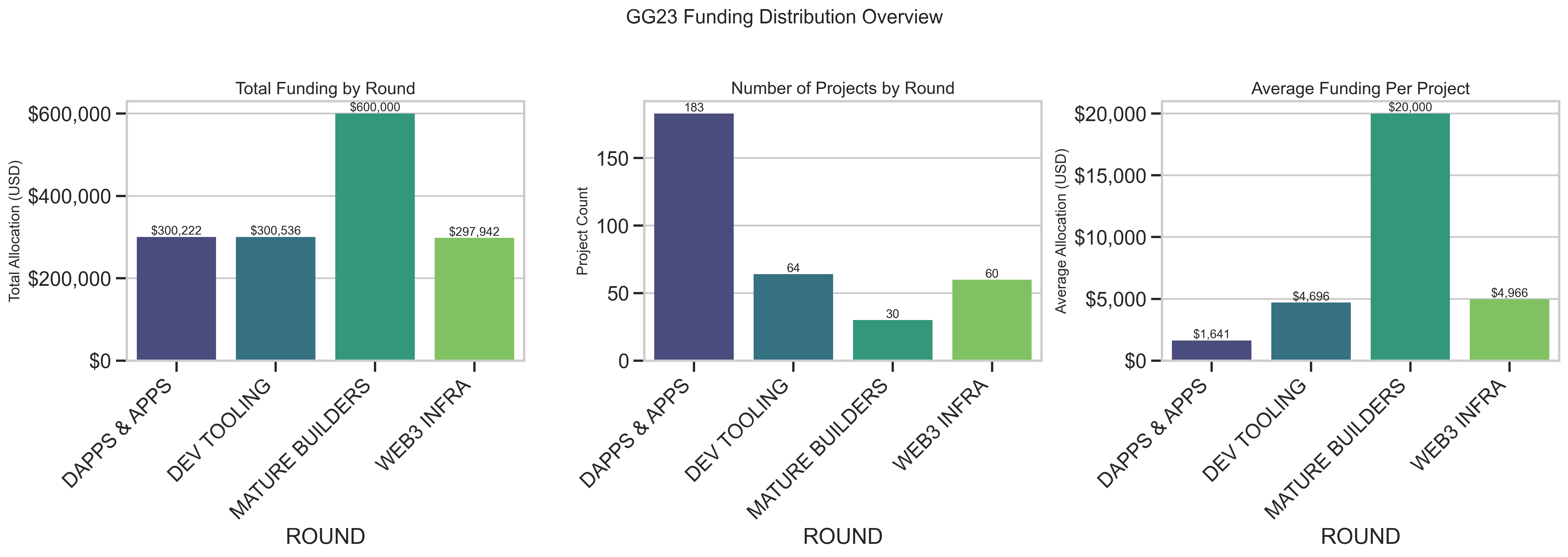
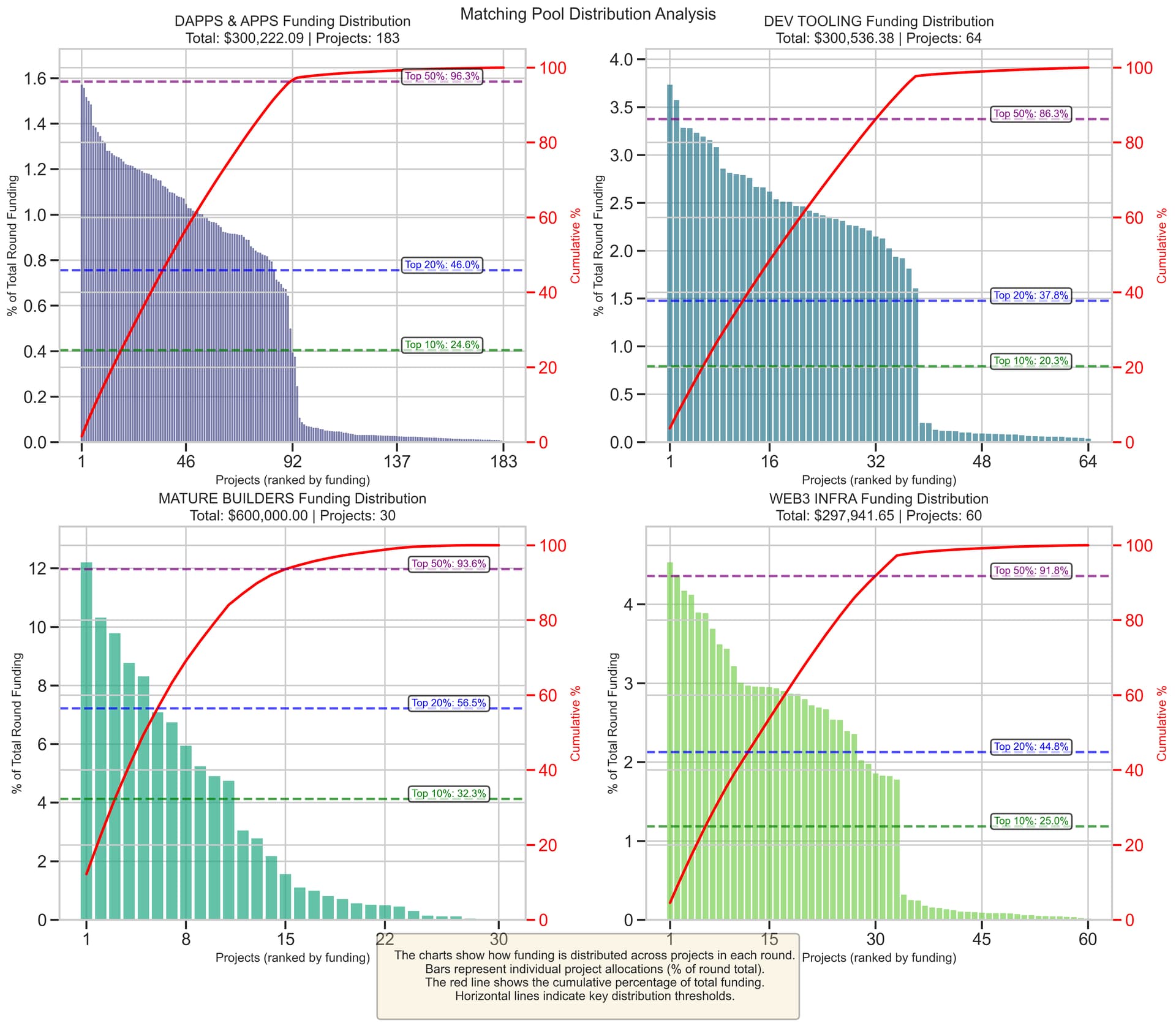
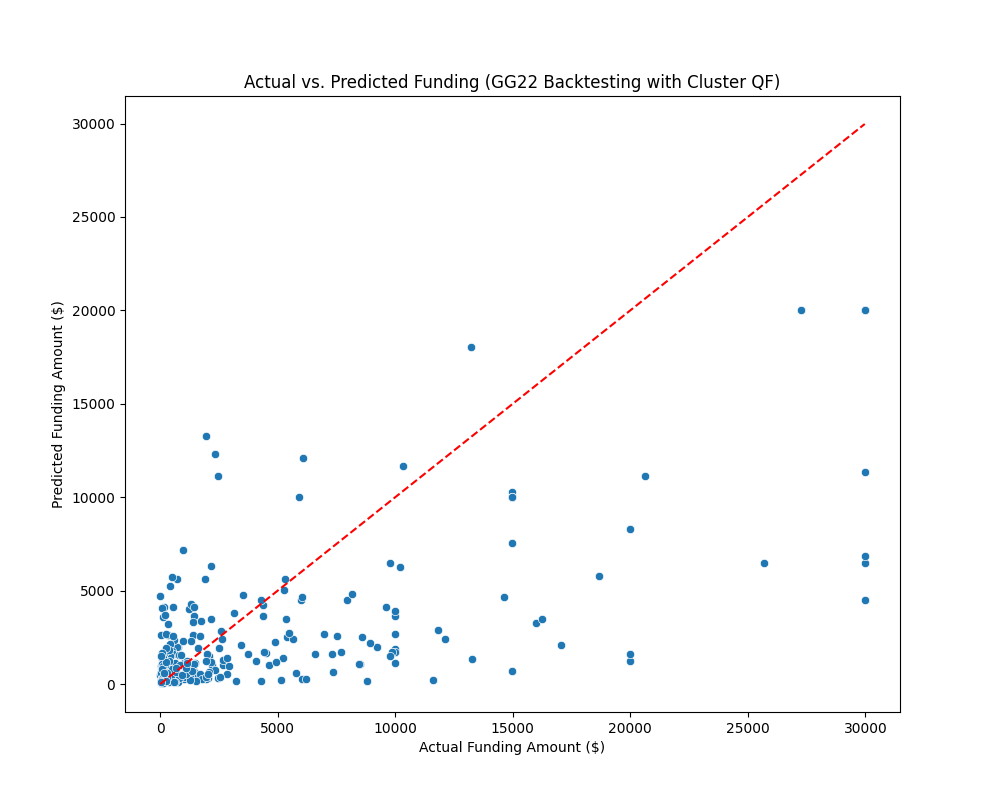
GG23 Funding Prediction Model
Hi! I am Oleh RCL and this is my write up.
github Oleh8978 git_coin_rounds (As well code is been submitted on the Pond page)
******Pond Ai platform username: Oleh RCL, email: mihajlovskyoleg(at)gmail(dot)com ****
This model predicts project funding amounts using a combination of feature engineering and a stacked ensemble learning approach. The process can be broken down into the following steps:
1. Data Loading and Preparation
***** The script begins by importing necessary libraries, including pandas for data manipulation, numpy for numerical operations, scikit-learn for machine learning, and joblib for model persistence.****
***** pandas is used for loading and manipulating structured data in DataFrames.****
***** numpy provides support for efficient numerical computations.****
***** scikit-learn offers a wide range of machine learning algorithms and tools for tasks like data preprocessing, model selection, and evaluation.****
***** joblib is used for efficiently saving and loading Python objects, particularly trained models.****
***** It loads the historical dataset (dataset_new.csv - I have renamed it from original long name with spaces etc.) and the project list for predictions (projects_Apr_1.csv) into pandas DataFrames.****
***** The historical dataset contains data from previous Gitcoin Grants rounds, which will be used to train the model.****
***** The project list contains the projects for which the model needs to predict funding amounts.****
***** The columns in both DataFrames are renamed for easier manipulation.****
***** For example, ‘Round Name’ is renamed to ‘ROUND’, ‘Contribution Amount’ to ‘AMOUNT’, and so on. This ensures consistency and simplifies referencing columns in subsequent steps.****
2. Feature Engineering
***** The script engineers several features from the existing data:****
***** project_length: Length of the project title.****
***** This feature captures the complexity or descriptiveness of the project title, which might be related to funding.****
***** project_mean_funding: Mean historical funding amount for each project.****
***** This feature represents the average funding amount that a project has received in past rounds.****
***** project_count: Number of historical funding records for each project.****
***** This feature indicates how many times a project has participated in previous rounds.****
***** Missing values in the newly created features are filled with 0.****
***** If a project has no historical data, its project_mean_funding and project_count are set to 0 to avoid errors.****
***** The categorical variable ROUND is one-hot encoded using OneHotEncoder.****
***** One-hot encoding converts the categorical ROUND variable into a set of binary variables, where each binary variable represents a unique round. This is necessary because most machine learning models can only process numerical data. The handle_unknown=‘ignore’ parameter ensures that the encoder can handle unseen round categories during prediction without raising an error.****
***** Text features are extracted from the PROJECT column using TfidfVectorizer.****
***** TF-IDF (Term Frequency-Inverse Document Frequency) is a technique used to convert text data into numerical features. It measures the importance of each word in a document relative to the entire corpus.****
***** The max_features=100 parameter limits the number of features to the top 100 most important words, which can help to reduce dimensionality and improve performance.****
3. Data Preprocessing
***** The numerical features are scaled using RobustScaler to mitigate the impact of outliers.****
***** RobustScaler scales features by subtracting the median and dividing by the interquartile range. This makes the model less sensitive to extreme values in the data.****
4. Model Training
***** The data is split into training and validation sets.****
***** The training set is used to train the model, while the validation set is used to evaluate its performance and tune hyperparameters.****
***** GridSearchCV is used to find the optimal hyperparameters for RandomForestRegressor and XGBRegressor.****
***** GridSearchCV systematically searches through a predefined grid of hyperparameter values to find the combination that results in the best model performance.****
***** RandomForestRegressor is an ensemble learning method that constructs a multitude of decision trees and outputs the mean prediction of the individual trees.****
***** XGBRegressor is an optimized distributed gradient boosting library.****
***** A stacked regressor is initialized with RandomForestRegressor, XGBRegressor, and GradientBoostingRegressor as base models, and LinearRegression as the final estimator.****
***** Stacking is an ensemble learning technique that combines the predictions of multiple base models to create a more accurate meta-model.****
***** GradientBoostingRegressor is another ensemble method that sequentially adds predictors to an ensemble, each one correcting its predecessor.****
***** LinearRegression is used as the final estimator to combine the predictions of the base models.****
***** The stacked regressor is trained on the training data.****
***** K-fold cross-validation is performed to evaluate the model’s performance.****
***** K-fold cross-validation is a technique used to assess the performance of a model by partitioning the training data into k folds. The model is trained on k-1 of the folds and tested on the remaining fold, and this process is repeated k times. The results are then averaged to provide a more robust estimate of the model’s performance.****
5. Prediction and Submission
***** The project data is preprocessed in the same way as the training data.****
***** This ensures that the model receives input data in the same format as the data it was trained on.****
***** The trained model is used to predict the funding amounts for the projects.****
***** The predictions are saved to a CSV file (submission.csv).****
***** This file will be submitted as the result of the competition.****
***** The trained model is saved to a pickle file (model.pkl).****
***** This allows the model to be loaded and reused later without having to retrain it.****