.
Improving Grant Eligibility Response Time
The grant approvers hit their goal of a 24 hour or less average approval time during GR12. The workstream uses GTC to reward contributors for reviewing grants to ensure they meet the eligibility criteria.
Establishing the Grant Investigation Agency (GIA)
A new squad was put together to begin testing software models for reviewing grants. This round they spent one week of discovery looking into the criteria used to judge grant eligibility. They then used POAPs to incentivize 50 DAO contributors to review the GR12 grant disputes.
The Grant Eligibility reviewers still made the dispute determinations, however, this opportunity allowed us to test the outputs of the software against other stakeholder opinions. We now know that it had similar outputs from a more distributed model of reviewing. This knowledge will be used to help the review team screen new grant applications in the future.
Give the software a quick run through here!
Appeals
The policy squad developed a framework for a world-class fair appeals process which follows Ostrom’s principles for commons management. They are now working with the dGitcoin stream & developers from 1Hive to setup an instance of Celeste for the grant appeals process.
Grants Operations
FDD is dependent on the Gitcoin Holdings team for a few operational needs including some technical infrastructure, administrative access, and tagging of grants for inclusion in the thematic rounds.
GR12 Grant Eligibility Issues
While FDD has had full decision making control for grant eligibility since GR10, the backend of the current grants website is maintained by the Gitcoin Holdings team. This round a grant was taken down from the platform for violating ToS. The Gitcoin Holdings team made the decision to take it down due to the urgency of a unique situation, however, the FDD fully supports the decision and reasoning. In the future, we have committed to better communication when future situations arise. Read more here.
BrightID was flagged for having over $500k in funding and a token. We judged that per the norms set by the community, they are not eligible for the platform. However, we encourage them to appeal this decision. Our new appeals process is a better way of updating the eligibility policy rather than unilateral decision making by FDD which could be seen as favoritism or “moving the goalposts”.
The FDD Q1 Budget Request will include an “insurance fund” for wrongly denied grants which are vindicated through the appeals process.
Full transparency to the community is available for Grant Approvals, and Grant Disputes. User Actions & Reviews is currently in “open review” allowing for select participation to stewards due to sensitive Personal Identifiable Information (PII) data and potential vulnerability to counter-attacks.
When the stewards ratify the round results, they are also approving the sanctions adjudicated by the FDD workstream.
FDD Statement on GR12
The sybil attacks this round were extraordinary. They are evolving new and more complex tactics which require FDD’s best effort to defend. We are currently dependent on Gitcoin Holding’s engineering team to supply new sources of data outside of what we are whitelisted to access. We encourage them to make ALL data that isn’t legally protected available to the FDD workstream which will then apply our contributor access framework to allow us to innovate further and faster.
Disruption Joe, FDD Workstream Lead
