TL;DR
Gitcoin ran a predictive funding challenge during GG23 where data scientists predicted how $1.5M in grants would be allocated across projects. 11 models were submitted in a 36-hour window, with the best achieving an error score of 0.016 (significantly outperforming random guessing at ~0.04). The experiment suggests predictive modeling and markets complement grant rounds by making them more scalable, detecting anomalies and substantively engaging the data science and trading communities in allocations.
Background
In early 2025, Gitcoin supported a unique initiative to host a data science competition where model builders & AI developers predicted how $1.5 million in GG23 funding would be allocated across projects, before the round even started. Upon completion, we could then see which models were closest in their predictions to the actual results.
The $10,000 prize pool for model builders was funded equally by Gitcoin and the Ethereum Foundation Unblocking Pilots team. The purpose was testing out whether models can reliably estimate funding outcomes, in which case they could become a complementary tool for grant allocations with the following benefits;
-
Engage the data science and trading community in ascertaining the funding projects in a grant round should receive
-
Surface anomalous results that may indicate manipulation, in case of large variance between data science predictions of a projects performance and its actual performance
-
Allow “shadow rounds” where winning models from previous grant campaigns are used to evaluate new projects.
This post documents key takeaways from the experiment and whether it is worth replication.
Recap
The application period for projects to apply in GG23 ended on March 31st, 2025 at 11: 59 PM UTC, while the round itself opened up for community contributions on April 2nd at 12 noon UTC. This gave model builders a narrow 36-hour window to analyze the final list of projects and predict how much funding each would receive.
$5,000 was given to the model builder with the closest prediction to actual results, while $3,000 and $2,000 were given to 2nd and 3rd place. A writeup on their model and how it works was mandatory to be considered for prizes.
Results
To evaluate the initiative, three KPIs were proposed for the initiative, covering participation levels, prediction accuracy, and information discovery.
1. Number of model submissions
A total of 11 valid submissions were made within the 36 hour period, of which 7 submitted writeups on their model parameters. Competition accessible here
2. Performance benchmarking
Predictions were evaluated using an error score technique that takes the root mean squared error (RMSE) between the predicted and actual amounts of funding received by the projects. Lower scores indicate more accurate predictions.
The top three submissions were:
• 1st place: David Gasquez — error score 0.016
• 2nd place: Omniacs DAO — 0.0173
• 3rd place: Limonada — 0.018
Models that do not consider any features (random guesswork) would usually produce an error score of roughly 0.04, according to @bill-pond (Pond CTO at the time). The lowest-ranked submission scored 0.034, more than double the error of the winning model. The high variance between top performers and lower ranked submissions indicate some confidence in the efficacy of the winning model.
The error score is an important metric for evaluating whether “shadow” funding rounds are viable, where even if projects do not participate in a given grant round, we can simply query the winning model to get an estimate on how much funding they would have got had they participated. The lower the error score by the top models, the higher our confidence in reusing it.
3. Information surfacing tool on metrics and models
One key advantage of these predictive modeling rounds is surfacing a trove of key metrics by which projects were assessed. In the predictive funding challenge, the winning models mostly made use of feature engineering with a reliance on XGBoost algorithms for scalability (since some projects are new and not present in the old dataset) and accuracy.
Some of the important features to predict performance of a project in the round were number of contributors, amount per contributor in past rounds, and sentiment score (traction and virality) on each project.
Takeaways
As a best practice, we recommend that any public funding round should integrate a predictive component where model builders and a prediction market attempt to forecast the results. The extra overhead is setting aside some prize money for top model builders & creating the contest itself, while the benefits are the following;
-
Scalable: Grant rounds are expensive to run. However, predictive competitions can make them more scalable by producing models that can then estimate allocations for future rounds or new projects.
-
Collusion Resistance: Even during the round itself, operators now have an independent allocation list separate from the process they ran. For example, if the QF round was heavily sybil attacked, operators could choose to use the predicted allocation from the winning model instead (similar to how Gitcoin went with cluster QF instead of simple during GG18).
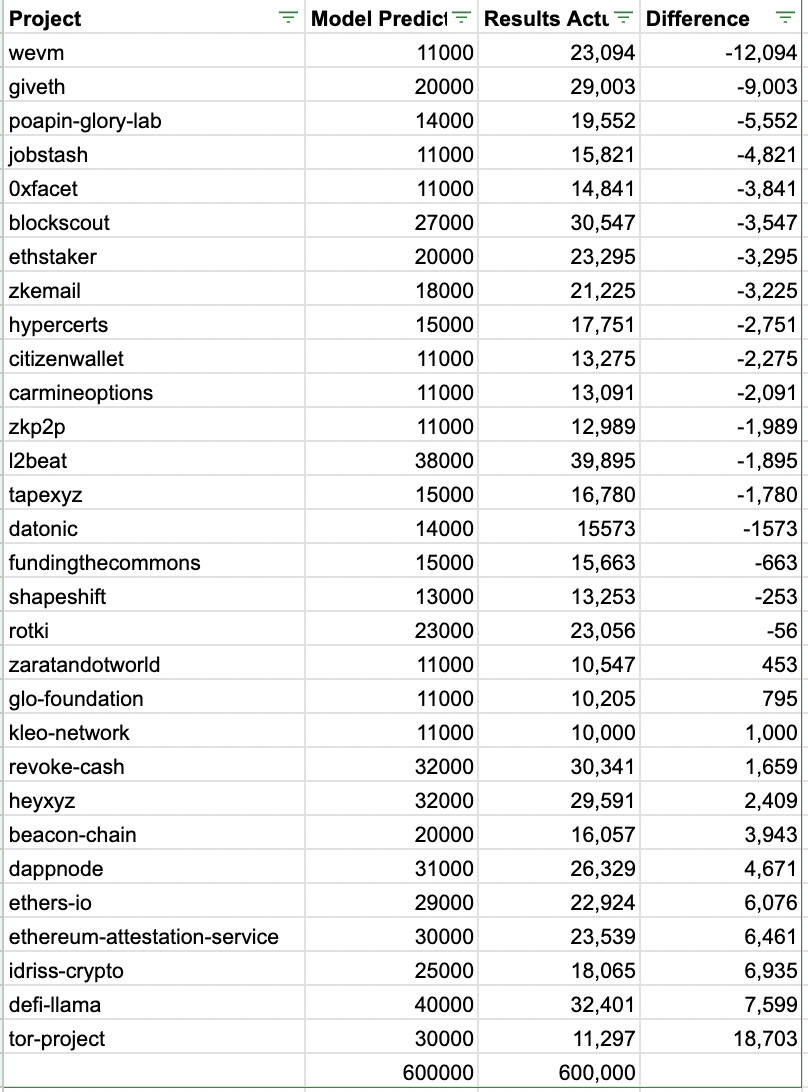
Full list of predictions by the winning model accessible here
Even if the option of going with results of the winning model is not exercised, simply keeping it as a possibility has the positive effect of reducing incentive to sybil attack or manipulate the round. Attackers should be made aware that their efforts may go to waste if round operators choose to go with the winning model’s list instead of the QF allocations.
Such contests also provide a basis upon which to investigate sybil attacks or favoritism in a committee. For example, if a particular project gets a high amount in QF or committee funding but models did not predict it, round operators should investigate whether there was any sybil activity present with that project or if committee members had a bias.
- Markets: In addition to model competitions, grant rounds should simultaneously host prediction markets where traders estimate how much funding each project will receive. These markets would resolve once final allocations are announced, rewarding traders whose predictions move market estimates closer to the actual funding distribution.
These markets can
-
attract participants beyond donors to the much larger community of traders, who can now make a profit for accurate price discovery of public goods
-
surface collective expectations about project performance from the market
-
provide another independent signal alongside the allocation method and model predictions for use as a fallback allocation
Here is an example of a past process where 40 committee members provided evaluations on the value provided to Ethereum by different clients, which simultaneously had a data science competition and a market resolving based on their evaluations.
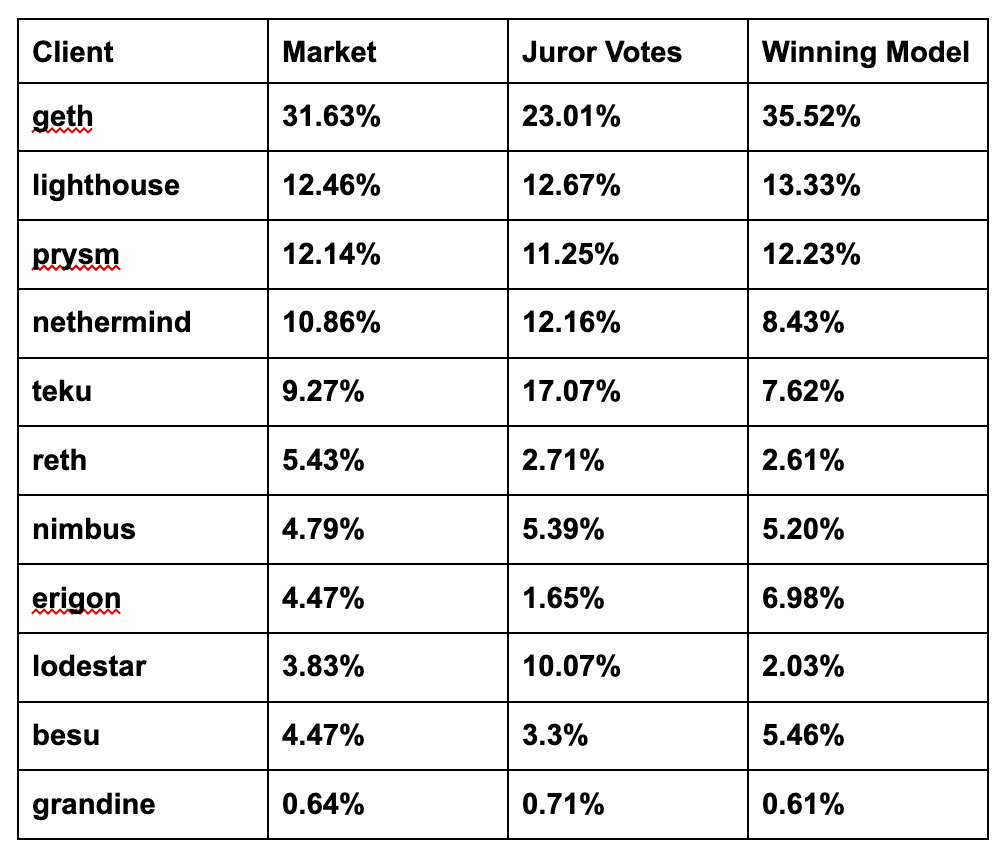
From these 3 proposed allocations, decision makers can simply opt for the list best aligning with their preferences instead of being forced to accept the average of juror votes.
Limitations
Running prediction markets and modeling competitions alongside grant rounds can attract the data science and trading communities while also helping operators scale their round and generate fallback allocation lists.
However, the following conditions have to be met;
-
The funding round, applications made by projects and final results must be made public. Many funders do not like revealing amounts and projects chosen as it distorts the market (new grantees ask for money based on how much others got instead of what they need). The results of the round (which projects got how much money) need to be public to resolve the market and select the winning model in the contest.
-
There must be a time lag between project eligibility and final allocations, during which model builders can predict and traders can wager money. The short window of 36 hours during GG23 dampened participation in this experiment, ideally a week allows sufficient time to attract model builders and give them time to develop.
-
Some design work is as yet incomplete on how round operators can select between the different lists produced, so that they do not simply choose the one favoring their known associates the most.
What’s Next
Ideally, all funding rounds where results are public and open should integrate a data science contest and market where AI developers can predict the allocation outcome. This is an easily adoptable idea as it requires no internal change in the processes of any funders, we simply use their own existing method for allocating money as ground truth data. In the coming GG25 rounds and beyond, as well as with other funders, we hope to see more adoption of predictive funding challenges alongside their funding round.
The business opportunity for Gitcoin is to become the platform where models are submitted and can be queried by anyone for a fee. If a funder needs a lightweight but reliable method for allocating money between projects, they can then simply choose from among the menu of models based on their performance in predicting past funding rounds to produce a first draft of allocations.