As part of the GG24 Deep Funding round and an Ethereum Foundation grant, I took ownership of the juror data collection side of Deep Funding: to identify what could be improved upon from the trial run, build a better interface to collect judgments, and document lessons learned. This post is that documentation, covering the design decisions behind Verdict, what juror behavior actually looked like in practice, the incentive problems we ran into, and the AI-based weighting model I developed for both seed node and dependency evaluation to help jurors vote.
I hope it’s useful both as a record of this round and as a foundation for whoever works on jury design in future funding rounds. If you haven’t made any comparisons yet, for selecting winning models or resolving deep funding markets, try it out here.
1. Where we started
The first phase of Deep Funding data collection collected approximately 650 comparisons from 45 jurors over roughly nine months. The original app was simple by design: two randomly selected repos, a question asking which was more valuable to Ethereum, and a multiplier. There wasn’t even a login, since jurors came by invite only.
In two blog posts written before I joined the project (Asking Deep Funding Jurors Better Questions and Deep Funding Jurors Need Tools), I analyzed the trial data and identified three core problems:
Multiplier inflation. The median multiplier jurors provided was 5x, but when reconciling all comparisons to find the best-fit consensus distribution, the median implied ratio between projects was only 1.8x. Jurors were systematically overestimating differences by a factor of roughly 3x. It appeared that users had a bias towards larger differences, compounded by the fact that jurors had no reference point for what a “reasonable” multiplier looks like.
High disagreement rate. Jurors disagreed about which project should be ranked higher 40% of the time. Some of that may have reflected genuine philosophical differences about what Ethereum values. But some of it likely reflected the difficulty of the task itself — jurors were doing something they’d never done before, with no training and no tools.
No feedback loop. Jurors couldn’t see the downstream implications of their choices. One juror rated Solidity 999x more valuable than Remix — a comparison that, when reconciled with all other data, resulted in Solidity receiving roughly 25% of all funding. Did they intend that? There was no way to know, because the interface gave them no way to find out.
A fourth problem, which emerged more clearly during this round of GG24 data collection, was the incentive problem: even with a well-designed public app, getting busy experts to voluntarily contribute judgment at scale is very hard. More on this below.
2. What We Built
Verdict was built from scratch over approximately three months (October–December 2025). We decided to use ENS-based authentication. It avoided formal onboarding, democratized jury duty to anyone on the internet, and gave us useful information about the expected quality of the contributor to help filter spam if we were to get any.
The core flow of Verdict consists of several screens:
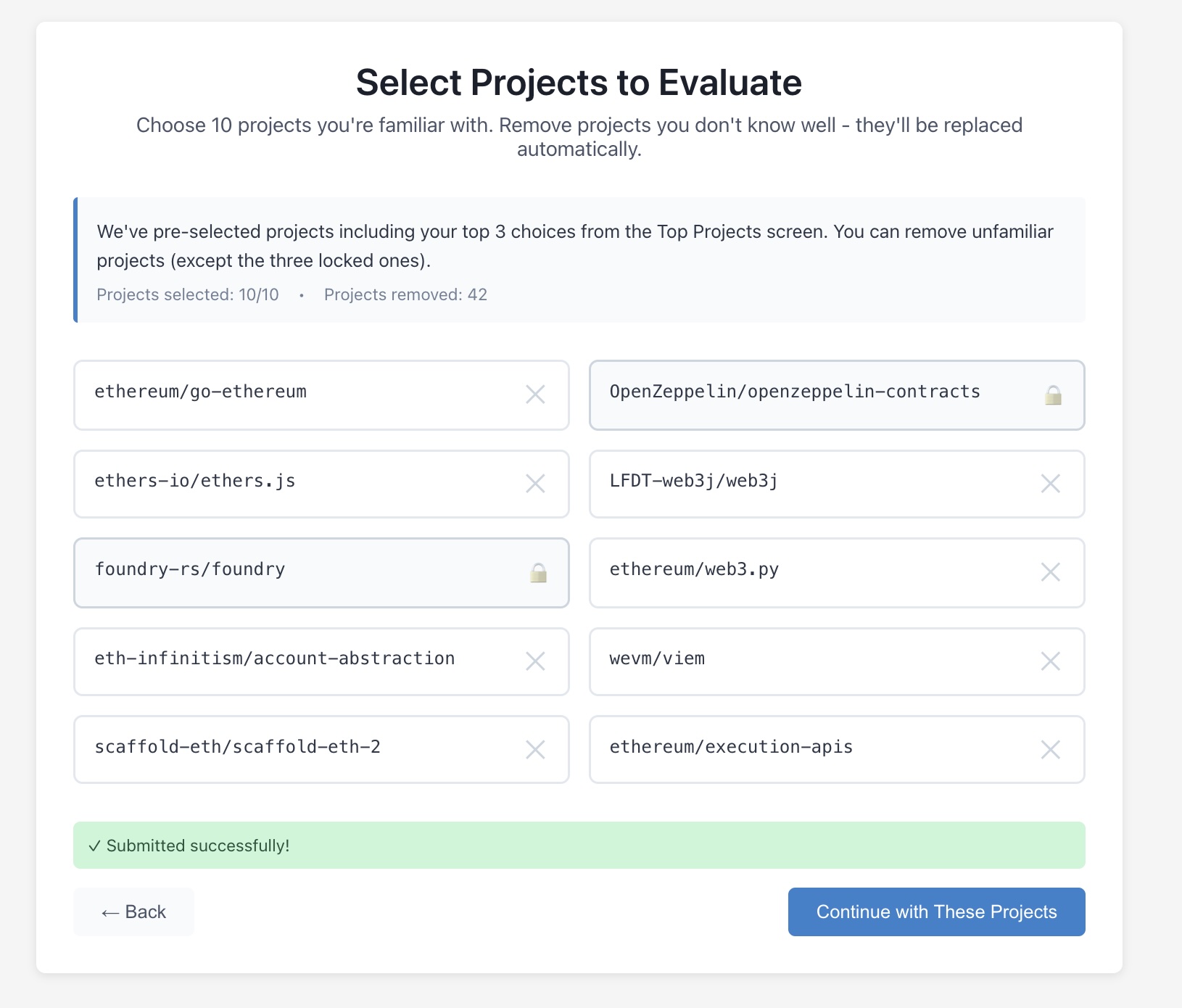
Repo Selection
Rather than presenting random pairs immediately, jurors first select a set of 3 repos they felt were most valuable. They were then given 7 other randomly chosen repos each of which they could reject for another randomly chosen repo. This approach balanced a few different concerns: 1.) we wanted to make sure that the top of the list that would receive the most funding had the most data, 2.) selecting the top 3 is equivalent to performing many implicit binary comparisons, and 3.) we wanted to avoid direct selection of all repos to evaluate.
In practice, this created its own friction. Several jurors reported anxiety about the selection screen, they felt they needed to know all 98 repos to make a good selection, which they didn’t. Other jurors were annoyed that they didn’t get to choose repos they wanted to evaluate. One juror noted that repos at the top of the list (which were sorted by estimated value) got disproportionate attention, which was intended, but is a potential drawback.
Pairwise Comparisons
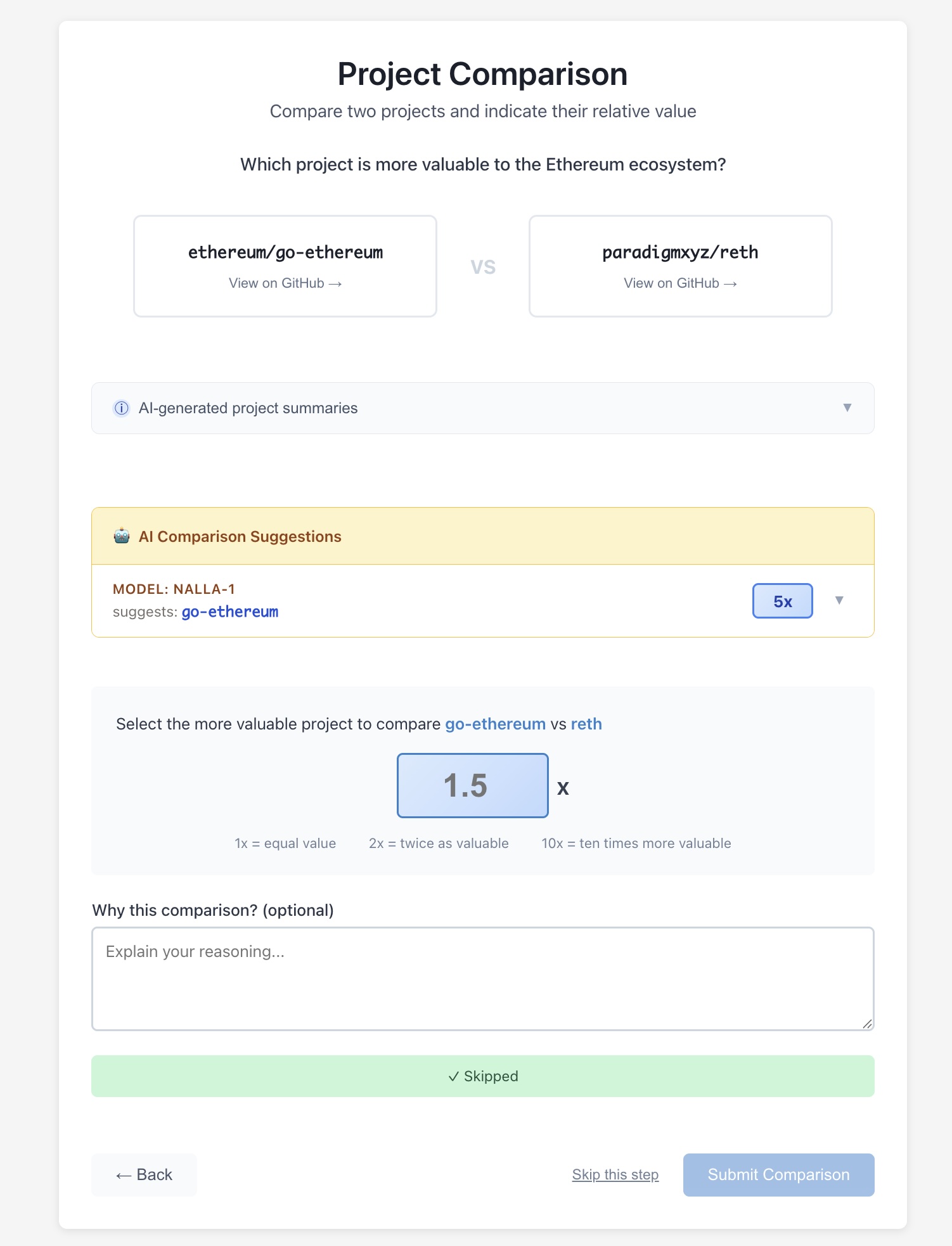
The core comparison interface is similar to the original app, but with several additions:
AI-generated project summaries. For each repo in a comparison, jurors see an AI-generated summary covering what the project does, its role in the Ethereum ecosystem, and its rough usage footprint. This was consistently the most praised feature across all user feedback. One juror called it “the BEST part of the app.” It directly addresses the problem of jurors being asked to compare projects they’re only vaguely familiar with.

AI comparison suggestions. Alongside each comparison, Verdict displays a recommendation from Nalla-1, an AI model I built on top of work by David Gasquez, showing which project the model would pick and with what multiplier, along with a brief explanation. The intent is to give jurors a calibration anchor. We didn’t want to tell them what to think, but did want to show them one informed perspective they can agree with, push back against, or use to sharpen their own reasoning. We reached out to model builders from previous contests about contributing models as well, but have not had any submitted as of the writing of this post.

Skip functionality. Jurors can skip comparisons they don’t feel qualified to make. This was explicitly requested early in testing. Verdict makes it easy to skip a comparison and then come back to it later.
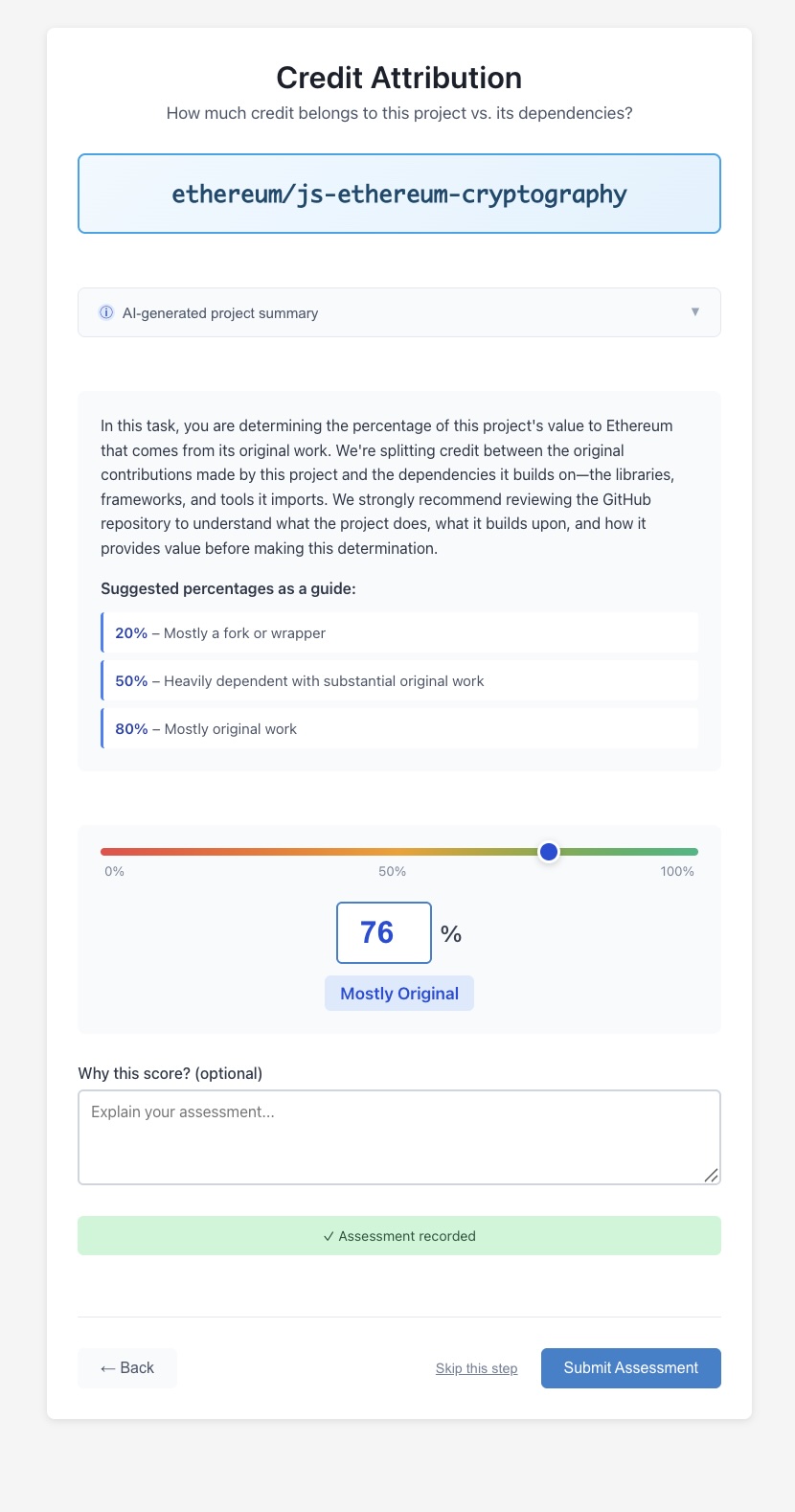
Originality
A separate screen asks jurors to assess three randomly chosen repos’ “originality”. Originality is the share of its value that should remain with the seed node versus be passed on to its dependencies.
Level 3: Dependency Evaluation
Level 3 was the hardest problem and the most significant departure from the original approach. The original app attempted pairwise dependency comparisons for Level 3 and largely failed — not primarily because of interface problems, but because the underlying dependency lists were bad. Maintainers were being shown long lists of irrelevant dependencies (build tools, test libraries, language runtimes) alongside genuinely important ones, and asked to compare them. The task felt absurd because it was absurd — comparing a critical consensus library to a formatting package isn’t a meaningful judgment.
The fix required solving a data problem before solving an interface problem. I built an AI-based system that analyzes actual code usage within each repo — not just package.json or README references, but how dependencies are actually used — to generate weighted dependency lists where the most critical dependencies are correctly identified and ranked. The details of this model are described in Section 5.
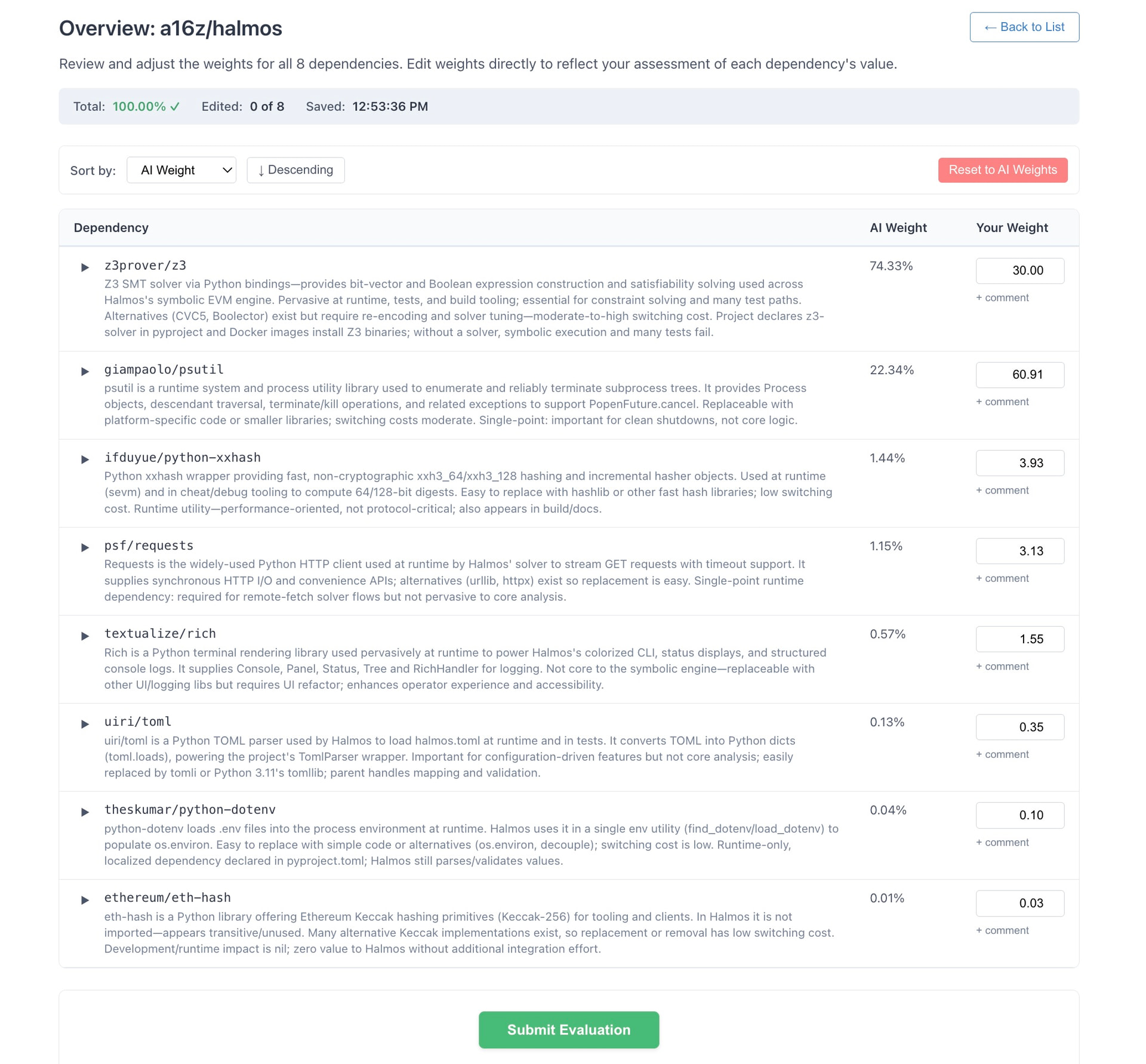
With better dependency lists in hand, the interface problem became more tractable. Rather than pairwise comparisons, Verdict uses an overview mode for Level 3: maintainers see a single-screen table of their dependencies with AI-suggested weights pre-filled, and they adjust numbers they disagree with. The AI does the heavy lifting; the maintainer’s job is to find and correct errors.
This design was validated quickly. In the first real maintainer sessions, several maintainers noted AI correctly identified the top 3-5 critical dependencies in nearly every case. Maintainers still made meaningful adjustments — in one case, a dependency ranked 2nd and 4th by the AI was argued by the maintainer to deserve significantly more weight due to its role in upcoming protocol work the AI wasn’t aware of. But the cognitive burden dropped dramatically. Instead of scanning 70 dependencies and trying to construct pairwise judgments, maintainers were reviewing a pre-sorted list and correcting perhaps 4-7 entries.
3. What We Learned About Juror Behavior
After approximately three months of data collection, we have roughly 20 jurors who completed the full flow, with about 50 total logins. This is less than the trial run’s ~45 jurors, though the trial run ran for nearly a year and drew on a curated list of named community members assembled with significant personal outreach.
A few observations:
AI summaries substantially lowered the knowledge barrier. The most consistent feedback was that jurors felt more confident making comparisons when they had a clear description of what each project actually does. Several jurors who might have skipped comparisons due to unfamiliarity instead engaged with them after reading summaries.
Asking about the “bottom” repo doesn’t work. The original design asked jurors to identify both the most and least valuable repos as a way of establishing a personal scale. In practice, jurors found identifying the least valuable repo uncomfortable and cognitively difficult — it required scanning the full list, which many hadn’t done. We dropped the bottom repo question. The top repo question remained useful.
Similar project identification is harder than expected. One of my original proposals was to ask jurors to identify a project of similar value to a given project — targeting the close comparisons that are hardest and most informative. In practice, jurors found this harder than random pairwise comparisons, not easier. Scanning a full list to find a similar project required more effort than just evaluating two presented options.
Level 3 requires synchronous sessions. We collected almost no Level 3 data asynchronously. The data we have came almost entirely from Devansh sitting with maintainers in person or on calls. This is partly an interface problem (which improved significantly with the overview mode) and partly a knowledge problem — maintainers needed to talk through their reasoning and coached on the interface to produce good data, and that conversation format doesn’t translate well to a solo async session. Defining impact for level 3 dependencies is hard, so making it more of an interactive brainstorming session seems to work better than providing the interface unprompted.
ENS login was a persistent friction point. Slow first-login times (up to ~10 seconds for cold ENS resolution), lack of an ENS name, and failures for users without reverse resolution set up all created drop-off. We addressed most of these with caching and fallback RPC endpoints, but ENS login remained one of the most-cited usability complaint throughout the round.
4. The Incentive Problem
The most significant lesson from GG24 data collection is one that no amount of interface improvement fully solves: getting expert judgment at scale requires sustained motivation, and goodwill alone doesn’t provide it.
We launched Verdict publicly in December 2025. The announcement received a Vitalik retweet and an EF account repost. It generated meaningful traffic. It converted to roughly 20 serious jurors.
When we examined where actual data came from, it fell into three tiers:
Organic public participation — very low conversion. People visited, explored, didn’t complete.
Personal outreach — the primary source of data. Direct messages to specific community members, leveraging existing relationships. This required significant ongoing effort from program lead Devansh and produced moderate results.
Synchronous sessions — the highest quality data, almost all of the Level 3 data. Devansh sitting with a maintainer in person or on a call, walking through the app together. Not scalable.
This distribution suggests the interface was not the primary constraint. The primary constraint was motivation.
My current recommendation, with data collection still ongoing, is to make participation a condition of funding eligibility. Specifically: each of the 98 repos in the round should be required to have at least one person associated with the project complete the evaluation flow before that repo is eligible to receive funds. This is fair as projects that benefit from the mechanism should contribute to it. It creates pull rather than push. And it means the people providing judgment about a project are the people most likely to know it well.
This also has a positive secondary effect: it increases the weight of informed judgment in the dataset. A maintainer evaluating their own project and its dependencies is providing exactly the kind of high-context data the mechanism needs.
5. The AI Models behind Verdict
The Verdict interface uses several AI models to help jurors in their deliberation. This section describes these models and how they were made.
Level 1: Repo Summaries and AI Recommendation
For Level 1, Verdict provides AI summaries for each of the 98 seed repositories, along with an AI-created recommendation.
A key input to making these summaries and AI recommendations was David Gasquez’s deep funding weights, specifically his “elo weights”. The elo weights are a thoughtfully designed weighting of the seed repos that we would expect to be reasonably close to juror’s evaluations.
Repo summaries anchored to ELO rank. There are 98 seed repositories in Level 1, far more repositories than any person is likely to be deeply familiar with. So, to assist jurors, I felt it was necessary that we have summaries of each project to orient the juror on what they are evaluating.
There were several problems encountered in trying to create these summaries. The first problem is that a generic LLM asked to describe a repository will produce promotional boilerplate — vague claims about importance that don’t differentiate well between projects. To fix this, each summary was generated with explicit calibration. The pipeline loaded two sources for each repository: a README and a deep research report generated by OpenAI’s o4-mini deep research model. These were fed into a GPT-4o-mini prompt that included four calibration examples at different elo levels showing how language and specificity should scale to a project’s actual impact tier. By telling the model the target project’s ELO rank alongside those anchors, the prompt guided it toward matter-of-fact, metric-grounded summaries (“accounts for 41% of execution clients”) rather than marketing language. The result was one factual paragraph per repository, calibrated to its expected position in the ecosystem.
AI Recommendations. With repo summaries in hand, the next step was generating pairwise comparisons that would act as an AI recommendation. I felt the AI recommendation should include a choice of winner, a multiplier between the two projects, and an explanation. I tried several different approaches, including attempting to simulate the ten most prolific GG24 jurors but found the results lackluster. Simulated jurors showed systematic biases — a tendency to pick option A when options were listed alphabetically, and a default to round multipliers like 5x regardless of the implied weight ratio. These biases distort predictions away from the underlying weight structure.
To address this, I used the Elo scores to create a synthetic comparison for each pair, and then include the comparison in an LLM prompt as an explicit anchor, with a strong directive that the model should disagree with it less than 10% of the time. The LLM retained freedom to write its own reasoning and adjust for strong evidence, but the weight-derived anchor steered it away from positional bias and toward multipliers that were internally consistent with the full set of comparisons. The final output is a set of reasoned pairwise comparisons across all 98 repositories that jurors found helpful.
Level 3: Dependency Weights
A key part of the GG24 is that we are using collected human data to settle prediction markets on the final allocations. This has several benefits, such as: 1.) we can collect less data since we don’t need to settle all prediction markets but market participants will move market prices for all allocations, 2.) prediction markets may have wisdom of the crowd benefits when trying to predict the outcome from jurors.
To use prediction markets effectively, the Level 3 Seer market needs initial base rates for the prediction markets. This lowers losses to liquidity providers and ensures that even if we turn out to have low participation we will have reasonable results. But, with 98 seed repos and thousands of dependencies between them, getting humans to generate those base rates from scratch was simply not feasible. It would require doing an entire level 3 data collection before we did the Level 3 data collection. So we decided to try using AI to do it, using insights from the Pond contests.
Making these AI Level 3 value weights also turned out to have a useful side effect: the dependency weights could be fed directly into Verdict’s overview interface, giving maintainers a pre-filled starting point to review and correct rather than a blank page. The AI model and the juror tool ended up reinforcing each other.
To actually make the weights, we had two phases: filtering the raw dependency data down to what’s actually relevant, and then generating relative value weights across the surviving dependencies.
Phase 1: Filtering Transitive Dependencies
The starting point was raw dependency data from Open Source Observer covering all 98 seed repositories — 13,099 (repo, dependency) pairs in total. The problem is that most of those dependencies aren’t meaningful. Package managers pull in transitive dependencies — libraries that your dependencies depend on — which bloat the list enormously. A project might have 20 direct dependencies but 200 in its lockfile. Asking a maintainer to evaluate 200 dependencies, most of which their project doesn’t directly use, was exactly the failure mode of the original approach. It needed to be solved at the data level before touching the interface.
To filter the list, I built a GPT-4o-mini agent equipped with a ripgrep search tool and a file reader. For each (repo, dependency) pair, the agent checked for signs of a transitive relationship — // indirect annotations in Go module files, presence only in lockfiles, configuration belonging to another dependency — and early-stopped as soon as it found one, keeping token costs low. Running this across all 98 repos in parallel with up to 100 concurrent workers took hours rather than days, at roughly $10–15 in API costs total.
The results: roughly 79% of the 13,099 pairs were classified as unused or transitive, bringing the working set down to 5,314 meaningful (repo, dependency) pairs.
Phase 2: Characterizing Usage and Generating Weights
With a filtered dependency list, the next step was understanding how each dependency provides value to its parent project. The same agent was used more deeply here: for each surviving dependency, it issued multiple ripgrep searches, inspected representative code samples, and produced a structured usage report. The report captures the dependency’s usage class (ranging from SinglePoint — used once — to Pervasive — used across multiple core subsystems), its role (runtime feature, test support, build tooling, etc.), and specific descriptions of what functionality it enables.
These usage reports became the raw material for pairwise comparisons. For a repository with N dependencies, the pipeline generates approximately 5×N random pairs and prompts an LLM to evaluate each one. Each comparison is enriched with a summary of the parent repository and a description of each dependency from deps.dev or its GitHub README.
The comparison prompt was structured to force deliberation rather than snap judgments. The model is asked to first argue the strongest case for dependency A, then the strongest case for dependency B, then deliberate, and finally produce a winner and a multiplier. Multiplier guidance ranged from 2–5x for similar-tier dependencies up to 1,000–10,000x for extreme cases like comparing a consensus-critical cryptographic library to a CLI helper. The five evaluation dimensions driving each comparison were:
- Scope of capability enabled — how much of the parent’s functionality depends on this dependency?
- Failure severity — what breaks if this dependency disappears?
- Replaceability — how hard would it be to swap in an alternative?
- Counterfactual development cost — how much work would the parent project have had to do without it?
- Step-share — how much of the relevant capability does the dependency handle versus the parent’s own code?
These dimensions came from first-principles brainstorming about what factors should drive dependency value. With hundreds of pairwise comparisons per repository, I converted those relative judgments into a single consistent weight for each dependency using Huber loss optimization. The final output for each repository is a set of weights summing to 1.0.
Acknowledgments
I want to thank Devansh, Vitalik, Clément, David Gasquez, the jurors who participated, and the Ethereum Foundation for their assistance in this work.
View the Verdict source code
Try the Live app: https://deepfundingjury.com