Hi all! Joel from the Q.E.D. program here. In this post, I’ll share some experiments we did to understand how past voting/ funding outcomes change when we use plural QF algorithms.
Also – if you haven’t checked it out yet, here’s a reminder to check out our polis conversation on QF!
For these experiments, we looked at the snapshot quadratic vote held to determine which beta funding rounds would be “core rounds” (which received more support from Gitcoin) and which would be community led (more info here).
This is a cool dataset to look at because, unlike with normal funding rounds, it’s easy to make an argument for what the outcome of this vote “should have been” in hindsight. That’s because we now know how many donations each beta round got. If you believe that Gitcoin should directly support the rounds that draw the most attention/donations, then measuring the success of the snapshot vote is easy: you can go down the line of core rounds selected by the snapshot vote and ask: "ok, did this round actually get much attention during beta? If it did, then the snapshot vote did a good job at correctly predicting a popular round, but if not, the snapshot vote might’ve been sub-optimal. Likewise, if a round that didn’t get a lot of attention in the snapshot vote ended up getting a lot of donations, that might’ve been another missed sub-optimality: perhaps that round should have been a core round. And most importantly, we can ask how changing the voting algorithm effects the quality of the results.
(by the way – my code is in this notebook, for anyone interested)
1. Comparing snapshot vote results with actual donation outcomes
Like I said above, this snapshot vote is interesting because you can directly compare its results with the actual donation amounts the beta rounds recieved. Below is a graph showing, for each round, its share of the snapshot vote and what percent of donations it got in beta. When calculating the percent of donations, I first normalized by the size of the matching pool, since that felt like an extraneous factor that would also effect donation amounts.
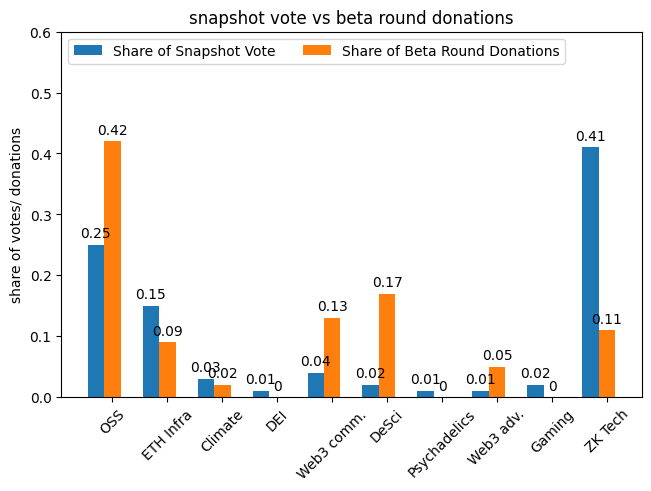
As you can see, the snapshot vote was relatively close for some rounds (ETH Infrastructure and Climate) but fairly askew for others (OSS, DeSci, and ZK Tech). In fact, DeSci, which was not selected to be a core round in the snapshot vote, ended up getting more donations than ZK Tech, front-runner in the vote (after normalizing for the size of the matching pools).
In my last update, I talked about using a metric inspired by Earth Mover Distance (EMD) to compare these types of outcomes. Here, you can think of the EMD as the amount of “voting mass” that you’d need to move to get from one outcome to the other. For us, a lower EMD is better. The EMD between the snapshot vote and the actual beta round donations is ~0.44.
Now, we’ll explore how the outcome would’ve changed if we had used some other QF variants instead. By the way – despite the snapshot vote being called a vote, they actually used QF, not QV. So it’s very easy to just plug in other QF algorithms instead.
2. Using pairwise match
Pairwise match was first described by Vitalik. The basic idea is that whenever you do QF, you can break down the matching funds into chunks, where each chunk corresponds to a unique pair of agents and depends only on the amounts that those two agents donated. So, if two agents seem to be colluding, you can take that pair’s “chunk” of the matching funds and reduce its size.
Here are the results when we use pairwise match on the voting data:
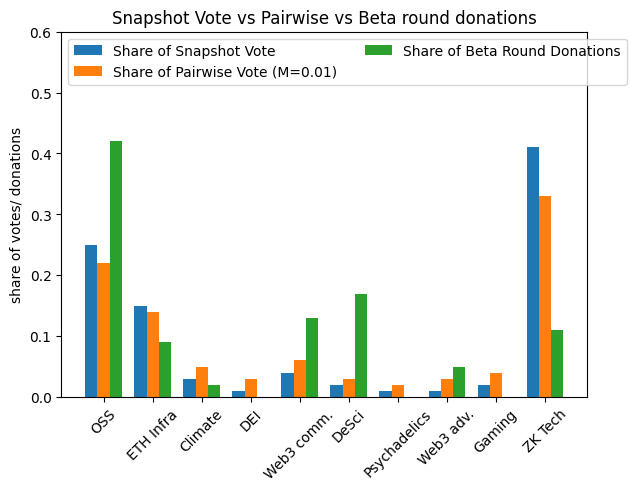
Here, the pairwise results are sandwiched in between the normal vote results and the actual donation results, so you can compare all three. Pairwise moves results in the right direction for five of the 10 rounds, and achieves an EMD of 0.42 – so a bit better than the normal quadratic vote, which had an EMD of 0.44.
By the way, you might notice the “(M = 0.01)” in the legend – M is an internal parameter to pairwise match. You can see a graph comparing pairwise results for different values of M in the notebook I shared.
3. Cluster Match via voting profiles
The idea behind cluster match is to first group agents into clusters, and then put agents in the same cluster “under the same square root”. In other words, each group of similar donors get treated as just one donor. I was curious about using this algorithm and defining clusters just based on the set of rounds someone voted for – so, e.g., everyone who voted just for ETH Infra and Climate under the same square root, and so forth. The results are below.
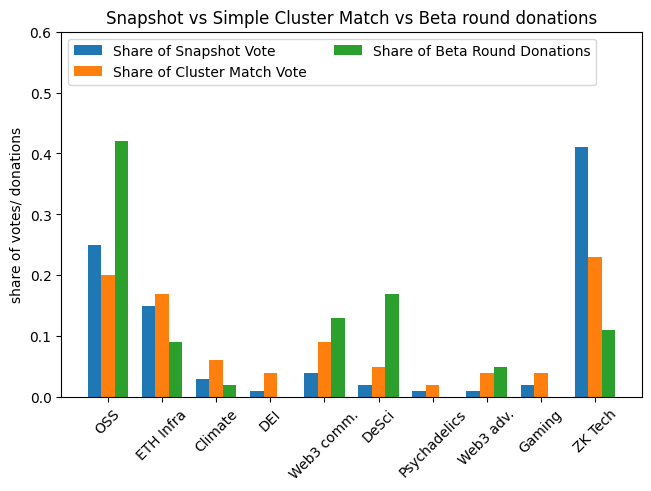
Notably, this algorithm takes a large chunk of votes way from ZK Tech and gives the Web3 community round a good boost in the right direction. But ultimately, there are some issues with strategic behavior that would need to be ironed out before we could use cluster match in this way (feel free to ask for details below). In any case, it achieves an EMD of 0.38.
4. Connection-Oriented Cluster Match via alpha round donations
This is the algorithm that Glen Weyl, Erich and I developed last year. The basic idea is to put agents into clusters, like in cluster match, but then also do pairwise discounting between pairs of clusters. Here, we chose to cluster agents by their alpha round voting behavior (since the large majority of voters in this snapshot poll also donated in alpha). Instead of putting voters in just one cluster each, we let them be in multiple clusters, with a different strength depending on their donation behavior (i.e., someone who donated to 10 OSS projects and 1 climate projects would have a higher “weight” with the OSS cluster). Lastly, I experimented with some other technical tweaks that I’m happy to go into in the comments. The results are below:
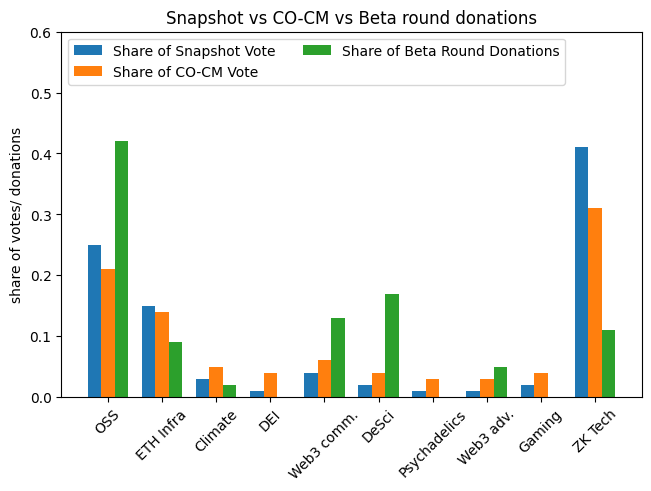
This algorithm is very near and dear to me, but I have to admit that it doesn’t look too hot here. Compared to the other implementation of Cluster Match discussed above, it only does better on ETH Infra. But, there are many parameters to tweak here, so I wouldn’t totally count it out. This implementation of CO-CM achieves an EMD of ~0.42, similar to pairwise (although a little bit better, once you look past the second decimal place).
There is more I’d like to talk about, but I should wrap this post up for now. Let me know if you have any questions. Big thanks to @umarkhaneth for getting me high-quality data on alpha round donations, and big thanks to @borisdyakov for suggesting I take a look at this dataset!
