The Fraud Detection & Defense workstream (FDD) aims to minimize the impact of fraud on our community. In this post, we highlight the quantitative data behind GR14 and the qualitative decisions made. We also describe the reasoning behind any subjective judgments along with making recommendations to the Grants Operations team and Stewards for new policy revisions to match changing circumstances.
TL:DR
- Sybil Defense
- Sybil attacks are way up!
- Contributors - 16,073 / 44886 contributors
- Contributions - 167,988 / 623,400 contributions
- Fraud Tax Mitigated - $879k (25.4%)
- A large portion is “airdrop farming”
- Follow up work to analyze human evaluations & overfitting potential
- Less human evaluations = smaller dataset = less reliable
- Passport providing new opportunities soon!
- Sybil attacks are way up!
- Grant Eligibility
- Reviewed over 1,000 new grant applications at a lower cost than GR13
- Over 30% decrease in the cost per review
- Increased appeals time to under a week
- Need to decouple main/eth round from side rounds
- Policy Update Recommendations
Sybil Defense
Sybil defense for Gitcoin consists of prevention, detection & mitigation. Users must verify accounts including Github, Google, Proof of Humanity, BrightID and others to earn a “Trust Bonus”. The Trust Bonus allows users to increase the effect of their donations signal to the matching pool from the standard 50% to as much as 150%. This rules-based exclusive logic methodology is the prevention technique which is driven by the product team.
FDD primarily handles sybil detection & mitigation. Prevention techniques require a way to determine effectiveness. This is dependent on the availability of a data set of known sybil accounts. This list was created and is continually updated via the FDD detection process.
The primary Sybil Account Detection (SAD) model used in production is operated by the Data Operations squad. They are responsible for the end to end Anti-Sybil Operational Processes (ASOP). Humans evaluate random samples of accounts to statistically validate the model and to identify new behavioral insights which can be built into new “features” or inputs to the machine learning model by the Community Intelligence squad.
.
Sybil Detection
High level stats:
- Contributors - 16,073 / 44886 contributors
- Contributions - 167,988 / 623,400 contributions
- Fraud Tax Mitigated - $879k (25.4%)
This grant round saw a notable increase in airdrop farming relative to attacks with the specific intention of diverting funds from the matching pool. Though the intention is different, the effect is the same.
Squelched accounts are no longer eligible to affect matching pool outcomes. During GR14, the number of squelched accounts was 7.8x as many as we saw in GR13 and 2x as many as we saw in GR12. Deeper analysis is being done to check for errors, but initial statistical validation shows that these numbers are within expectations.
Airdrop Farming
GR14 brought a significant increase in the number of users who participated in airdrop farming. View more details on the linked governance post, but here are the highlights:
- It is always unacceptable for a user to make donations from different/multiple user accounts to a single grant within a QF round
- Accounts which participate in a sybil attack, sybil donations, or known sybil behaviors may be squelched
- Airdrop farming by a single actor using a single account is not a sybil behavior
- Ignorance should not be allowed to be used as an excuse.
Overall, Gitcoin should never allow any person to make donations from multiple accounts to a single grant. If we do not enforce “one person, one donation”, we will quickly see the legitimacy of the system overrun with behaviors that exploit it, whether knowingly or unknowingly.
Human Evaluations
Although human evaluations are critical for removing bias and improving the sybil account detection algorithm’s learning rate, the stewards elected for FDD to reduce this effort.
- GR14 = $1.00/eval | $3000 for 3,000 evaluations by 10 contributors
- Restructuring of the team
- Lowering the amount of evaluation while increasing the quality
- Reducing the cost per review by almost 30%
- GR13 = $1.42/eval | $17,050 for 12,000 evaluations by 37 contributors
- Second time “sybil hunters” improve quality
- Established systems for recruiting and executing
- Focused on improving quality while lowering cost/eval
- Brought out the meme culture in FDD
- GR12 = $4.39/eval | $26,350 for 6,000 evaluations by 25 contributors
- Opened up participation to all GitcoinDAO contributors
- First inter-reviewer reliability analysis to improve inputs
- Focused on improving quality of data entering the system
- Higher cost to get the inputs right and attract new people to participate
- GR11 = $1.25/eval | $1,750 for 1,400 evaluations by 8 contributors
- First DAO led evaluations - Probably higher cost due to expert time from core team and SMEs for help
- Fairly low quality, little training done
Incidence & Flagging
GitcoinDAO GR14 Statistical Review
A total of 35.8% of the Gitcoin users, representing 26.9% of the contributions, were flagged during GR14. The Sybil Incidence during this round is significantly higher than GR13, with an estimate of being 1.6x higher (lower / upper boundaries being between 1.2x and 2.0x)
The Flagging Efficiency was 162.1% (lower boundary: 142.9% and upper boundary: 187.2%) which means that the combined process is over-flagging sybils compared to what humans would do.
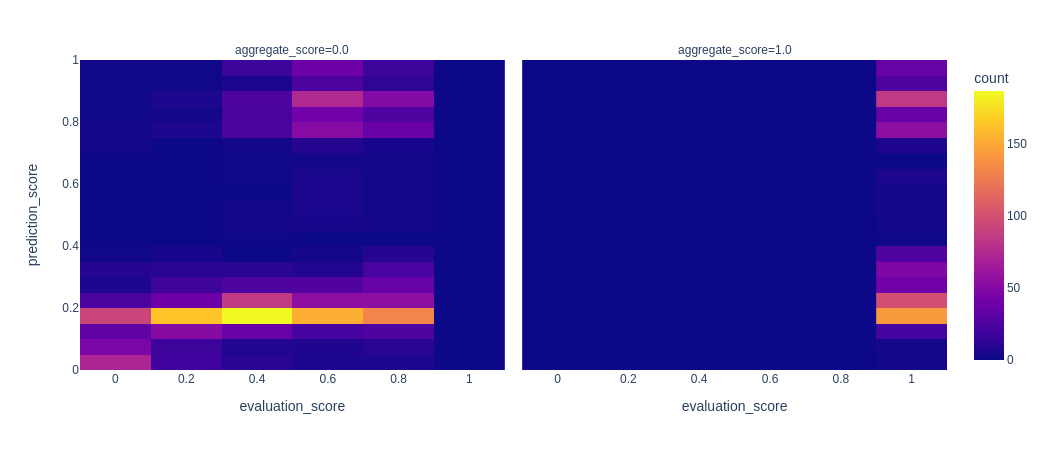
Please note that some metrics are followed by a confidence interval in brackets, in keeping with statistical analysis practices.
GR14
- Estimated Sybil Incidence: 22.1% +/-3% (95% CI)
- Estimated # of Sybil Users: 9916 (between 8585 and 11247 w/ 95% CI)
- Number of Flagged Users: 16073 (35.8% of total)
- Number of flags due to humans: 641
- Number of flags due to heuristics: 6074
- Number of flags due to algorithms: 9358
- Total contributions flagged: 167988
- Estimated Flagging Per Incidence: 162.1% (between 142.9% and 187.2%)
GR13
- Estimated Sybil Incidence: 14.1% +/-1.3% (95% CI)
- Estimated # of Sybil Users: 2453 (between 2227 and 2680 w/ 95% CI)
- Number of Flagged Users: 2071
- Number of flags due to humans: 951
- Number of flags du to heuristics 1067
- Number of flags due to algorithms: 53
- Total contributions flagged: TBD
- Estimated Flagging Per Incidence: 84%
GR12
- Estimated Sybil Incidence: 16.4% (between 14.5% and 18.3%)
- Number of Flagged Users: 8100 (27.9% of total)
- % of flags due to humans: 19.4%
- % of flags due to heuristics: 34.7%
- % of flags due to algorithms: 49.2%
- Total contributions flagged: 115k (21.7% of total)
- Estimated Flagging Per Incidence: 170% (between 118% and 249%)
GR11
- Estimated Sybil Incidence: 6.4% (between 3.6% and 9.3%)
- Number of Flagged Users: 853 (5.3% of total)
- % of flags due to humans: 46.1%
- % of flags due to heuristics 14.3%
- % of flags due to algorithms: 39.6%
- % of total contributions flagged: 29.3k (6.6% of total)
- Estimated Flagging Per Incidence: 83% (between 57% and 147%)
The over-flagging was caused because of the ML model being biased to heuristics due to a weighted combination of:
- a drastic reduction on the number of human evaluations during GR14
- an increase in sybil incidence
- an increase in the relative count of users being flagged due to heuristics
As per other rounds, Sybil Incidence seems to be higher during the beginning of it. However, we did have a large jump on the final evaluation set that was not qualitatively detected on other rounds.
Opportunities
Human Evaluations
During the budgeting process, the desire to cut down on human evaluations was pushed without any scientific rigor behind why. As a cost saving move it did save GitcoinDAO $10-15k for the season. It came at a cost of 4,833 flags which are less certain than they could have been meaning there is a larger possibility of false positives.
Conducting an extensive review of human evaluator training, heuristic aggressiveness, and potential for oversensitivity will give us clear answers before the next budget evaluation period. The increase is enough to warrant investigation, but not likely to have made a material difference on the outcomes during GR14. A review from Blockscience can be found here.
Better Data Access = Lower Manual Review Cost
With FDD having access to Metabase this round, we were able to pull custom reports we had previously been unable to consider. This led to a storm of new reporting and models for identifying potentially sybil behavior.
By creating reporting that quickly identified lists of users which match a pattern such as repeated donations to the same grant, not just a few times, but MANY times, we were able to accomplish much of the human evaluations task of developing behavioral insights. Additionally, this allowed us to lower the manual work of sybil hunting as these insights provided optimal prioritization for the task.
Profiles of Attacks
With each new behavioral insight, our ability to accurately detect specific motivations of attackers increases. These varied motivations include airdrop farming, grant owners running a large number of sybil accounts, and even instances of payments to influencers to announce that they think the grant is likely to do an airdrop to donors.
A better understanding of the individual motivations allows us to investigate unique signals pertaining to one type of attack. In the future, we hope to be able to estimate the impact, cost to the community, and cost of the attack in relation to the specific incidence.
Passport Future
During GR14, we saw nearly 15,000 setup their Passport. Passport builds on the prevention techniques of the Trust Bonus, but also provides an ability to move FDD away from using any Personally Identifiable Information (PII) and instead use only publicly available information in the user’s Passport.
Our first opportunity to improve is by assisting the Passport team in optimizing the Trust Bonus score. An optimal weighting would create Trust Bonus scores with the most separation between human labeled sybils and non-sybils. After searching through 37 Billion combinations across 2 computers and spending a total of 6 days computing trust scores, we found it. Now we can help the Passport team to improve the prevention part of sybil defense to minimize the need for detection & mitigation techniques.
Grants Intelligence Agency (GIA)
Grants Eligibility Reviews
The GIA handles all operations & execution of tasks relating to ensuring grants have an equal access to being on the platform and included in the main/Ethereum round. GIA is responsible for
-
Approvals - Assessing New Grant Applications (Platform & Main Round Eligibility)
-
Tag Requests - Routing Requests for Ecosystem & Cause Tags
-
Disputes - Re-reviewing grants flagged by the community
-
Appeals - Re-reviewing grants denied eligibility and escalating when appropriate
-
Policy - Identifying gray areas and novel situations & recommending policy review
-
Investigations - Deep dives into suspicious grants to document types of fraud
These responsibilities ensure that grants on the platform are not in violation of codes of conduct and that grants in the Main/Ethereum round are in line with community norms.
When the stewards ratify the round results, they are also approving the sanctions adjudicated by the FDD workstream.
Full transparency to the community is available at:
- Grant Approvals - When new grant applications are received
- Grant Disputes - When a grant is “flagged” by a user
- Grant Appeals - When a grant denied eligibility argues an incorrect judgment
*User Actions & Reviews is currently in “open review” allowing for select participation to stewards due to sensitive Personal Identifiable Information (PII) data and potential vulnerability to counter-attacks.
Additional transparency for all flags is provided at @gitcoindisputes Twitter.
Enhanced communication with our grantees and community via our GIA Twitter account was a goal during GR14. The community was updated with notifications and status for grant appeals, disputes and other general information.
Review Metrics
In GR14 we had a refined review process in place and documentation available for the reviewers. The trusted seed reviewers were assigned small PM tasks during GR14. Some filtered spam grants on the platform because we needed to remove their tags to keep the Ethelo review lists clean for the round owners to review. Other trusted seeds communicated with round owners and/or requested information from the grant creators when needed.
A birds eye view of the progress in grant reviews:
GR14
- $3.30 cost per review & 2.7 average reviews per grant (cost/review is down 39%!)
- Completed over 3000 reviews on 1100 Grants (Estimate)
- 7 Reviewers / $10,260 (4 approvers -Joe, Zer8, David, Bfa)
- NEW! Grant reviewer quality score:
- New reviewers: 8.6/10 (Migi, Prof, Roman, Vlad)
- Trusted seeds: 9.3/10 (Anna, Emmanuel, Iamdgold)
- We introduced a bonus based on the quality score that lead to an increase in review quality and lowered the cost/review
- First line of review of Ecosystem & Cause round tags
- Finished Ethelo integration for solving disputes. The users have different weightings based on their experience in grant eligibility. This will allow us to gather data and learn while hearing the voice of our community.
- Saved over $80K in matching funds via grant investigations in GR14
GR13
- $5.38 cost per review & 2.3 average reviews per grant
- 2,300 Reviews / 1000 Grants (Duplication error made this an estimate)
- 7 Reviewers / $12,380 (2 approvers -Joe, Zer8)
- The main focus was balancing between high quality reviews and number of reviews
- Working towards Ethelo integration, senior grant reviewers => Trusted seed reviewers
GR12
- 8 Reviewers / $14,133 (1 approver - Joe)
- Experimented with two grant review squads
- Recruited more community members and started to focus on quality
GR11
- 7 Reviewers / $10,000
- Opened up to the community even more
- Multiple payments models tested
GR10
- 3 Reviewers / NA cost
- First time using outside reviewers
- FDD did not have a budget yet! Volunteer help.
Grants Disputes & Appeals
Appeals and disputes were solved as they came in during GR14. Earlier seasons the disputes were solved only at the end of the round and appeals could take weeks. Both processes are moving closer to real time processing.
FDD processed approximately 42 requested appeals: 22 denied, 10 approved, and 10 transferred to Ecosystem/Cause round hosts. Crowdsourced flagging of grants led to 40 grant disputes: 13 grants were denied eligibility, 3 grants were ineligible for matching, and 34 were left active with the dispute being found as not having evidence to deem the grant as ineligible.
We had a few appeal requests for denied tags in GR14. Some of these were processed by the FDD before it was recognized they should’ve been immediately transferred to the appropriate Ecosystem/Cause Round Host.
The most time consuming part of the appeals is accumulating enough FDD votes to gain a clear signal. In the future we will strive to grow/decentralize the group evaluating appeal requests but this will likely take cross-workstream cooperation between PGF, FDD and GrantOPs to ensure all interests are represented. GR14 showed us the public will benefit from increased Grantee communication about the applicability of the appeal process.
The appeal process offered to Grantees has become an efficient and fair flow. Most appeals and disputes were processed in just a few days and everything was processed on schedule for the end-of-round. We engaged legal experts from LexDAO to make the Gitcoin Appeal process even more solid during GR14. We look forward to learning from, prioritizing and integrating LexDAO’s feedback going into GR15. We are still researching and evaluating the best way to process appeals based on Novel Situations that will not require a Steward vote.
Policy Recommendations
In this section we will outline the areas where we believe the community would benefit from more clear policy. It has been discussed between workstreams that Grants Operations within the Public Goods Funding workstream should drive the policy updates for the Gitcoin Community’s Main/Eth rounds and how that connects to side rounds.
At this point it is unclear if FDD should drive the Gitcoin UI eligibility, what one might think of as the platform eligibility, or if Grants Operations should drive this as well.
In GR14, here are a few situations where there was a need for more clear policy:
A clear definition of Quid Pro Quo
Examples include the use of POAPs mid-round by Lenster causing noticable increase in donations (as reported by the community, an analysis by FDD is in backlog). Another grant offered a discord role.
In the past, we had found that the non-transferrable trusted seed for commons stack was eligible because the group which could receive it was exclusive and pre-determined. It was encouraging their already established followers to participate, but not paying for new followers. POAP has been in the rounds for a long time. While not commonly known to be transferrable, the argument has been to allow them.
Clarity on requirements to be considered open source
Many projects claim to be open source, but only have a part of their code available. Some have no code publicly available, but say they intend to later.
A better definition of public good for the main round
While the mechanism is supposed to let the community decide, we know that a large community with strong marketing can skew the results. What would we need to know to understand if a marketing community is actually positive sum? How might we continually fund large infrastructure plays while not allowing partially public goods with large communities to continue drawing funds forever?
Better understanding of whether the community needs the funding
The no token rule which says any community with a token or any advertising of a future token is not allowed is directly at odds with many of the infrastructure and DAO grants. Community feedback continually points at “does the grantee need the funding”. This is objectively hard to measure.
Technical separation of Gitcoin community’s main/ETH round from side rounds
Another problem that should be cleared up with the grants 2 infrastructure is the side rounds ability to override FDD judgements. Due to the main round being coupled to the side rounds, this means grants which don’t meet the main round criteria are let in because the side round wants to include them. We should look to empower the gitcoin community and the ownersof the side rounds to more accurately set criteria definitions which can be upheld.
Opportunities
Improved Collaboration
The coordination and communication between GIA, Grants Ops, and Support squad needs to continue to improve for matters related to grant eligibility.
A few areas for improved collaboration include:
- Better communication to denied grants could reduce the number of inbound support requests
- A clear boundary between FDD platform & main/ETH round approvals and Grants Ops approval of grant inclusion in Ecosystem & Cause rounds might improve all stakeholder’s ability to assess current status of grants.
- An improved workflow for unclear policy changes due to gray areas, changing environments, and novel situations could lessen uncertainty during the rounds. Having a clear boundary between FDD adjudication systems and Grants Ops ownership of program policy could improve reviewers ability to make decisions, and improve communications with grant owners, support team, and the community.
Scaling Grant Reviews
Over 400 people from the Gitcoin community participated in a test to assess viability of permissionless reviews using Ethelo to judge disputes. Results comparing the results from Ethelo to those of our expert reviewers will be available in a few weeks. Additionally, data from the experiment will be used in the simulations built by the Season 13 Rewards Modeling squad.
By using the Ethelo system in the future, a cost savings is likely. Crowdsourcing reviews from our community not only lowers our cost per review, but also decentralizes the subjectivity inherent in the process.
Grant investigations
First principles based investigation of grants saved the community $80k in improperly allocated matching funds. This is over 11x the funds spent on investigations.
Grant investigations also led us to the discovery of old grants from GR8, GR9, 10, 11 that were at one point eligible, but currently violated our code of conduct (they changed their purpose, got involved in QPQ, fraudulent activity, raised over 500k $, etc). We generated detailed reports for all the grants that required an in depth investigation and were later deactivated.
Conclusion: FDD Statement on GR14
The launch of Passport was the first step towards a Grants 2 future. Clearly aligning workstream goals with either Protocol Adoption or Program Success will help to avoid confusion as we launch the Round Manager and Grant Hub.
Another important step will be to commit to public conversations around prioritization of work. Our community, especially stewards, will require high levels of context to participate in decision making in a meaningful way.
Here is an example:
Our ability to make sybil prevention work as intended will depend on FDD’s sybil detection being a priority for the community in the near term. The tradeoffs of doing one or the other may be in contrast to the primary goal of quadratic funding.
Imagine you have 100 people who would like to participate in a game. You want to make sure that each of them is a unique human behind the account. By requiring x number of verifications, you limit the game participation to only those who are willing and able to take the time to gain those verifications.
Let’s say only 20 of 100 get fully verified and another 20 are partially verified. Fake (sybil) accounts make up 20 of 100. In a game intended to give more weight to the voice of the many rather than the wealthy, you just concentrated power in the hands of 20 people. Another 20 received partial credit. All because keeping 20/100 fake accounts out was important.
Detection & mitigation handles this problem differently. Rather than using exclusive logic, it allows all 100 to participate. Then it detects which ones are most likely to be fake and removes their points. Let’s say the system detects 15, but 2 of these are false positives. This means there were 7 false negatives which it didn’t catch.
Which system is closer to the goal of empowering the many over the wealthy?
The one where 20/100 are given full voice and another 20 are given partial rights. The rest are simply not allowed to play.
- Do you have any assurance that the 40 you have given any voice to are not fake accounts without doing the work to understand how to identify fake accounts?
- Or is it the system that allowed 100/100 to participate and mitigated the fake account issue in a different way allowing 85/100 to participate?
Disruption Joe, Workstream Lead
FDD: @zen @Sirlupinwatson @ZER8 @David_Dyor @omnianalytics @vogue20033 @tigress @kishoraditya