Background
Credible neutrality is necessary for a community to grow. Rawls has shown that participants are more likely to accept the outcomes of an election if they think the process is legitimate and fair. As we build the first digital democracies, how might we improve the legitimacy, credible neutrality, and sustainability of the new, internet-based, democratic systems?
This is a top-level, society-scale question that GitcoinDAO aims to tackle. Within that, grants are provided to projects that have positive externalities for the public (“public goods”). Traditionally, these grants have been managed as a monolithic group of applications, reviewed by humans. The upcoming Grants 2.0 will be modular, allowing anyone to host a round. This means that the round owners will need to take responsibility for curating the scope and eligibility requirements for their round. Some round-owners will self-curate, others will prefer to delegate this responsibility to the community. If successful, this system will create a “validator set” of grant reviewers which will lend any grant round credible neutrality in their grant curation process.
Communities which self-curate would eventually run into a scaling problem that they would need to solve. We intend to solve this problem in a way that generalizes to all round owners, regardless of whether they self-curate or community-curate. Communties that want their community to curate will be able to focus on sourcing the right criteria rather than execution details. The reviewer incentivization layer, if designed correctly, allows both these types of communities to scale in a credibly neutral way. This is the purpose of the Rewards team. They wish to optimize a generalizable incentive layer to maximize likelihood that a grant outcome is trustworthy, regardless of the size and scope of the round.
At the moment grants are reviewed by a small set of highly trusted individuals who have built knowledge and mutual trust through experience and discussion. However, with decentralization and permissionless as core values, the grant reviewing process needs to be expanded to more human reviewers. This process will require systems in place to ensure those human reviewers act honestly and skillfully. In the absense of such systems, we are vulnerable to thieves, saboteurs and well-intentioned incompetence. To defend against this, a well-designed incentivization scheme is needed to attract, train and retain trustworthy reviewers.
The optimal incentive model cheaply ensures reviews are completed honestly. The GIA Rewards team aims to devise as close to an optimal system as possible through ongoing research and development. This is one component of several, running in parallel with the overall aim of generating trustworthy grant outcomes. Correctly incentivizing reviewers is a route to increasing the trustworthiness of the humans reviewing grants - one critical part of the overall grant review process that also includes Sybil defense.
Incentivization can take many forms; it includes both financial and non-financial rewards. Optimizing the incentivization model means finding the right reward criteria, as well as the tempo, value and method of payment with the aim of maximizing trust and minimizing cost. However, a good system for Gitcoin DAO also maximises learning opportunities, communication efficacy and reviewer retention as positive externalities. There are requirements for onboarding and training new reviewers, track performance and determine trust, reward high performers and recognize low performers. In other words, even though emphasizing community aspects within the review process may cost more within a particular round, it is likely to increase efficiency by making sure the system is better prepared for the next round.
This is the challenge the Rewards team is addressing. To this end, the team has devised three relatively simple conceptual models. Simplicity is a feature in incentiviation models because simplicity promotes transparency. Transparency is required for participants to trust that the system is fair and equitable, which in turn influences whether they accept the system’s outcomes.
Incentivization models
3-Ps
The “3-Ps” model is a simple decision tree to determine how to incentivize participants in a grant review. This was part of the original thinking of the Rewards group, and it is implicit in the other models that emerged.
The 3-Ps are
- Person
-
- Position
-
- Performance.
These are suggested dimensions on which monetary incentives can be scaled. “Person” refers to an individual’s trustworthiness, which would have to be determined using some fixed set of metrics. These metrics could be, for example, accuracy in grant reviews relative to some highly trusted benchmarks. The point is that each person has an individual pay rate customized to their trust and ability level. An alternative factor is “position”, which refers to the official role that a reviewer may be assigned based on various factors. If the person is highly trusted they are paid more than someone who is less trusted, because their contribution to the overall trustworthiness of a grant outcome is assumed to be greater. “Performance” refers to an equal base pay rate for all reviewers that is modified over time as each reviewer proves themseves to be more or less performant (note that performance must be determined iteratively by comparing the number of grant decisions made “correctly” by a reviewer relative to some benchmarks, for example decisions made by highly trusted reviewers or consensus across multiple reviewers). As the conceptualization of the grant incentivization developed, the 3P’s became more of a component module to be incorporated in part or in full in more holistic incentivization schemes that consider not only monetary remuneration but also non-monetary rewards and maximization of positive externalities including learning and development opportunities and feedback.
The group has considered a few different approaches to the problem of how to produce grant decisions while meeting other objectives.
Baseline: Preprocessing the Reviewers
There are several routes to establishing an individual reviewer’s trust level. Before a reviewer begins work on the process, they should undergo training and pass an assessment such as an introductory quiz. A training set of grant proposals can also that includes ‘poison pills’ and ‘gold stars’, completely uncontroversial grants for which all capable reviewers would agree on the final income.
Established community members can be given high levels of trust at the outset. One purpose of the hierarchical model is to bootstrap trust, allowing trust to spread from more established reviewers to new reviewers. This requires that someone in the system be trusted at the outset.
Model 1: Hierarchy
The first model has a simple heirarchical structure where grants pass through successive layers of review. Effectively, a more junior Level 1 reviewer (less trusted) reviewer makes an initial evaluation of a each grant. This evaluation passes to a second, more experienced reviewer (more trusted).
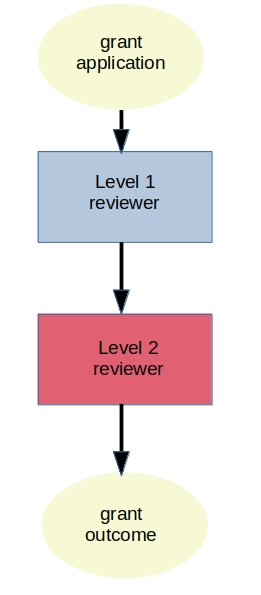
*Schematic of the heirarchical model, where a grant is first reviewed by a lower-trust reviewer, then by a higher-trust reviewer. *
This “review the review” process has several benefits:
-
the outcomes from the less trusted junior reviewers are reinforced by a second more experienced reviewer, enhancing overall trust in the grant evaluation
-
Feedback passed from level-2 back to level-1 stimulates learning, meaning level-1 reviewers can become level-2 reviewers more quickly, growing the pool of “high-trust” reviewers
-
The signal to noise ratio for the level-2 reviewers is improved because level-1 reviewers sift out the obviously invalid grants
-
There are opportunities to develop trust metrics by monitoring how many times level-1 reviewers agree with level-2 reviewers. Some benchmark trust score could elevate a reviewer from level-1 to level-2
-
The simple model topology allows for additional layers where more trust is needed (e.g. level-2 reviewers reviewed by level-3 reviewers)
-
The cost per grant is fixed and easy to calculate.
Cost of Hierarchical Model
c1+c1
cost = c1+c1
where c1 = cost for a level-1 reviewer, c2 = cost for a level-2 reviewer
The exact payments made to individual reviewers is an open question but could scale based on their trust score, their performance (N grant/unit time), and/or their position in the review heirarchy (level-1, level-2, etc.).
Trust of Hierarchical Model
The trust level of a model is the probability that the right decision is made. Since the higher level reviewer has final say, the trust is simply the trust level of the highest trust individual in the heirarchy.
trust = t2
Pool model
The pool model simply adds more reviewers to each grant and uses the majority vote to determine the grant outcome. Each reviewer’s review is weighted equally.
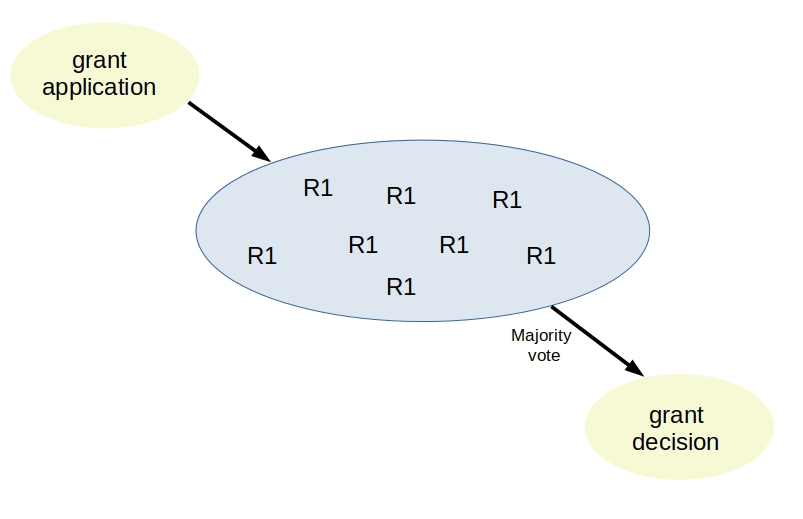
The cost to review each grant then scales linearly with the number of reviewers in the pool. In each layer:
cost = nc
where c = cost per reviewer, n = number of reviewers
Trust of the Model
Analysis of the trust of this model is more involved, but feasible.
In a 3-reviewer pool where the three reviewers have trust levels t1, t2 and t3 respectively, the trust level of the model would be
t1t2t3 + t1t2 (1-t3) +t1(1-t2)t3+(1-t1)t2t3This expression comes from applying basic probability rules and can be seen as
probability all three reviewers are correct +
probability only reviewer 1 and 2 are correct + etc
Hybrid Model
The hierarchical model and the pool model can be merged into a hybrid where pools are populated by reviewers across multiple levels and majority votes determine the grant outcome. Instead of individual level-1 and level-2 reviewers connecting on specific grants, reviewers in each level are pooled. Majority opinions from level-1 propagate forwards to level-2 where, again, a majority vote is used to determine the grant outcome.
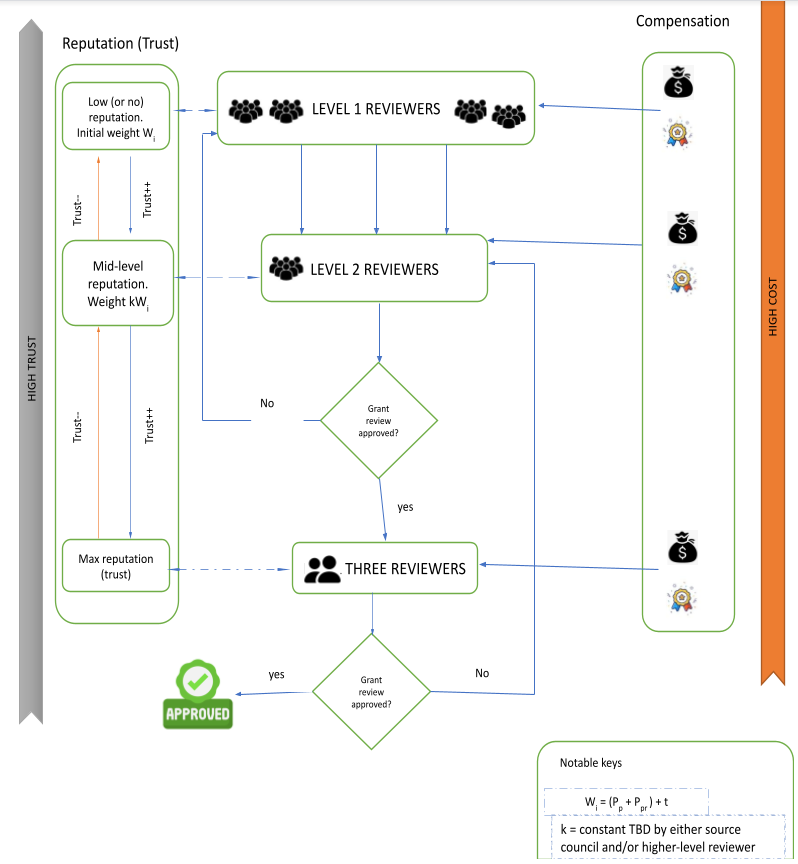
For a hybrid model, the cost in each layer is equal to:
cost = nc + NC
where n is the number of level-1 reviewers in the pool and N is the number of level-2 reviewers in the pool. However, the increased cost pays for additional trustworthiness in the grant outcome. Determining the optimal balance between cost (n, N, c, C) and trust requires the development of a mathematical model.
Random assignment
Randomly assigning grants to 2-4 reviewers who have level-1 or level-2 trust scores offers a situation where any of the hierarchical, pooled, or hybrid models might be used depending on the distribution of level-1 and level-2 reviewers in the reviewer pool. For example, for a randomly assigned three-reviewer pool with three levels of trust:
- [L1, L1, L1] → pool model
- [L1, L1, L2] → hybrid model
- [L1, L2, L3] → hierarchical model
It is also possible to end up with [L2, L2, L2] and [L3, L3, L3] pools but this is probably best avoided because this is not the most sensible way to distribute high trust reviewers across the pool - they are better spread across as many grants as possible and paired with lower-trust reviewers, both because their trust scores are not additive within a pool and because mixing them more evenly enhances mentoring opportunities for lower trust reviewers.
One of the significant advantages of this random assignment approach is that each of the hierarchical, pool and hybrid models will be implemented organically, leading to a dataset that can be interrogated to determine the relative benefits of each model empirically. Analysing this dataset will provide insights that can be used to refine the incentivization model in successive rounds.
Graduating trust levels
An important component of the review system is the ability of new reviewers to gain trust as they perform honestly and competently. This require a way to measure performance and also requires information to flow between levels, enabling learning and upskilling. It is assumed that performant level-1 reviewers would be in agreement with level-2 reviewers for the majority of their reviews. If this condition is met, they might increase their personal trust score and/or become candidates for graduation to level-2. At the same time, highly trusted reviewers might devise “gold stars” and “poison-pills”. These are synthetic grants specifically designed to appear excellent and highly fundable (gold stars) or problematic and unfundable (poison pills). Correctly identifying these dummy grants when they are mixed in with real ones gives an additional marker of trustworthiness that can be used to determine a reviewer’s level of trustworthiness. High-performing reviewers can be rewarded, low performers can be retrained.
Incentives
The models proposed above define the way that reviewers are assigned to grants but the type and magnitude of their incentives has not yet been explained. It is sensible that the monetary value of incentives increases in successive trust levels so that more trusted reviewers are more expensive. This encourages more even distribution of high-trust reviewers across the set of grants and provides aspirational incentives for lower-trust reviewers to become higher-trust reviewers. The right amount to pay per review in each level ($1 for level-1, $5 for level-2, $10 for level-3, for example) is something that will require some trial and error/ simulation to get right. It is not clear a priori the values that minimize cost and maximize trust.
There are also non-monetary incentives that can be used to reward reviewers. POAPs are not intended to have monetary value, but instead to be on-chain proof-of-performance and collectible items. They have value to users because they prove that an individual participated in some event with aptitude above some minimum threshold. This is desirable because it can be used to leverage other opportunities in the web3 world and also gives a sense of achievement, recognition, and community belonging. Experiences in other organizations suggest that, despite having no resale value, POAPs are highly desirable and effective as incentives.
Python Agent-based Model proposal
The models explained above are conceptual only, meaning they have been developed as thought experiments through multiple rounds of discussion and qualitative refinement, but have not yet been assessed quantitatively. This requires a model to be built that can simulate the actual dynamics of these systems as applied to simulated “environments” composed of a set of grant applications and reviewers with defined behaviours. These simulations are required to determine the optimal incentive model that maximizes trust and positive externalities while minimizing cost. We can explore this using an agent-based model. At the moment the team is sketching out the bare bones of an executable prototype for a simple agent-based model. Additional support is required to develop this into a full model that can reliably inform decision-making in the grant review process. Below is an outline of the current model development progress. It is built around three fundamental classes and some functions that operate on them. These are compiled into a pipeline that takes grant applications as inputs and returns grant decisions as outputs, collating intermediate data about individual reviewer actions into an external dataset along the way. Statistical analysis of the grant outcomes and the dataset will provide information about the effects of behaviours and incentivization on grant outcomes.
The prototype model will have classes representing:
Reviewer
A reviewer has the following attributes, all of which range from 0.0 to 1.0.
class Reviewer(trust_level, social_level,
ability_level, recognition_level,
engagement):
def __init__(self):
self.trust_level = trust_level
self.social_level = social_level
self.ability_level = ability_level
self.recognition_level = recognition_level
self.engagement = engagement
def make_decision(self, grant):
"""
some function operating on grant and reviewer attributes
and returning Boolean decision
"""
self.decision = 0+1 #placeholder
return
The reviewer has a single class method, make_decision which takes the reviewer’s attributes and the attributes of a specific grant and returns a Boolean (true/false) representing a decision on that grant. The reviewer attributes are all floats between 0 and 1.
Pool
A pool is an array containing multiple Reviewer instances, e.g.
class Pool(reviewers):
def __init__(self):
self.reviewers = reviewers
def aggregate_score(self):
"""
placeholder func that takes mean of reviewer scores
and returns it as aggregate.
"""
scores = []
for reviewer in reviewers:
scores.append(reviewer.decision)
self.aggregate = sum(scores)/scores.len()
return
# usage example
reviewer1 = Reviewer(0.3, 0.4, 0.1, 0.8, 0.5)
reviewer2 = Reviewer(0.6, 0.5, 0.6, 0.7, 0.5)
reviewer3 = Reviewer(0.3, 0.3, 0.4, 0.6, 0.6)
reviewers = [reviewer1, reviewer2, reviewer3]
pool = Pool(reviewers)
Pool.aggregate_score()
aggregate_score = pool.aggregate
Grant
A grant is a proposal about which a reviewer makes a decision as to whether it is legitimate or not.
class Grant(value, clarity, legitimacy):
def __init__(self):
self.value = value
self.clarity = clarity
self.legitimacy = legitimacy
Functions and Information flow
Discussion
A discussion occurs when a reviewer is unable to determine if a grant is legitimate.
Discussions can affect the reviewer’s ability and engagement. A productive discussion will increase them, a contentious or misleading discussion will lower them.
Pipeline
A pipeline is a connected set of reviewers and pools which produce a decision.
When we build a pipeline, we are giving an information flow structure for what reviewers make a decision for an individual grant, and for how those individual decisions ultimately lead to the system’s decision.
In addition to producing a final decision, a pipeline should also update individual reviewers’ statistics on the Scoreboard.
Scoreboard
A scoreboard keeps track of each individual reviewer’s statistics for the round, allowing the system to update between rounds. This can be a simple pandas dataframe that is appended to in each round. This gives more granularity about the behaviours of individual reviewers.
For each reviewer, the following data should be extracted:
- how many grants they reviewed
- how often they disagreed with their pool
- how often they disagreed with higher level reviewers
- how often they reached the correct decision
- how often they engaged in discussion
In the pandas dataframe each row is a reviewer and the columns track their performance for each round. (Note: a ND data structure such as NetCDF or xarray data-array might be better than a pandas dataset for this, so we can have dimensions for reviewer-ID, each individual metric and the grant round.)
Round
A round consists of a series of grants reviews.
In each round, the grants are assigned to a pipeline and final decisions are made.
Simulation
We decide in advance how many rounds will run, what pipeline structure we want to use, and what metrics we will track.
Process of Each Round
- Assign each grant to a pipeline
- The pipeline decides
- We track individual and system performance on the scoreboard
Between Rounds
New reviewers will enter and old reviewers may leave (if they are unhappy with the rewards)
New grants will enter
Speculation and Ideas
There have also been discussions amongst the group about including disincentives/trust-slashings in the models to discourage dishonest behaviour. These more speculative research avenues will be explored in more detail in the next season.
Summary
The Rewards group has explored several different models for incentivizing participants in the grant review process, aiming to maximize the trustworthiness of grant outcomes while minimizing the cost of each review. These models are, at present, conceptual. The team aims to build agent-based models in the upcoming season that will enable the team to transition from conceptual models to quantitative studies. The results from these studies can be used to update the existing Gitcoin grants incentive layer.
Authors: @vogue20033 (Biodun Festus-Ayorinde - bfa), J-Cook, Octopus, Adebola