Totally missed this in March - what an interesting insight into representation
1 Like
Great work @Fred and @ivanmolto - It is always important to look towards data, especially in a highly charged dynamic like a market downturn. It’s easy to make assumptions yet we must always keep ourselves in check to ensure governance decisions are not made emotionally but rather objectively and from a fully informed place of intention.
When we were discussing this and even though I had an inkling the contributor sell could not affect things as much, I really did not grasp just how much hodling was actually going on. The same with the pattern of other gov tokens which is why I made the suggestion to add that chart in order to give place this analysis against the broader market background.
I am keen to see these analyses progress and become a tool in the gov process. Perhaps, something we look to include in the improved versions of workstream accountability flow or in any voter matrix we may choose to adopt - provided they achieve balance between objectivity and personal takes.
5 Likes
The inverse is also true! This analysis does not show that selling tokens to market DOES not create downward price.
How can you draw that conclusion from that graph? You just showed a bunch of data that has a bunch of outflows and a large decline in price. There’s no rigor to this analysis method. There’s no control group, nor is there any analysis of the liquidity of the market in this analysis.
GTC is down 50% vs ETH over the last 30 days, so I dont think you can say the outflows are in line with the rest of the market decline.
This chart is from coingecko:

I think doing an analysis about this could be important, but more rigor is needed to be able to form conclusions backed by data in my opinion.
2 Likes
Hey! I really enjoy the discussion here. I would love to get an hour on the calendar to pull together various people with data backgrounds or interest within the DAO. We could do some introductions and share projects we’re working on.
Please fill out this lettuce meet if you’re interested: LettuceMeet - Easy Group Scheduling
All are welcome!
1 Like
Maybe this way:
the practise only deal with data anonymisation, and data infrastructure, and model performance evaluation.
With anonymised data, all the rest can be put as bounty so be publicly worked on by any contributors
What an interesting and unexpected find. Thanks for this work!
1 Like
Late reply here, but we’ve been hard at work getting data from off-chain CEXs added to the dashboard. This has proven to be harder than we anticipated, however we are now able to track sales from contributor addresses across all of the major CEXs which has been a big milestone.
I think you misunderstood my previous post; we could not find a correlation with our current data and methodology. Not being able to prove a hypothesis does not necessarily mean that the opposite is true.
Circling back to sell pressure from contributors;
We’ve recently added a graph over relative GTC price vs daily total contributor sales (DEX+CEX).
(A correlation analysis has not yet been initiatied at this point):
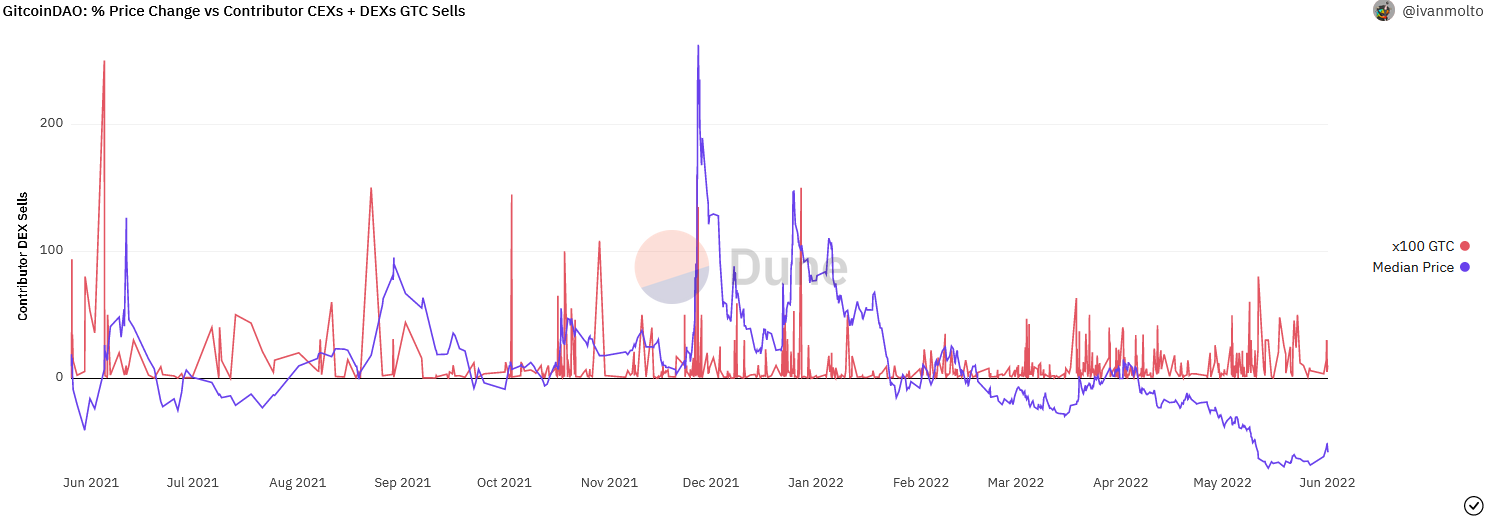
Even though we are now able to track contributor sales on CEXs we’ve yet to find a way to get accurate total CEX volume into the dashboard. Until we have this data available natively in Dune I’ve grabbed the daily volume (CEX+DEX) from Coinmarketcap and Coingecko and plotted this graph:
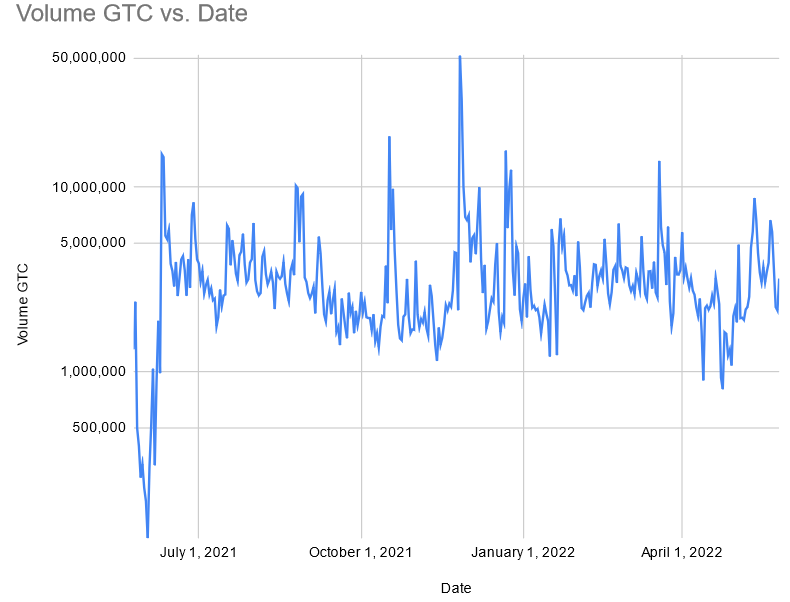
The volume has stayed between 1M - 10M GTC per day for the majority of GTC’s history.
Median GTC volume according to Coinmarketcap = 2.7M GTC/day.
Median GTC volume according to Coingecko = 2M GTC/day.
This is the graph of total GTC sales from contributors on DEX & CEX:
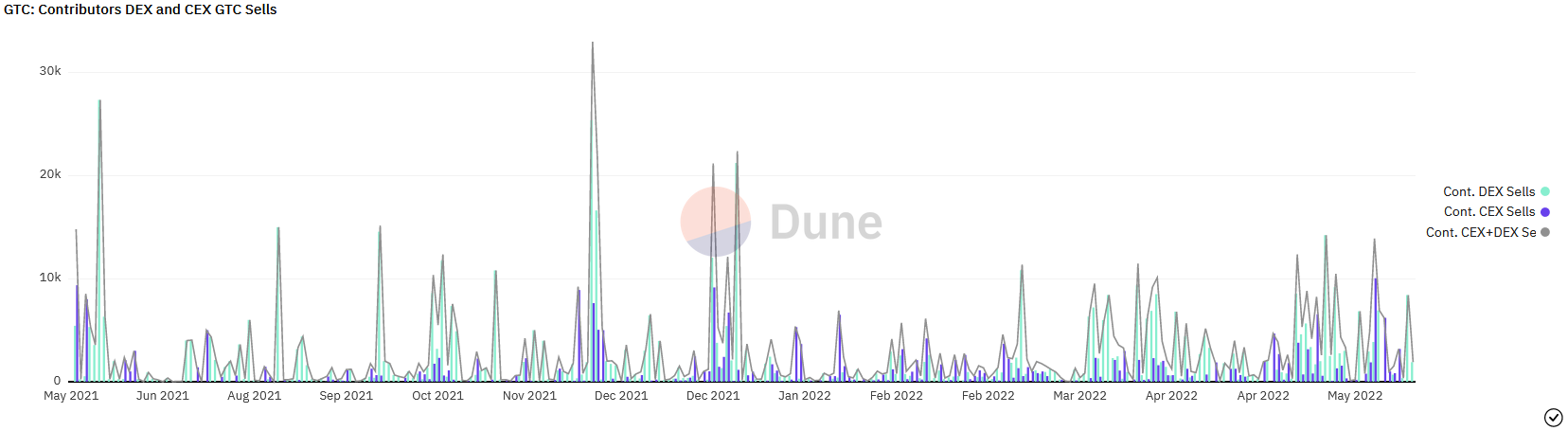
Even on days of relatively large GTC sales from contributors, 10k GTC/day, contributor sell pressure is still less than half a percent of the median daily volume.
(10k GTC/day is roughly equivalent to the 90-95th percentile. A normal distribution graph of contributor sell pressure is in the works. This will allow you to grab any percentile of contributor sell pressure and compare that to the total daily volume.)
I think you’ve misunderstood the governance token part of the dashboard as well. We are comparing GTC to other governance tokens, which are all down vs ETH.
For convenience we’ve now grouped together other governance tokens into a basket on the graph. Although we haven’t initiated a proper correlation analysis to define the strength of the association, a correlation is clear:
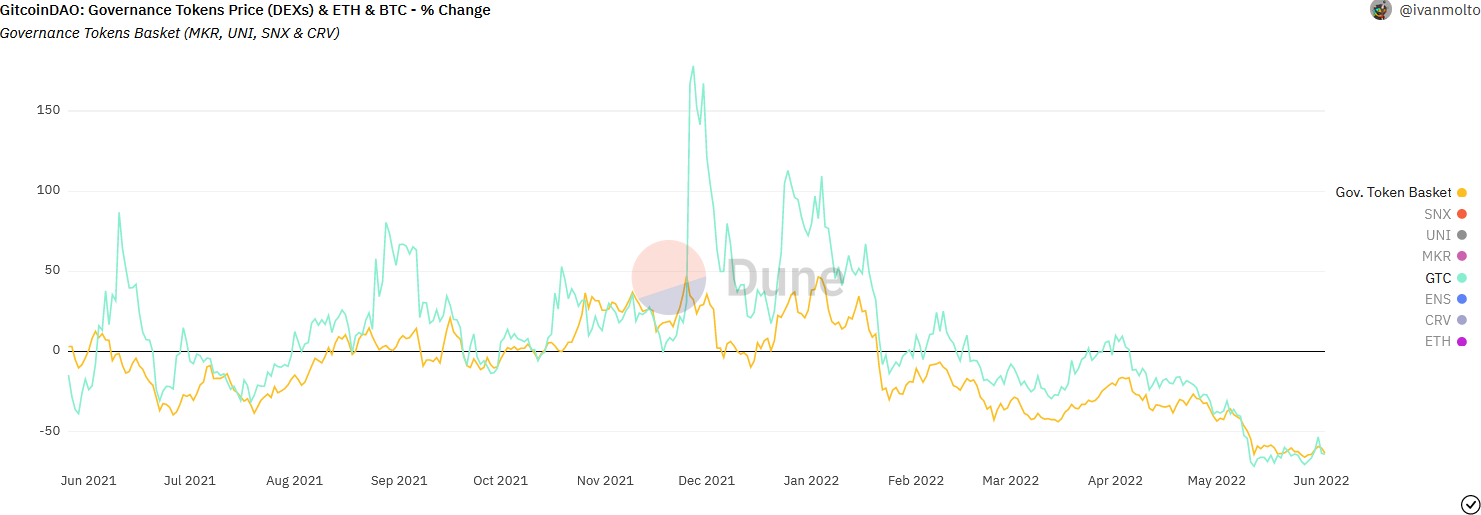
As stated earlier, the dashboard will receive continuous updates as we are able to track more data. I’d be happy to continue the conversation and discuss things further if you are interested in helping out!
(Please note that Dune is performing internal upgrades at the moment and some graphs will not load properly until this work has been completed. The dashboard may also be slower to load)
5 Likes
Thank you for all the good work you do, I agree that Data Science should be one of the priorities of the Gitcoin DAO, the insights that can be gleamed from a well done data analysis model could be a big help in further optimizing the entire grants system.
There is a popular saying where I come from, it goes this way.
“In God we trust, everyone else should bring data” I believe that at the heart of everything Gitcoin is trying to achieve with public goods, being able to keep track of the true impact of Gitcoin’s operations both within the Gitcoin Ecosystem and to the wider ethereum community could give the leadership a true sense of where the DAO is and precisely where it should be going, the results of a good data culture could serve as the best possible compass for Gitcoin DAO, the answers are all in the numbers.
- keneeze.eth🔥_🌱 (Wildfire DAO, Public Goods Operator)
I will try to be as short and simple as possible.
Data science is a very broad field with multiple areas, like data analysis, statistics, mathematics such as differentiation and integration, linear algebra, dealing with databases, SQL, big data, business intelligence, machine learning, deep learning, artificial intelligence, dealing with natural languages, image classification, reinforcement learning, and simulation. There are also other areas under data science.
But initially, let’s try to choose some tools that can benefit us in Gitcoin.
There are many other tools, but let us now mention only these tools.
One of the tools of data science is the use of programming languages and their various libraries. The most famous programming languages used in data science are Python and R, but the majority depend on Python.
There are many libraries related to data science, but let us mention some of them. TensorFlow Keras Scikit-learn PyTorch NumPy Pandas Seaborn Matplotlib
And other tools, such as Excel
Statistical programs can be useful. There are free, open-source, and powerful programs like JASP.
Business intelligence programs such as Microsoft Power BI, Tableau, and Google Data Studio are very useful in building a control dashboard that summarizes data, tracks it, and does other things.
Statistics and mathematics are essential in data science. It can be used by statistics programs or by the Python programming language, and some of the libraries associated with it Statistics is a very broad field and is fundamental to data science.
dealing with databases and the SQL language
Data visualization
Machine learning and deep learning help predict, classify, and cluster.
Tools that help in the field of crypto
There are also many tools here, but let us mention some of them.
Blockchain network browsers
Dune Analytics, Flipside Crypto, and Footprint Analytics
The Graph
Tools like Defillama,Token Terminal, Coin Market Cap, Coingecko, Glassnode, Debank, Tradingview, Messari, and other tools
Data science is useful in any department and in anything, as long as there is data related to it.
Like any crypto project, data science will help in these departments.
Products Department:
For any product, we will find that there is data related to it, and by analyzing it, the performance of these products can be greatly improved and also developed.
Financial Department:
Analyzing financial data is very useful in developing future financial plans, improving current financial performance, and finding solutions to financial problems.
Marketing department:
I think it is essential that the use of data science is very beneficial to the marketing department, and the use of data science is a long explanation that requires a separate topic.
Governance and community management:
Data science is very useful when analyzing data in forums. Snapshot, Discore, and other governance tools will be very useful in improving decentralization and decision-making processes.
External environment:
Analyzing competitor data and crypto market data in general may sometimes be more important than data analysis for the project itself.
Research and development:
Data science helps with the reports and insights extracted in the research and development department, if there is such a department in any crypto project.
Machine learning and deep learning tools related to classification and clustering can be used to build tools that contribute to increasing security in products, but this is a complex topic that would take a long time to explain.
Simulation can also be used to develop some decisions and some products, and some machine learning, deep learning, and artificial intelligence tools can help in this.
Providing data analysis reports to the community helps increase transparency and decentralization.
Public management benefits from all reports generated by all departments.
Now, how will things go?
The first step is to determine the data sources. Where can the required data be obtained?
The most difficult point is how to deal with it, meaning that if the required data is stored in databases, then it is easy to deal with, but if they are, for example, on a website, then we will need to write code to scrape data from this website. There are other cases in which data is stored, and each case has different solutions.
Sometimes it is not possible to extract data.
It is important to know the goals of each department.
What is the goal?
After defining the goal, we can know the questions related to achieving it.
We will use data science to find answers to these questions.
I will give a very simple example. To explain it,
If I had a goal, for example, to write topics on this forum that would receive a lot of interaction,
This is the goal.
Therefore, there are questions related to this goal: What are the topics and trends that can achieve interaction? How can I know that?
Using data science, I will analyze the data on this forum to find which topics have the most interaction and, therefore, know what direction I should write about.
This is how things work. Every department has goals, and these goals produce questions. By analyzing the data, we try to find answers to these questions.
If we can organize the data extraction process, the rest of the steps will be easy.
Data science and how to use it I can write several topics about it and publish them here on the forum if this is allowed.
I am open to discussion.
3 Likes