GG24 Deep Funding Round Update
The GG24 Dev Tooling and Web3 Infra Round approved $350,000 for allocation via deep funding, with Devansh Mehta, Clement Lesaege, Allan Niemerg as round operators and Conor Svenson & Andrew B Coathup from the Dev Tools Guild assisting with jury mechanism & outreach.
This post is a status update alongside timelines for completion of the round.
TL;DR
-
Deep funding allocates money between projects by allowing model builders to predict how valuable each project would be if it were evaluated by expert judges
-
Model builders place trades on deep.seer.pm, with their profit and loss based on whether their predictions moved the market price closer (or further) away from manually collected data from evaluators
-
Anyone with an ENS name can become an open source evaluator at deepfundingjury.com, with an expert committee finally deciding which judgments are accepted
-
So far, we have collected approximately 500 evaluations from 50 evaluators, along with $1500 in trades placed by model builders. We need help from Gitcoin to increase both the number of trades made in the market and high quality evaluations on repos from open source developers.
-
The round will end upon conclusion of GG25, at which point evaluations are made public, traders in the market earn profit or loss, and allocations between repos based on its market value are finalized.
1. Context and Objectives
At a broad level, funding mechanisms are essential to movements like Ethereum, d/acc, or network states that need money to sustain over the long term but don’t necessarily want a centralized committee arbitrarily deciding who gets how much. More simply, similar to how citizens of a country generally accept the outcome of an election despite not liking who got elected, funding mechanisms seek to create processes by which members of a movement accept the ultimate funding allocation even if they don’t agree with the outcome.
Traditional grant committees create central points of control and are unfeasible if the number of applicants is large or if funds are to be distributed at a higher cadence.
So far, Quadratic voting
has been the primary funding mechanism deployed at Gitcoin (with metrics based funding being tried in GG23). It distributes money from a matching pool to competing projects without centralized control, based upon the breadth and intensity of support received by a project from a community. This mechanism has been utilised in multiple funding initiatives, recently the privacy round and Giveth dev tooling & infrastructure round in GG24.
In GG24, a total of $550,000 was allocated to Dev Tooling and Infra, with $200k through quadratic funding and the remaining to be allocated via a new mechanism: Deep Funding.
While there are benefits to relying on the wisdom of the crowds, it is widely felt that we need a credibly neutral funding mechanism leveraging expert insights from subject matter experts. Deep funding aims to fill this gap, with the current round being the first time it is used to distribute money. The table below highlights the differences between quadratic funding and deep funding
| Mechanism | Quadratic Funding | Deep Funding |
|---|---|---|
| Unit of Measurement | Community preference | Predicted expert judgment |
| Weights Determination | Donations (who gave how much) | Prices in Prediction Markets |
| Active Stakeholders | Projects: Seek Votes Community Contributors Support Good Projects | Traders: Build Models Predicting Evaluator Scores ; Evaluators Compare Projects with Good Reasoning |
| Incentives | Projects are incentivized to rally their community (or spoof them through sybil attacks) for receiving maximum funding Community Contributors have no incentive to pick good projects, they lose no money for wrong calls | Traders earn P&L based on how close they are to evaluator scores Evaluators currently have no incentive to submit judgments beyond social recognition Projects enjoy reading evaluator judgments on their work |
| Resiliency | Low; Sybil attacks by projects only carry reputational cost | Higher: Projects artificially inflating their worth is extra profit for traders |
| Network Effects | Low; Participation usually drops over time | Higher; evaluator datasets are valuable resource, model builder bots can be reused in future rounds |
| Sybil Friction | High; every voter must go through diligence | Low; Traders use actual money. Evaluators need only ENS |
| Overhead | Low; Some labor to increase community contributions which is offset by their addition to total funding in the round | High: Capital lockup for liquidity in the prediction market with impermanent loss; trading subsidies & prizes to attract model builders |
| Purpose | Discovery of New Projects, Early Stage without Proven Impact | Determining Relative Funding Amounts between Established Projects |
2. Trial Run
Deep funding draws on Vitalik Buterin’s idea of using AI as an engine and humans as the steering wheel. In practice, this involves humans providing limited but high-quality judgment, which are used to select or align AI systems that then scale to many decisions.
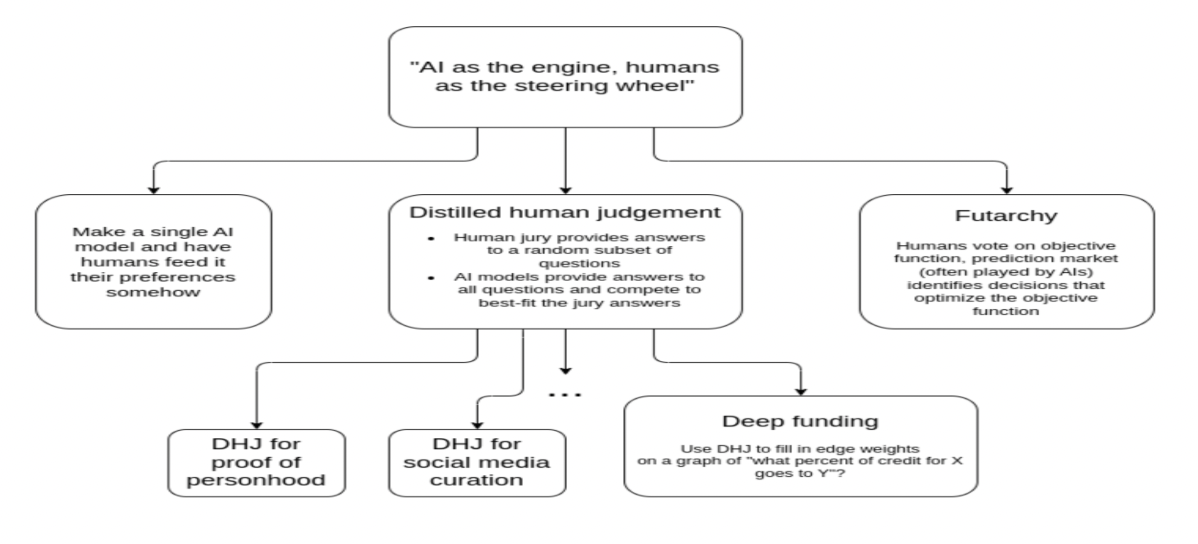
Late 2025 saw the first instantiation of this idea, with expert human judges making 700 detailed comparisons between 45 open source repos that were part of Argot Collective, Dev Tools Guild and Protocol Guild.
Using this data, two approaches were tested in parallel:
a. A machine learning competition (Kaggle-style) where model builders tried to minimize their error score compared to evaluations provided by experts.

30 entries were submitted in all, with the predictions from the winning model used to divide funds between these repos via Drips.

b. The 700 rows of human collected data was also used to resolve a prediction market where traders or model builders put over $10,000 behind their predictions on how judges would evaluate projects

Out of ten model builders given a subsidy to trade in the market, five earned a profit while three earned a minor loss. This is good news for creating a public goods funding mechanism where the community earns profit or loss based on accuracy of their judgment!

Armed with the insights from the trial run, the GG24 Deep Funding round is a hybrid where the winning model was used for round eligibility while the market derived weights determine allocations between repos.
3. GG24 Round design
a. Application & Eligibility
Even robust funding mechanisms like QF have centralized points of failure for eligibility or deciding who gets to participate in a funding round. We saw this create some issues in the past, for example the Zuzalu QF round had controversy over genuine pop-ups being excluded from the round.
For the first time in funding mechanism history, the process of deciding which project gets to participate in a funding round was primarily algorithmic or model-based! The eligibility process is as described below
-
The initial 44 repos part of the trial run were carried forward to this round with no checks
-
A new list of 201 open source repos, accessible here, were procured through an open call for applications wherein projects participating in the GG24 Quadratic Funding round could also share their repo for consideration in the deep funding round. Round operators also asked experts in the ecosystem on which repos matter to Ethereum and manually added them to the list.
-
The winning model from the deep funding trial run selected the top 80 repos from this 201. Repos that didn’t meet the GG24 criteria of a commit in the last 3 months and those self-describing themselves as an app and not infra were manually excluded, giving a list of 53 repos
-
The deep funding repo operating the round was manually added to the list, as an effort to be sustainable through the mechanism itself, giving a total set of 98 repos
-
The winning model was used once more to obtain base rates between all participating repos, thus kickstarting the market between them.
b. Allocation Mechanism
The current market weights between repos for GG24 can be seen at deep.seer.pm
The amount of funding each repo receives from the $350,000 allocated is based on the following 3 markets;
i. Seed Nodes
The market for seed nodes shows the top-level division between accepted repos in the GG24 deep funding round (R2L1). It is structured as a multiscalar prediction market where all weights must add up to 1. Currently, foundry and go-ethereum are in the lead with 3.3 and 3.1% respectively.
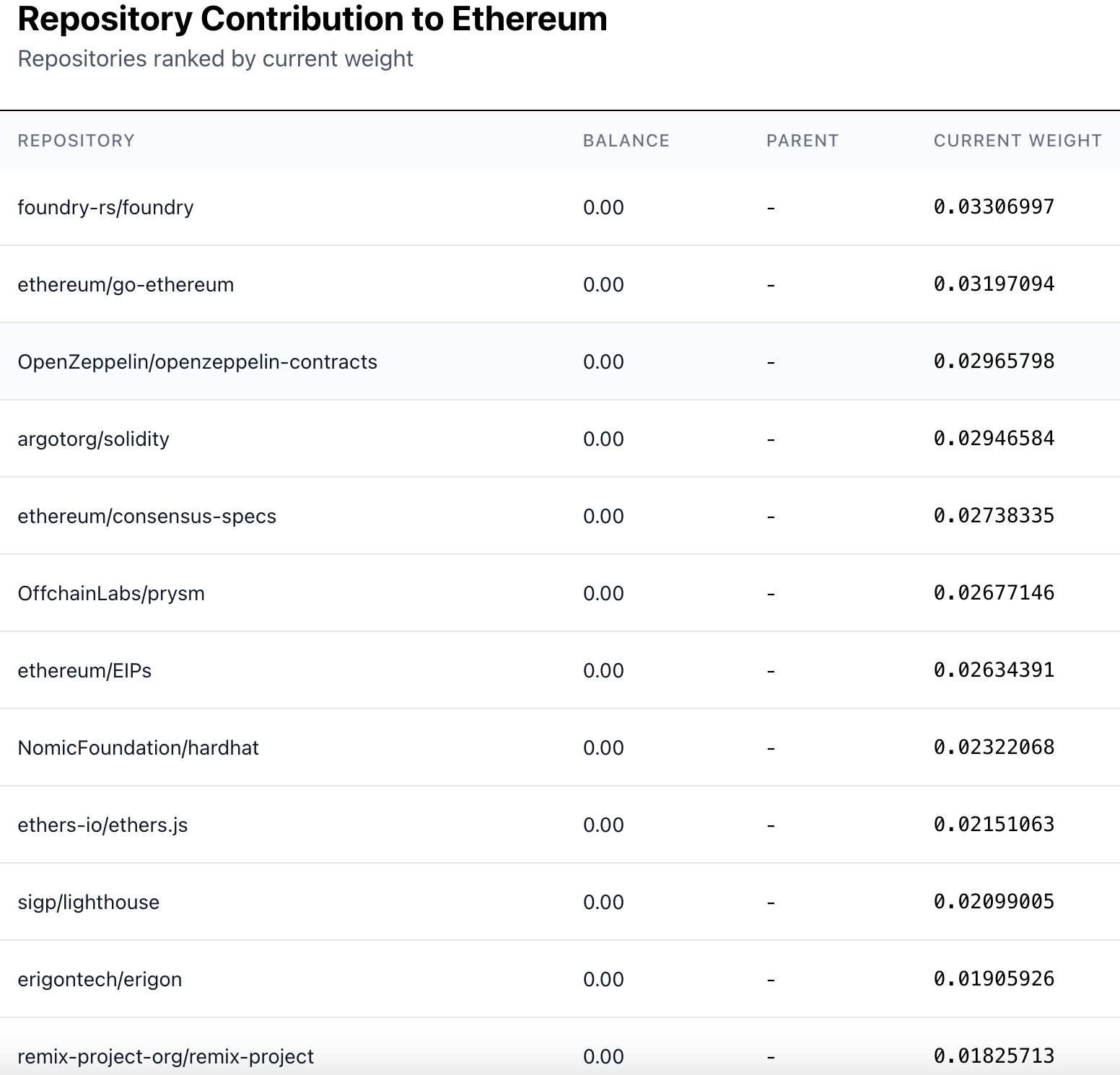
If traders think a particular repo is over or under-valued, they can take a position and influence the weights based on size of their trade, while earning a profit (or loss) upon market resolution. Attempts to game the system by participating projects actually make the mechanism more resilient, as it increases the profit margin for model builders and traders.
Participation guide here.
ii. Originality
Originality seeks to determine the share of funding that should remain with seed node repos vs passed on to its dependencies (child nodes). For example, a score of 0.8 implies that 80% of funds remain with the seed node while 20% is passed on to its child nodes.
Assessing originality is conducted via a simple scalar prediction market. Model builders place trades by either purchasing a seed nodes “UP” token implying a belief that it is more original than the market is assessing it at, or a “DOWN” token implying that its child nodes or dependencies deserve a greater share of credit than it is currently being assessed at. Together, UP and DOWN for each repo sum to ~1.
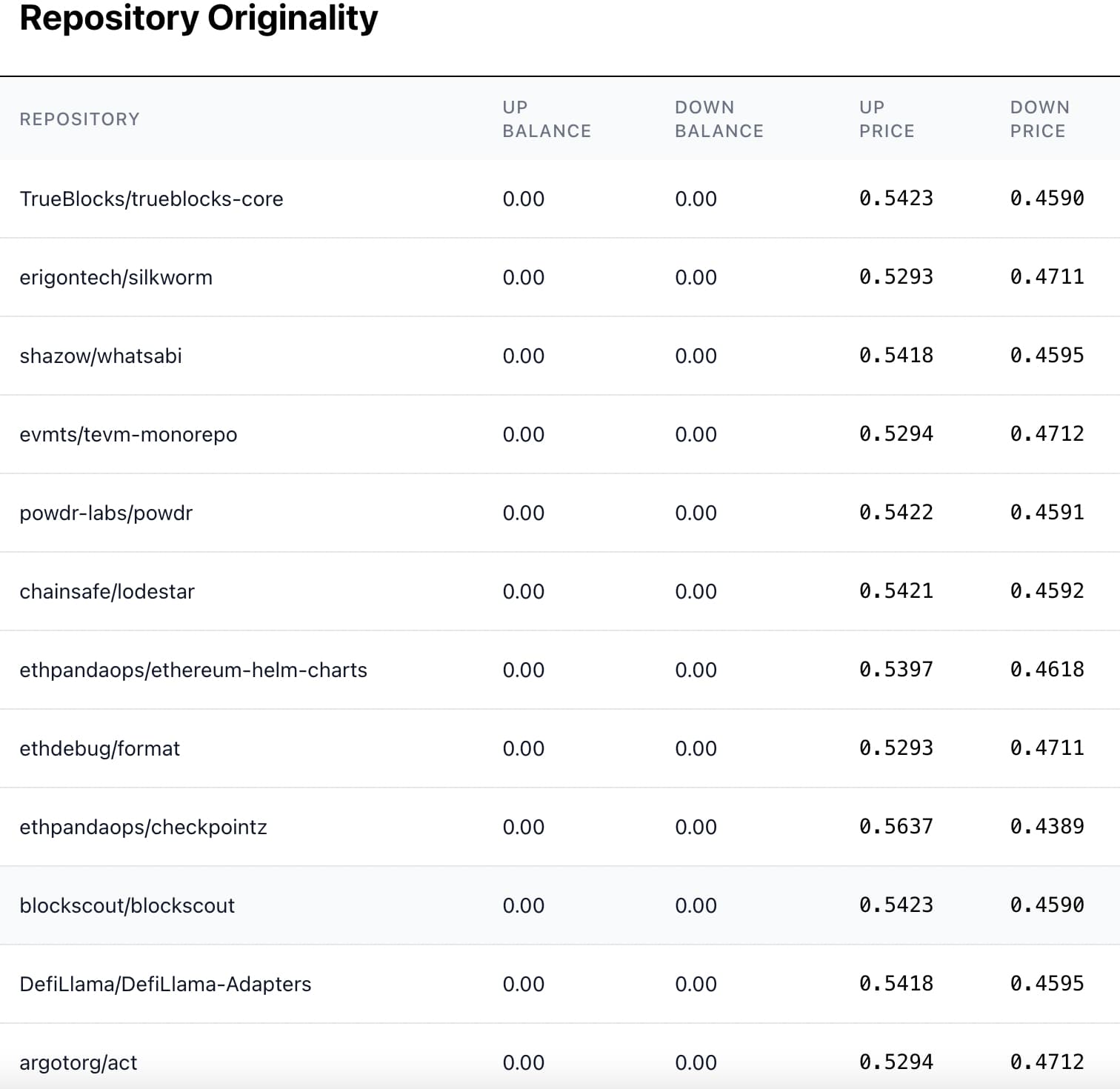
Any project trying to game the system by buying its UP token beyond what would be reasonably assessed by an evaluator is a profit opportunity for traders or model builders.
For example, let us suppose that a seed node buys its own UP token up to 100% to capture all funds and pass on 0 to dependencies. Upon resolution of this market, human evaluators judge the actual originality score as being 80%. The DOWN tokens now convert to 20c, giving a profit to those who bought it between 0 and 0.2; those who tried gaming the system suffer a loss from 0.8-1 as the UP token converts to only 80 cents.
Unlike quadratic funding where projects sybil attacking the mechanism only suffer a reputation loss if caught, in deep funding they suffer a monetary loss as their attempts to game the system become the profit margin for savvy traders and model builders.
iii. Child Nodes
Similar to the market for seed nodes, dividing money between dependencies of a repo is a multiscalar market where all weights should add up to 1.
The child nodes market for obtaining weights between all dependencies of a seed node is live (R2L2 on deep.seer.pm). The base rates were derived using an algorithm created by Allan Niemerg.
To tie up all 3 markets, let us now imagine that a seed node like go-ethereum has a weight of 0.1; it will therefore receive $35,000 or 10% of 350,000. However, its originality score was 80%; therefore $28,000 is kept by go-ethereum with the remaining $7000 shared between its dependencies according to weights in the child nodes market.
4. Metrics For Success aka How You Can Help
a. Voting App for Open Source Evaluators
While quadratic funding depends on the wisdom of the crowds, deep funding is based on scaling the judgment of experts. An essential (and expensive) part of the mechanism is collecting good judgments from experts that AI model builders are trying to approximate.
Currently, 50 judgments have been collected for originality, 200 for seed nodes and 240 for dependencies of seed nodes.
Call to Action: Allan Niemerg created the app for evaluators to submit their comparisons between seed nodes and gauge its originality score, accessible to anyone with an ENS name: deepfundingjury.com. The voting app for maintainers to rank their dependencies is still under development.
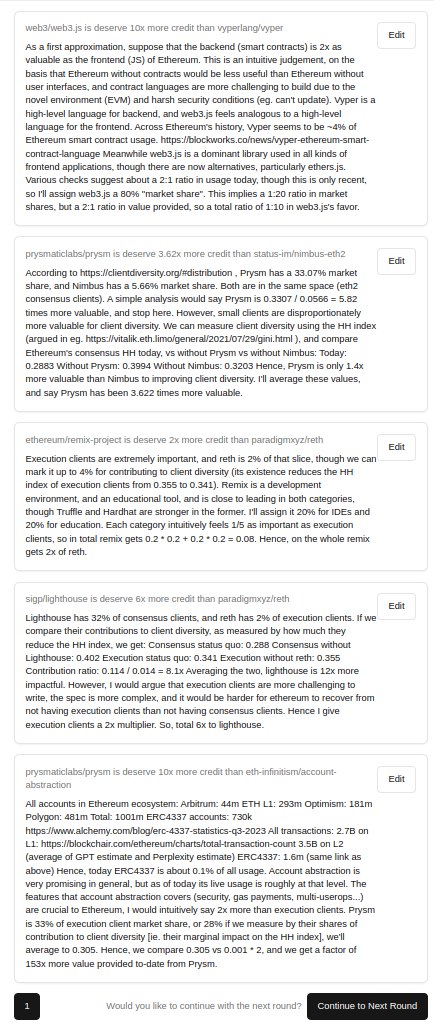
A total of 10 comparisons between seed nodes and 3 judgments on originality are required per evaluator, who can take anywhere from 2-20 minutes per question. Quality is more important than quantity - so even a few with well written explanations are worth more than many without a rationale. Examples from a top evaluator is below, dataset of 600 comparisons from trial run here
Metrics:
- Number of evaluations
- Number of evaluators
b. Meta Juror Committee
Not all judgments are auto-accepted; a meta committee looks at individual comparisons and selects only the ones with strong rationales for use in market resolution upon completion of the round.
Call to Action: As a stopgap measure, the meta jury is composed of Andrew Coathup, Conor Svenson and Devansh Mehta, with new additions possible by a 2 out of 3 vote. Any comments in the forum for proper design of the meta jury (which holds significant power) is welcome.
Metrics:
- % of evaluations submitted vs those accepted by the committee
c. AI Developer Outreach
Weights only become accurate if there are AI model builders participating in deep funding markets and making trades. Accordingly, Seer is providing trading credits to those who perform well in the market, with an agreement to let them keep profit earned and if in loss, then only to return what is left.
To identify and recruit good model builders whom we can give trading subsidies to, a Pond ML contest will be set up where model builders can see how they perform before wagering money in the prediction market. The OpEx of $25,000 from Gitcoin will go to Pond for holding this contest.
Call to Action: Build a model for trading in the deep funding markets and taking part in the ML competition; post a writeup on Gitcoin’s forum detailing the technique used.
Metrics:
-
Number of wallets participating in the Seer market
-
Amount handed out in trading subsidy for model builders to participate
-
Total amount wagered in these markets relative to liquidity injected into them
-
Number of valid entries to the pond contest, as judged by write-ups from model builders on Gitcoin’s forum
Any feedback, comments or interest in using deep funding for other domains in GG25 is welcome. Now that the basic infrastructure is in place for deep funding, along with a completed trial run, helping new ecosystems run their own deep funding instance would help with horizontal scaling of the mechanism to more accurately allocate money within an open source network.
5. Parting Remarks aka the Future of Deep Funding
Having fully documented deep funding, this section will try answering a simple question: what should we build next or have in place for future iterations of this mechanism?
To summarize, the section lists 5 features (in order of build priority) around tackling the eligibility question or how we cap projects to ~128, new liquidity methods for deep funding markets, creating a moat by having model builders submit bots (instead of CSV uploads) that can be triggered for any round in the future, use of funds by repos after receiving them and finally how to best collect human judgment for resolving these markets.
a. Eligibility for Participation: We are happy to see deep funding has power law dynamics in public goods funding, where the top performer gets ~100x more than the bottom one. This is a good thing! Public goods likely have the same dynamic as private goods where a few projects deliver the majority of the impact.
However, this begs an important question: How many projects or repos should take part in a deep funding round and under what method do we accept or reject projects from taking part?
Assuming Zipf’s law, the top and bottom project differ by a factor of ~128. Accordingly, we suggest capping the total number of projects in a round to 128. The current round has ~100 repos; if GG25 has a deep funding round, the unanswered design question is the process for accepting an additional 28-30 projects.
One proposal under consideration is asking projects that want to participate to post a bond (unisocks auction style) that increases toward infinity the more nominations there are. If assessed at a low value by the market, this bond may be slashed. So anyone proposing to add a new edge to the graph must get a weight at least greater than number 128 to replace them in the mechanism.
Ideally, we test this unisocks auction eligibility mechanism in GG25 for addition of 28 new repos.
b. Liquidity in Public Goods Markets: The trial run in deep funding used ~$44k in liquidity, of which ~$38k was returned at the end of the round. The $6k can be considered as the cost to obtain information, under the assumption that the market converges to human scores more accurately than the base rates you started it with.
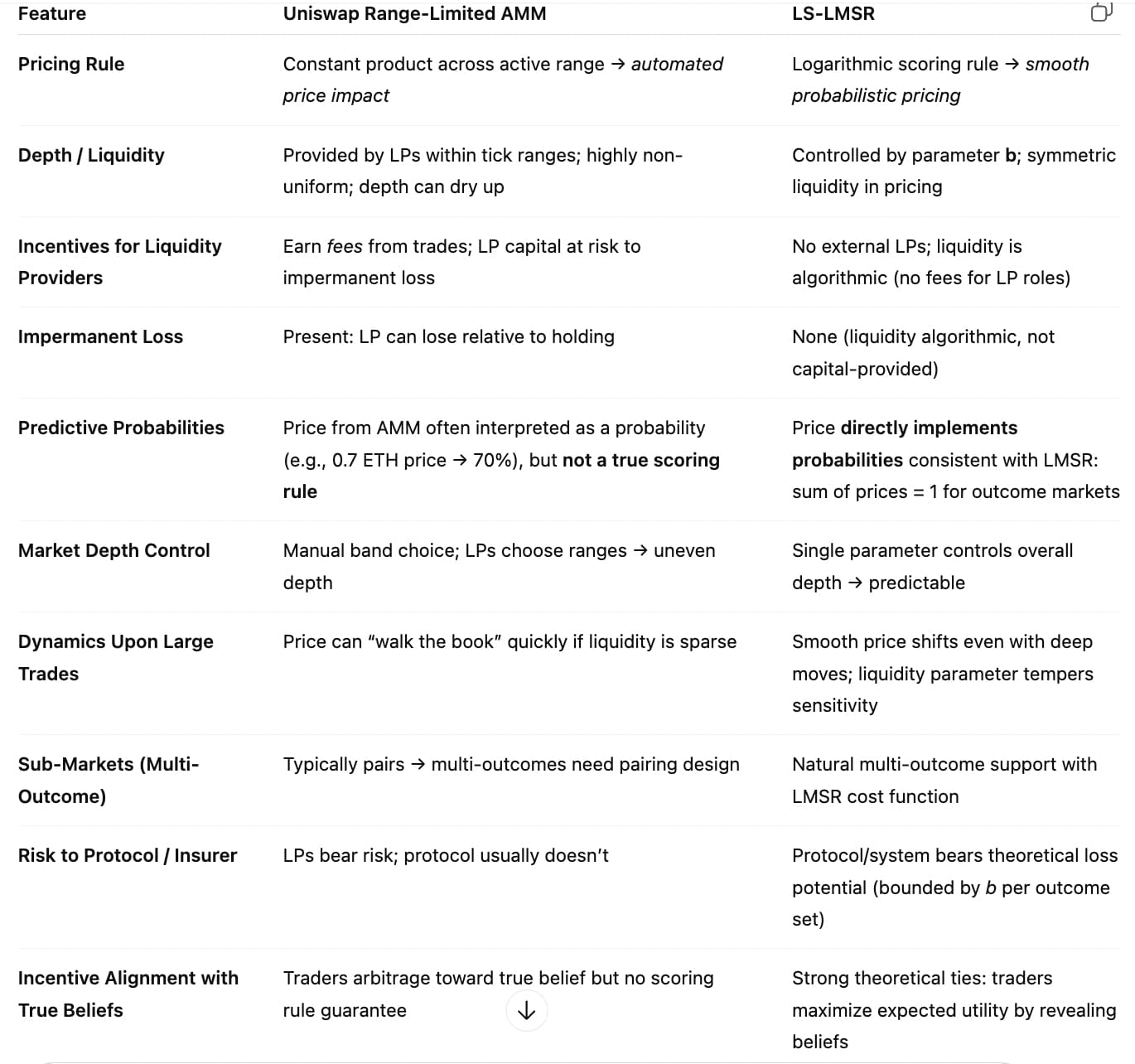
The main issue is under the current method (a version of uniswaps range limited AMM), the amount in liquidity has an undue influence on the final weights projects receive in the market: put too much, and prices don’t change. Put too little, and prices swing wildly.
Ideally, the ultimate weights should not be based on how much liquidity was put into the market. Exploring alternative liquidity schemas for this market, such as Liquidity Sensitive Logarithmic Market Scoring Rule (LS-LMSR), should be an area of active exploration. While Gnosis has a version of LMSR, no canonical LS-LMSR open source implementation currently exists. A brief conversation with GPT around liquidity provided this table that provides some insights on the relation between accurate weights for projects and liquidity method
c. Deep Funding Bots: Currently, model builders run their AI to obtain weights between repos and submit a CSV. This prevents reusability; for example, in GG23’s predictive funding challenge, if model builders submitted bots instead of CSVs we could have reused them in the existing GG24 deep funding round. With this core infra in place, participation in every deep funding round would only increase and create strong network effects.
Bots instead of CSVs thus create a moat for the incumbent (deploy your deep funding round with us since we have the most number of high quality bots that can give you good weights), potentially allowing for creation of a venture scale business from deep funding. While the element of bots answers the question “what’s your moat”, other aspects like market demand for funding mechanisms (outside and within crypto) are yet to be ascertained.
Bots in deep funding markets also allow non-technical traders to participate, as they can give money to winning models from past competitions to trade on their behalf in the current one. It can also let model builders who choose to deploy a bot instead of CSV the ability to earn passive income: launch your bot in GG25, earn profit whenever someone uses it for any round in the future.
d. GitHub repo level governance: Once funds are distributed to the ~3000 repos (100 seed nodes plus their dependencies), an important metric to track will be how many even end up claiming these funds. Eventually, we see tooling around GitHub repo level governance as required if this method of allocation picks up steam, so that deep funding is not just retroactive rewards but also translate to real leverage.
e. How to best elicit human judgment?
The lynchpin of deep funding is collecting good human judgment. How do we go about that process?
Our initial hypothesis is asking evaluators to directly look at proof of work (the GitHub repo itself) rather than judging the brand or organization as a whole. However, this approach penalizes some projects like Grow the Pie which divide their codebase into 3 repos, neither of which by itself was good enough to qualify (some ability to cluster repos together may help).
There is also debate about whether to only ask humans to choose which repo is more impactful, but get rid of the quantifier asking how much more impactful it is. A pilot with jury simply picking the more impactful repo would be good to try; in the present iteration, we decided to keep the multiplier to prevent peanut butter spreads and giving an advantage to those who split projects into multiple repos (egalitarian bias).
Another important element is getting more judgments for the top repos, since more money goes to top 10 than bottom 90 so we need to be more accurate for the topmost repos.
We have also opened up the evaluation process so anyone with an ENS name can be an evaluator. Composition of the meta committee deciding which evaluations to accept and which to reject is another open question.