We would be lucky to have that! Unfortunately, it turns out that there is no one analysis that says for sure that user is sybil. Instead, we have many of these “legos” that say a user is likely sybil via a combination of multiple signals.
- if a user is triggering specific known combinations
- If they pass a threshold score from an ML model. The model looks at all these outputs against our “Thor & Loki” datasets (read: for sure not sybil & for sure sybil) We then choose a threshold whereby we deem the users most likely sybil. This method aims to minimize false positives even over avoiding false negatives.
Here is a comment from a past budget discussion where I explained how any one signal is not sufficient on its own. [Proposal] FDD Season 14 Budget Request - #12 by DisruptionJoe
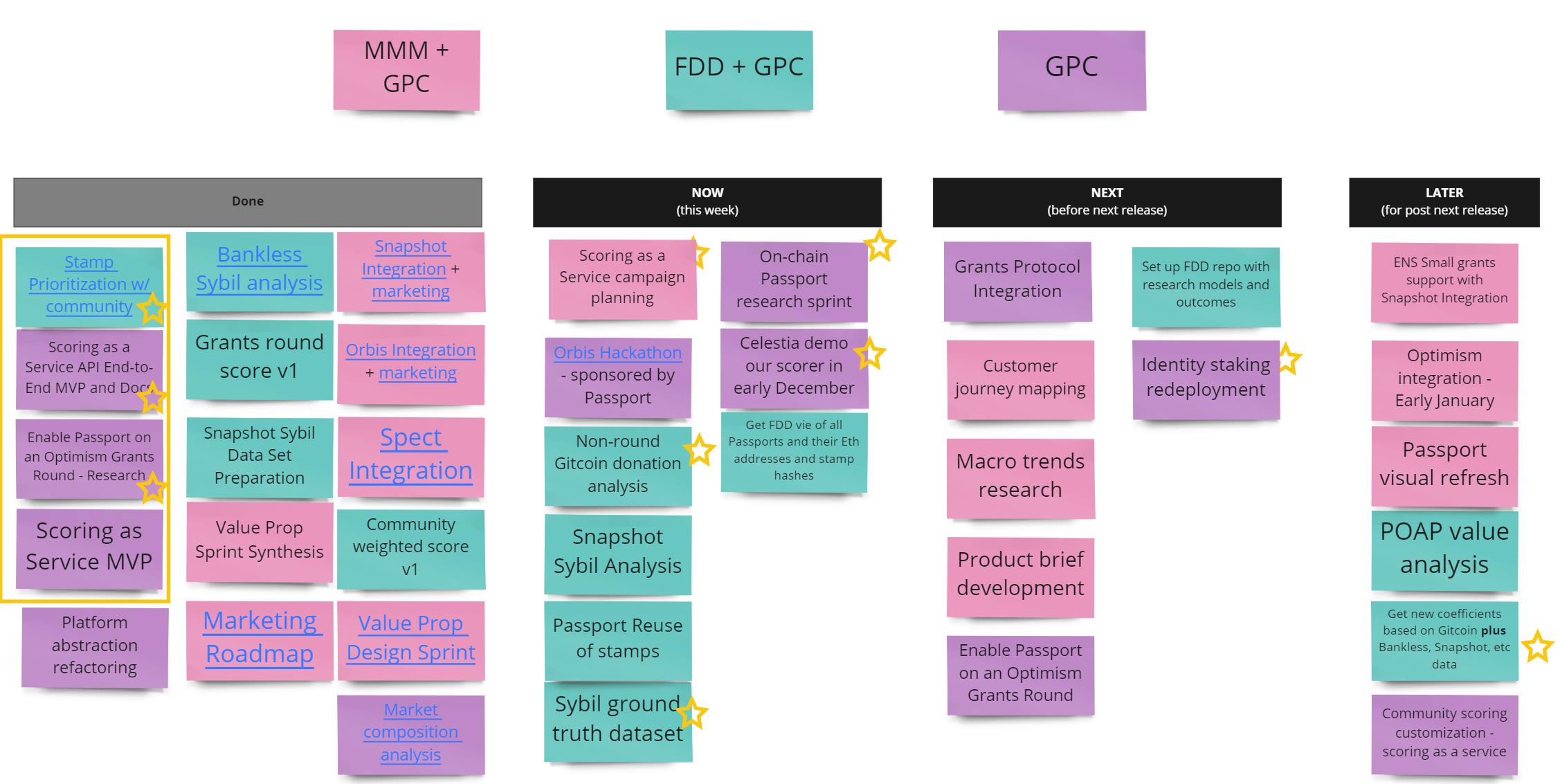
My team at FDD is working with the GPC Passport team to do a few specific things.
- In November we provided 4 models for scoring they could use for preventative sybil defense. These one score to rule them all models aren’t as good as customized scores per use case, but it is more scalable and we are studying how well it works.
- We performed analysis to estimate the effectiveness of the Snapshot & Bankless integrations and fine new “legos” specific to their use cases.
- We created a topology model and recommendations for which stamps to prioritize to solve sybil resistance. The GPC team is thinking about UX and has final say for what is prioritized. At this point, they seem to be leaning towards a steward voting model to determine which stamps are included. (I believe this is a mistake because the purpose of passport is to solve sybil resistance, not to be a popularity contest, but we hope stewards will take FDD recommendations.)
- We are documenting and building pipelines for best way to extract data from ceramic and join with other data such as onchain signals.
Here is a view of priorities from the cross-functional passport pod priorities for this season.