Why
Centralization risks exist everywhere. The FTX debacle highlights again the risks of an opaque centralized entity taking custody of people’s assets. But centralization isn’t only a problem for money. It is a big problem for data too. When data is held opaquely by some centralized actors they have the power of insight - to see how people behave, to forecast people’s actions, to gain a competitive edge, to gatekeep, and to paywall.
Web3 is largely a reaction to the data centralization of web2. Web3 is building itself out of composable open-source software “legos” that allow free access to the internet of apps along with the cryptographic tools to do so in a permissionless way where you keep possession of your own data and assets. However, we are currently observing a recentralization of Web3. Just as users are too often choosing to hand custody of their assets to new centralized power players, so too is data concentrating in the hands of a few organizations. Even in the Ethereum ecosystem, where the base layer is highly decentralized and the cypherpunk ethos is strong, access to Ethereum is often via a few centralized portals such as exchanges, wallets with default RPC providers, etc rather than using self-hosted nodes. Because syncing an archive node and scraping it for data is slow and expensive, one or two indexing providers dominate access to historical data. Most of the stack above the base layer protocol is too centralized.
Many projects try to fight this centralization by building tools and solutions independently, but a lack of sharing culture and infrastructure means lots of operators are reinventing the wheel. To fight recentralization, sharing data, insights, and tools must be the norm. Composability is a massive unlock, but only if developers and analysts can share their composable tools roughly frictionlessly. The Open Data Community (ODC) is an initiative that aims to decentralize all the way up the stack by building software and a decentralized community around it!
Gitcoin
Gitcoin is decentralizing itself by migrating its public good funding system to a protocol, such that it can be deployed by communities without requiring Gitcoin to act as a centralized manager for grant-giving. Gitcoin has been active for several years and has facilitated almost $70 million in public goods funding. However, until now Gitcoin has relied on a small group of trusted contributors to run grant rounds and analyze data about them. With Gitcoin decentralizing grant management and fraud detection and defense, it is also essential to decentralize Gitcoin’s data collection and analysis. This creates immediate demand for an OpenData Community building decentralized tools and a community of analysts.
OpenData Community
The OpenData Community is an independent DAO started by GitCoin. The purpose of ODC is to create and curate useful decentralized tools and data that can be used by decentralized Gitcoin and the web3 software stack at large. The ODC will be a credible hub or commons where analysts and devs can come together to develop, improve and share decentralized software, data sets, dashboards, and visualizations.
Read more about the ODC in this recent Gitcoin forum post:: https://gov.gitcoin.co/t/gitcoin-starts-and-supports-the-opendata-community/11886
Hackathon
To kick things off and bootstrap the ODC community, Gitcoin hosted an OpenData Community Hackathon! There were three areas of focus that are high-priority areas for ODC:
-
Sybil slayers: detecting and defending against Sybil attacks
-
Human Incentives: analyzing and optimizing human grant reviews
-
Dune Detectives: building useful dashboards and insights using Dune dashboards
We were delighted to have a lot of enthusiastic participants and some great projects in the inaugural hackathon - let’s dive into some of the winners to showcase some of what was done.
Dune detectives
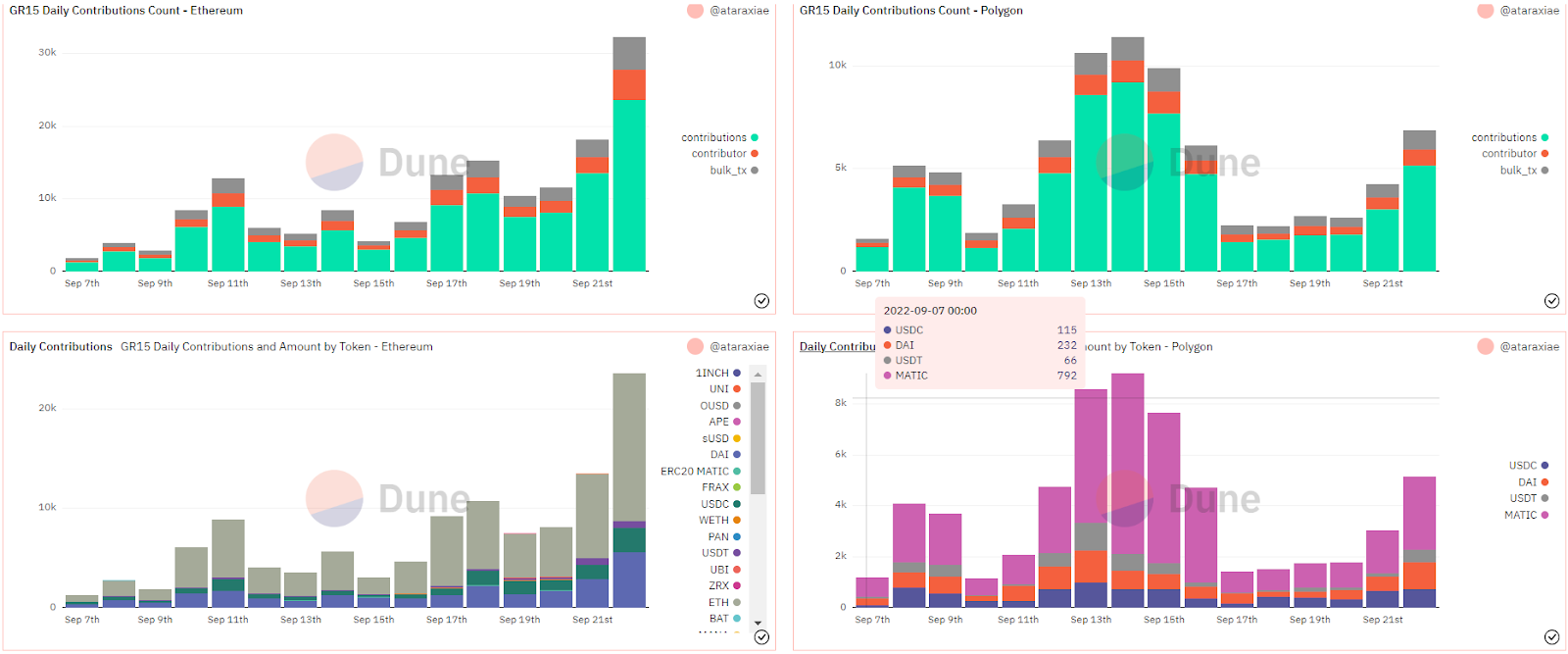
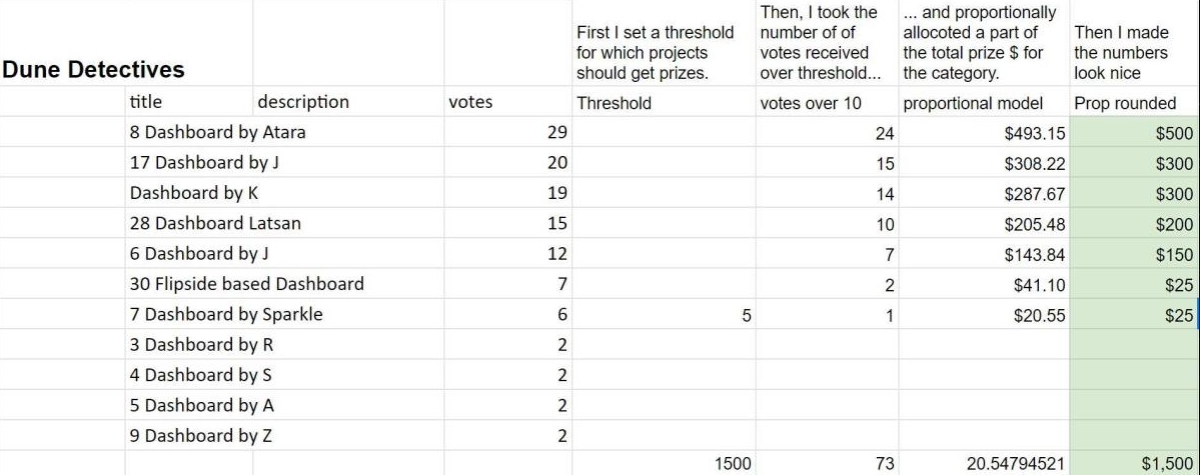
The top Dune Detective was user Ataraxiae who pulled together a very detailed dashboard on Gitcoin’s GR15 data. Starting from a fairly large raw dataset comprising all of Gitcoin’s data on GR15 grants, Ataraxiae created an easy-to-access dashboard summarizing all the need-to-know information that allows anyone to quickly understand GR15. We think this dashboard will be helpful to future users of the Gitcoin Grants protocol as well.
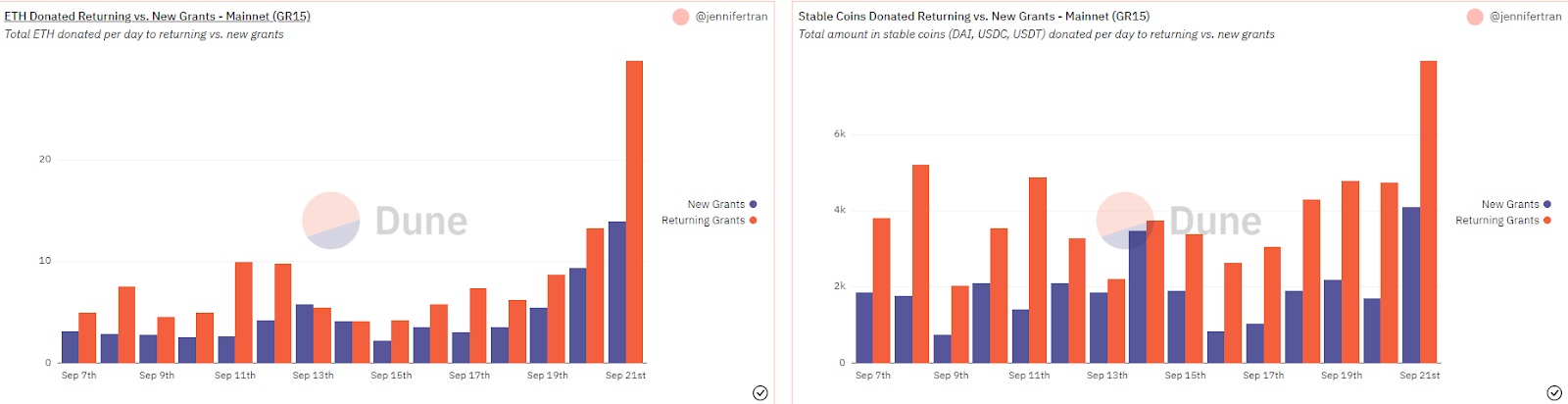
Another entry that impressed us was by user jennifertran, who also created a dashboard about GR15 and also included analysis with key takeaways in plain language as well as data.
There were seven individual dashboards that were awarded prizes totaling $1500 - they are all great examples of the kind of shareable insights that can help to understand and operate Grant rounds.
Human incentives
The top entry in the Human Incentive category was an app that scraped the Github repository for each contributor and generated a score for account quality. This was then correlated against several metrics of their performance in the grants round. This approach could be used as a simple Lego that can be added to the Gitcoin grant review process by Gitcoin and other public goods funders, with particular relevance to grants rounds where the applicants have a technical track record. The submitted version could easily be developed for production and seems likely to improve the assessment of Gitcoin grants. The creator of this approach will join us in the upcoming Twitter Space on Wednesday the 16th.
Other top entries created an app for automating grant reviewing and predicting grant outcomes from the grant description. These could also become components of Gitcoin’s review protocol.
There were six projects awarded a prize in the Human Incentives category - each one contributed some novel idea for how to improve Gitcoin grant reviewing! The total prizes totaled $7500.
Sybil Slayers
The top Sybil Slayer team created an algorithmic Sybil-detection composed of four distinct approaches:
- Bulk transfers pattern mining
- Bulk donations pattern mining
- Sequential behavior pattern mining
- Asset-transfer graph mining for slaying Sybil.
They synthesized these components into a single tool that can be used to detect Sybils. They also extended their work to contribute to detecting grant fraud. It was great to see an independent group of analysts create something that can plug into the Gitcoin defenses - this is exactly what we mean by “composable tools” that will support Gitcoin’s protocol transition. One highlight of this analysis was the detection of a 188-node “snake” network of Sybils, whereby 188 seemingly independent wallets were revealed to have coordinated their activities in order to manipulate quadratic voting. Members of this team will also be joining us in the Twitter Space on Wednesday the 16th.

Another highly rated Sybil Slayer created a pipeline for investigating the time series properties of grant contributions using clever data collection and analysis techniques. They created a notebook to easily share the data analysis with other analysts in a way that can be applied to other datasets in the future. It was great to see the user analyzing the correctness of their own approach and proposing alternatives - this is just the kind of ethos that will boost the OpenData community.
Ten Sybil Slayers were awarded prizes totaling $10,000.
Voting for Winners
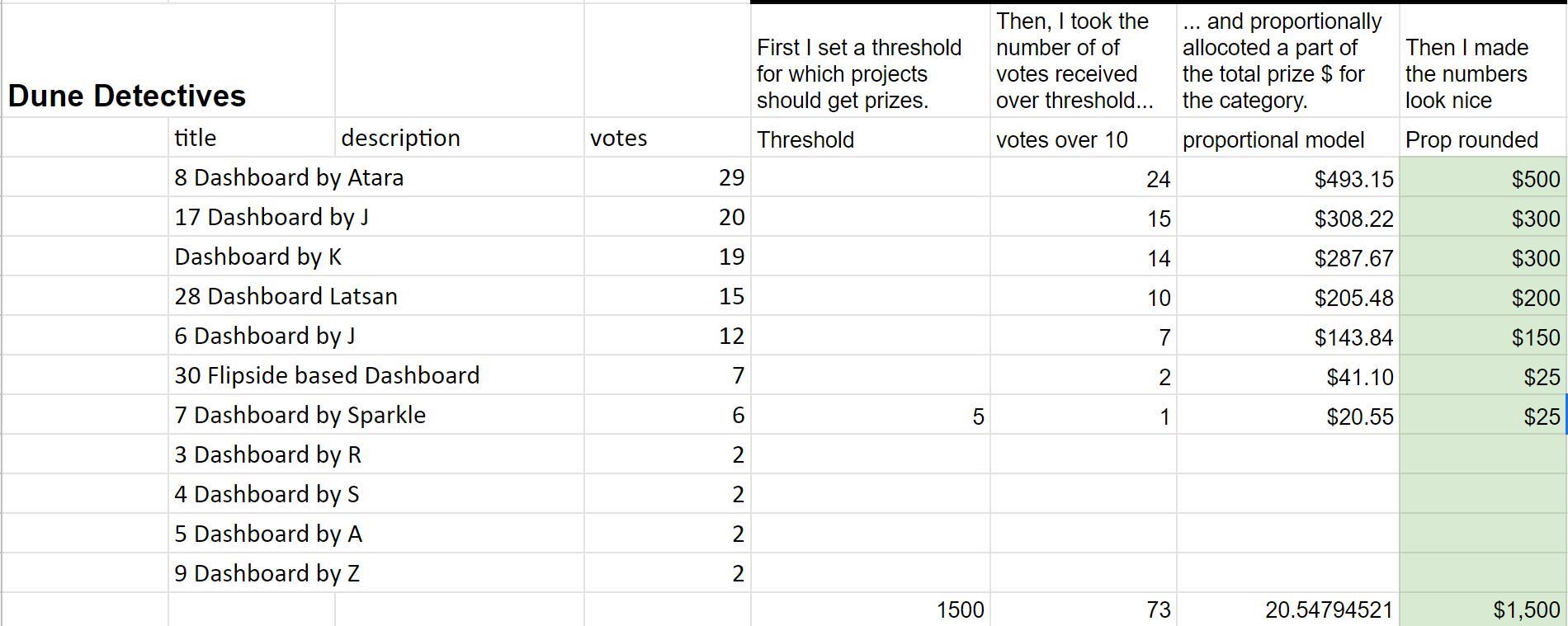
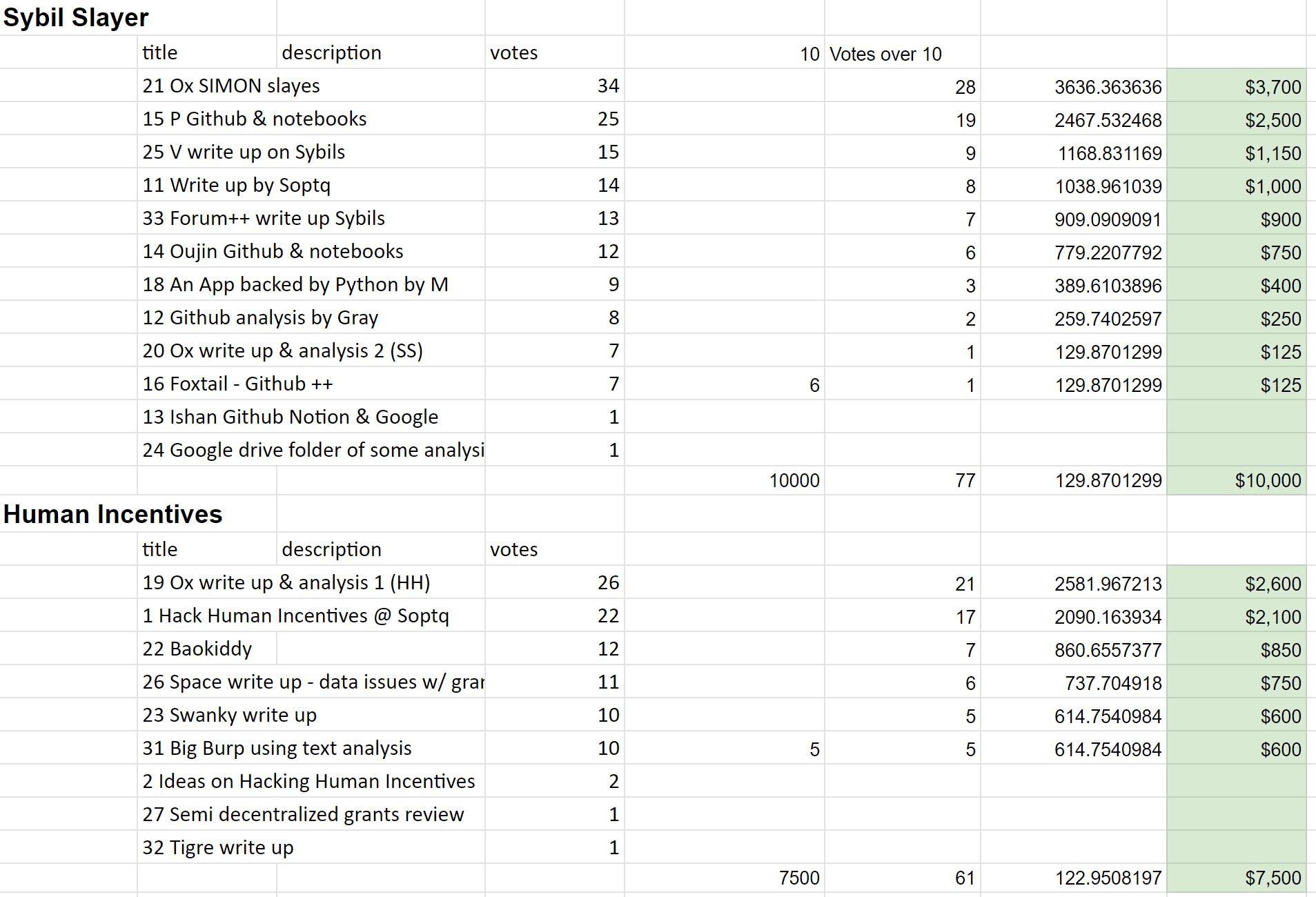
Quadratic Voting was used to choose the winners and to allocate how much of the prize money they would receive. Our judges consisted of 5 members of FDD for this first event. Each received an allocation of quadratic vote credits for each competition category. The number of votes each judge was asked to allocate was just shy of being able to put all their votes onto any one winner, thus pushing them to consider 2nd and 3rd favorites as they used the remainder of credits. This forced an effect similar to ranked-choice voting. The output of this was a list of preferred projects and the votes received.
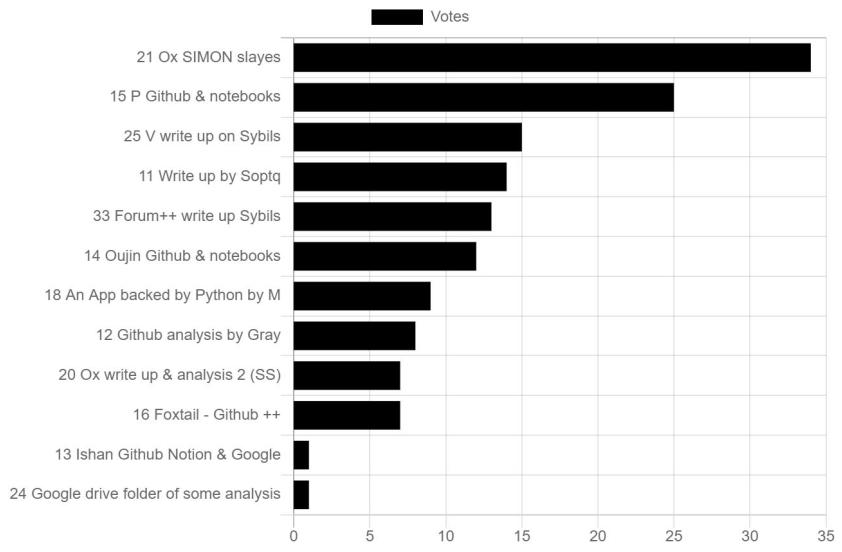
Next, a threshold was set for each category. The basic principle used was that any project with a quality and effort level we wanted to encourage to participate in future rounds would receive something. The amount received would be proportional to the number of vote credits they received over the threshold. We then made some quick rounding and subjective decisions to finalize the final payouts.
What’s next?
The hackathon was a great way to kick off the OpenData Community. It demonstrated unambiguously that high-quality data and software tools can emerge from a decentralized community of data analysts and software developers. So from here, we will be supporting the already growing community and will collaborate with the community to build some structure in the DAO. We are committed to fighting recentralization in all its forms and need your help.
Whether you are a data scientist, a community builder, a discord degen, a project developer, or someone who wants to make sense out of web3 data with recommended solutions that respect the decentralization ethos of Ethereum and web3 - please drop in and help build a more open data future.
There are at least a couple of ways to get involved with the OpenData Community:
-
Join our Twitter Spaces on 16th November at 7am (Pacific time): https://twitter.com/i/spaces/1MnxnpbqmdkGO
-
Please drop into the Discord : Discord
-
Or check out and add to our landscape and plan here: OpenData Community · GitHub
You can also be one of the first to follow the community on Twitter:
There will be more hackathons coming up in the future too!
Many thanks to @DisruptionJoe @j-cook for their work on this write-up, to the FDD for their enthusiasm as we begin to decentralize ourselves, and of course to all the hackathon contestants.