In our efforts to mitigate collusion and make QF more effective, we’ve been exploring the concept of Plural QF. To illustrate this, let’s consider a comparison between Plural QF and Normal QF.
The Setup
Let’s consider
- 2 projects with
- 7 contributors each
- and a $100 matching pool
The Results
Under Normal QF, our projects received:
- Project #1: $140
- Project #2: $129
Under Plural QF, our projects received:
- Project #1: $154
- Project #2: $115
Let’s break it down.
Normal QF

Contributors donated to Project #1 as follows: 5, 10, 0, 20, 0, 10, 50. This resulted in:
- Funded amount: $95.00
- Matched amount: $45.31
- Total: $140.31

Similarly, Project #2 received donations as follows: 5, 15, 5, 5, 20, 10, 15. This resulted in:
- Funded amount: $75.00
- Matched amount: $54.69
- Total: $129.69
Plural QF
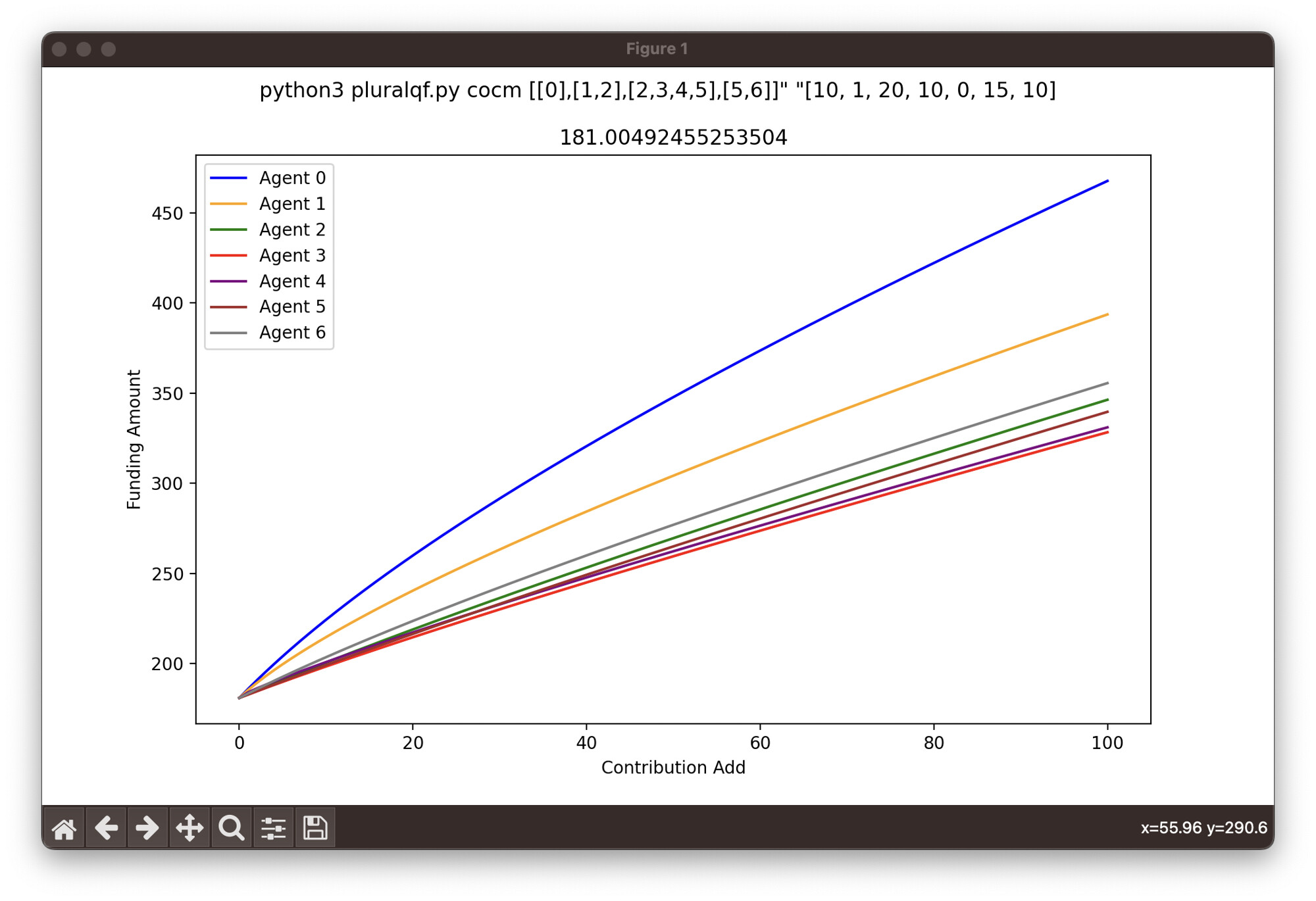
We simulated a social graph for the same number of contributors. Using the COCM model and running a Python script, we obtained the following results:
assume Social Graph
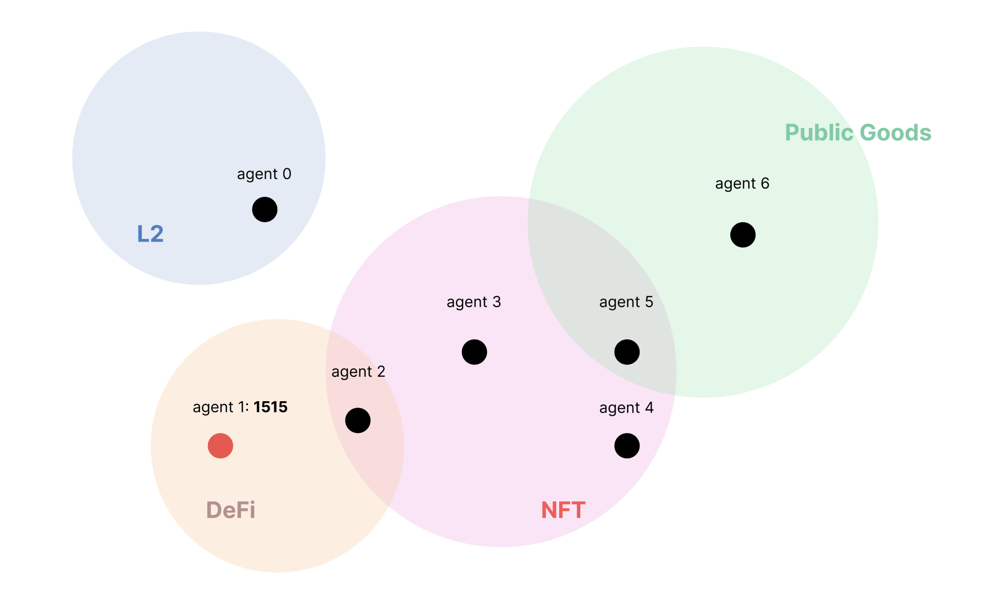
$ python3 multipleproject.py cocm "[[0], [1, 2], [2, 3, 4, 5], [5, 6]]" "[[50, 5], [5, 15], [10, 5], [0, 5], [20, 20], [0, 10], [10, 15]]"
→[289.7424515457382, 199.92969686897504]
calcurated with plural-qf/multipleproject.py at main · tkgshn/plural-qf · GitHub
Project #1:
- Funded amount: $95.00
- Matched amount: $59 (calculated using the COCM model)
- Total: $154
Project #2:
- Funded amount: $75.00
- Matched amount: $40 (calculated using the COCM model)
- Total: $115
More Info
For a closer look at our simulations and calculations, check out
- simulation code: plural-qf/differentamount_Simulation.py at main · tkgshn/plural-qf · GitHub
- more: how to implement wtfipluralqf update - tkgshn
To understand how Plural QF could influence individual contributors, consider this: if you’re in a good social position like Agent0, increasing your contribution amount can have more impact than a similar increase from an agent in a less advantageous social position.
Comparison with RetroPGF and GR11 (Infra round)
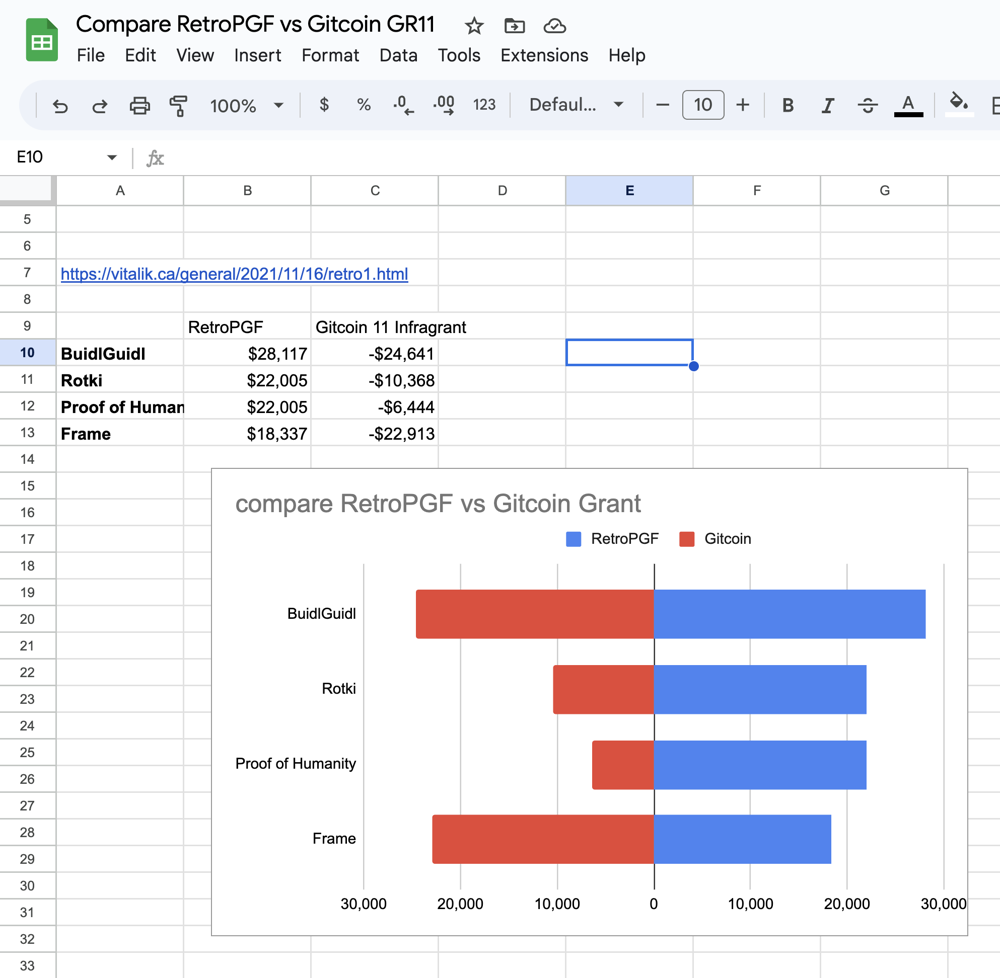
it’s compared our findings with the data from Optimism’s Retro Funding Round 1. Vitalik Buterin observed that the retro round had less variance, the winners were more well-known projects, and there was more focus on infrastructure as opposed to user-facing projects. Here are our visualizations of these comparisons:
VitalikButerin said below in https://vitalik.ca/general/2021/11/16/retro1.html
It is my own (admittedly highly subjective) opinion that the retro round winner selection is somewhat higher quality
The retro round was low variance
The retro round winners are more well-known projects
The retro round focused more on infrastructure, the Gitcoin round more on more user-facing projects
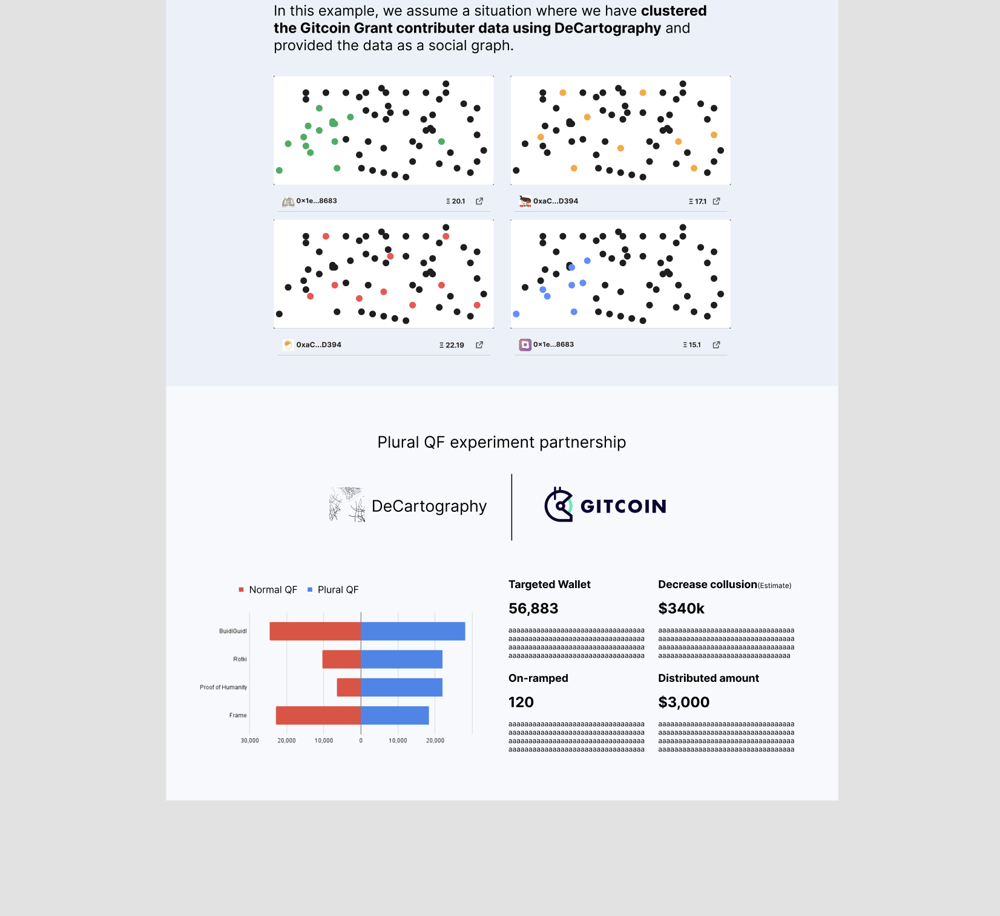
maybe DeCartography’s future is likes this
Let’s continue the conversation around improving QF through Plural QF. Your thoughts and insights are always welcome.


