Closing the gap: FDD Sybil defense model and Gitcoin Passport
This post is intended to summarize some of the discussions happening around Sybil defense and the potential synergies between FDD and Gitcoin Passport’s approaches.
Gitcoin aims to optimize capital allocation within a grants round (GR), primarily by preventing capital capture by Sybils. There are currently two independent systems in place for this that run in parallel. First, a multiplier (“Trust Score”) is assigned to an individual’s donation depending on their non-Sybil traits - the more likely they are to be a real human the more their donation is multiplied in the matching pool. This Trust Score is derived from evidence of personhood that a user collects in their Gitcoin Passport (GP). The other way is Sybil Account Detection (SAD) where accounts that are identified as potential Sybils by a human-in-the-loop machine-learning pipeline are “squelched” - i.e. ejected from the GR. As we move towards Grant 2.0 there is a need to optimize these processes and pivot towards a more composable Sybil defense system that can be tuned by individual grant owners to their own community’s needs.
Differentiating SAD from GP
The fundamental difference between SAD and GP is that GP is proactive - it provides a continuous metric for a user in advance of them participating in a grant round and uses that information to define their impact. It takes into account the ‘stamps’ a user has in their passport, each of which provide evidence that the user is a real human, and increments their weighting in the matching pool proportionally to the weight of evidence in their passport.
On the other hand, SAD retrospectively examines an individuals behaviours, generates a probability that they are a Sybil then applies a threhold to convert that probability into a binary Sybil/nonSybil outcome. SAD then retroactively removes Sybils from the round.
SAD and GP have been developed in parallel but mostly independently. Having two independently-developed Sybil defense systems operating separately but in parallel hints at a future where any number of systems can run in parallel and the overall trust score is a dot-product of each trust vector. However, at the same time, there are also opportunities for synergistic relationships between anti-Sybil systems. A good first step in identifying such synergies is to compare the outcomes from SAD and GP in the latest GR to see how closely aligned they are.
If both SAD and GP approaches to Sybil defense were perfect, they would silence the same accounts, and those accounts would all be Sybils. In reality there is a gap separating these two processes because each one is imperfect in its own unique ways.
In a well-tuned system, we might expect to see a positive relationship between the percentage of accounts identified as Sybil as the Trust score of those same accounts assigned by GP increases. The plot below shows the proportion of accounts labelled as Sybil by SAD plotted against the GP trust score for GR14. There is a weak positive relationship but with significant deviations from a simple linear relationship. These deviations represent differences in the methods, error and opportunities for learning.
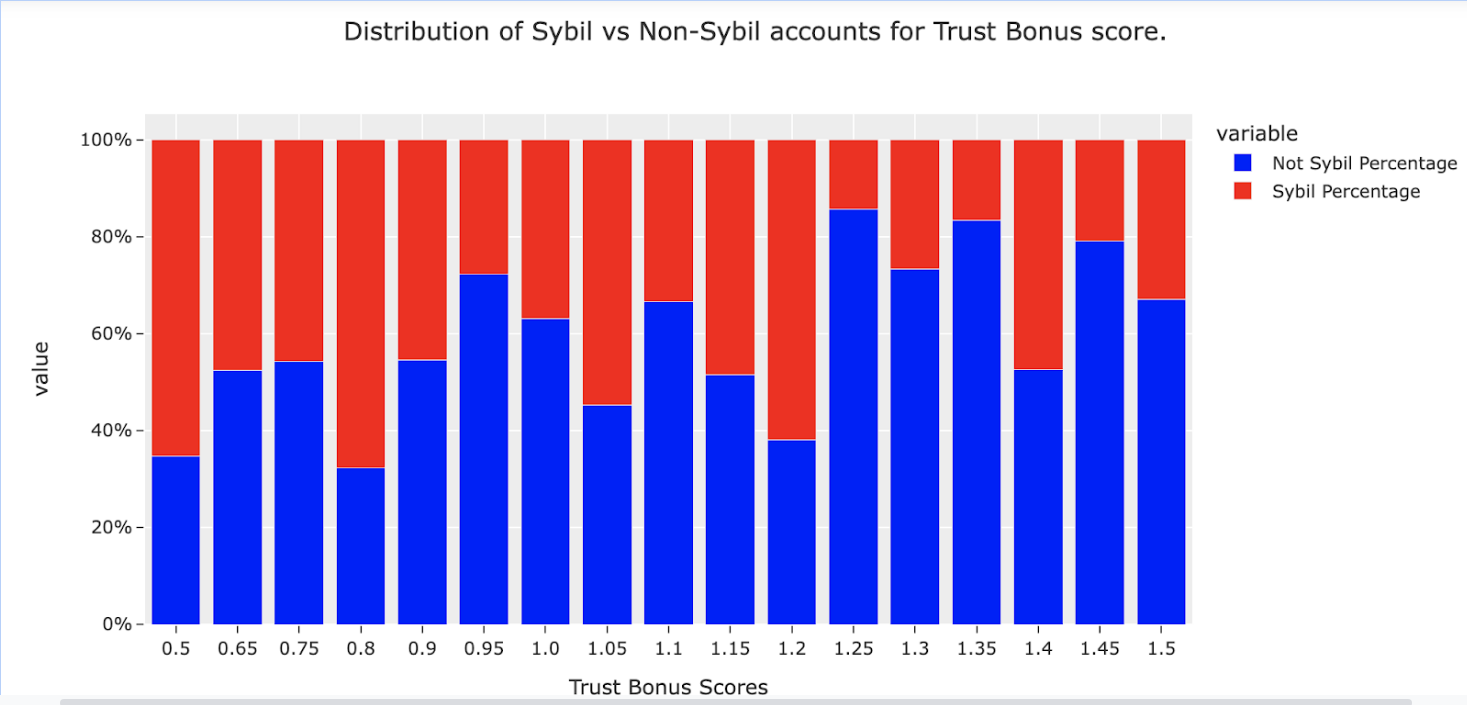
Cross-calibrating between SAD and GP with the aim of “closing the gap” could improve the performance of both, identify areas of redundancy and potentially nudge us towards unifying them into a cheaper, more efficient optimization layer. The space separating the exclusionary logic of SAD and the inclusionary logic of GP is where the greatest opportunities for learning and optimization lie.
Proof of personhood
GP requires users to gather evidence of personhood in advance of participating in the grants round. This can include proof of engaging with a range of on and off-chain activities such as Twitter, Facebook, Proof-of-humanity, BrightID and several others. More evidence gives the user a greater score which in turn amplifies their influence in grant funding.
However, most Gitcoin users do not attempt to gather proof of personhood in advance, either because they are not sufficiently well incentivized to do so or because they are unaware of the benefits. While it might be expensive for Sybils to gather lots of robust evidence of personhood, it is still relatively cheap to gather something. This means many Sybils actually have higher trust scores than real users! In this case GP will invert the desired outcome of silencing Sybils relative to real users. A well-tuned system would make it very expensive for Sybils to gain outsized influence, but cheap for real users to prove their personhood.
Squelching
However, it is still likely that those Sybils that sneak through with cheap passports may exhibit some Sybil behaviours that can be detected by a retrospective SAD algorithm, correcting the outcomes by squelching offending users. SAD, however, is very computationally heavy and also requires human evaluators to tune the model regularly. It is in a constant state of flux because of the cat-and-mouse nature of Sybil defense. This is a bit of a barrier to making SAD composable for Grants 2.0. There are a few possible routes to overcoming this. SAD could incorporate some heuristics that give obvious Sybil’s and non-Sybils an escape hatch to instant classification before they ever reach the SAD algorithm.
Heuristics
Ideally, heuristics are cheap and easy for real users to conform to, but expensive and awkward for Sybils. This dichotomy can be overcome in many cases by aiming for identifiers real people already have and are hard to replicate quickly. A great example of this is social media. Gitcoin donors are likely to have one or more of Twitter, Facebook and Google accounts, each of which are likely to have existed for some substantial amount of time and have a network with a transaction a history associated with it. For those users it is easy and cheap to connect their account and prove their personhood, but it is awkward and time-consuming for Sybils to create multiple accounts and generate an activity history for each one.
Strong heuristics
Strategic use of heuristics could lighten the computational load on the SAD algorithm and make it faster and cheaper to run. Some of the heuristics could come from GP. For example there are some markers of personhood that are prohibitively expensive for Sybils to gather, such as paid subscriptions, ownership of certain NFTs (especially non-transferable ones) or limited-run POAPs that had strict eligibility requirements (e.g. those given out at a specific event or for taking some specific action). The plot below identifies a cluster of accounts that provably hold membership in some specific DAOs. They have noticeably better performance in the GR than the majority of accounts.
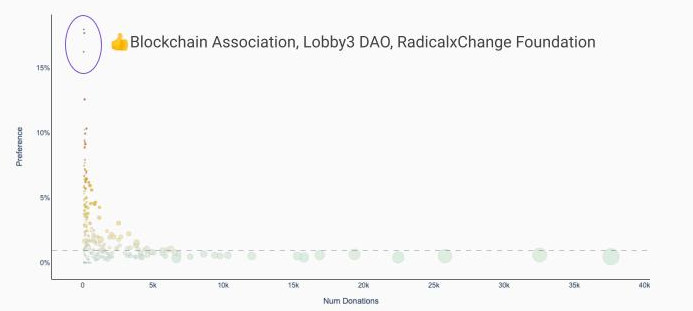
A paid subscription to Bankless DAO, or a top-tier LinkedIn profile, for example, cost upwards of $1000 - probably far too expensive to be purchased in bulk for the purpose of a Sybil attack. Non-transferable NFTs have been awarded for certain educational programs such as the Consensys Blockchain Developer Bootcamp - these were only awarded to paid attendees that passed several rounds of examination and are non-transferable, so would be very difficult for a Sybil to obtain, certainly in any meaningful volume. There have been POAPs for running validators on the Ethereum merge testnets - these are only awarded to addresses that provably ran validator nodes for some threshold amount of time before, during and after the testnet merges - it would be awkward and time-consuming for a Sybil attacker to spin up Ethereum validators to farm those POAPs. Another example that is already used by SAD is the edit distance (Levenshtein distance) between account names. Accounts with low edit distances might have an enhanced probability fo being Sybil because the low edit distance is often indicative of automatically generated accounts, especially so when the number of accounts linked by small edit distance are larger. Some threshold number of accounts with a certain edit distance could trigger automatic removal from the GR.
These type of indicators could fast-track a user to immediate non-Sybil status and maximum influence in the matching pool without needing to include them in the SAD algorithm. Equally, there are likely heuristics that can be used to fast-track users to disqualification too. This could act as an initial screening implemented as part of a “data cleaning” function before the main model executes.
Weaker heuristics
While the previous section identified some examples of ‘binary’ heuristics that give immediate high confidence binary Sybil/non-Sybil tags, there are a wide range of others that can be used in combination with other evidence to influence the SAD model or GP trust score.
On-chain activities that cost gas do not scale well for Sybils because of the expense, but may well already exist for many Gitcoin users or be cheap enough on a single-use basis that it is affordable for real people, unaffordable for Sybils. On the other hand, social media accounts are cheap and easy to create, which is good for accessibility but probably provides weaker evidence of personhood because they are cheap to create fradulently.
The low cost of creation for social media accounts is already reflected in GP data. The chart below shows the relative popularity of social media versus on-chain versus proof-of-personhood verification in current GPs.
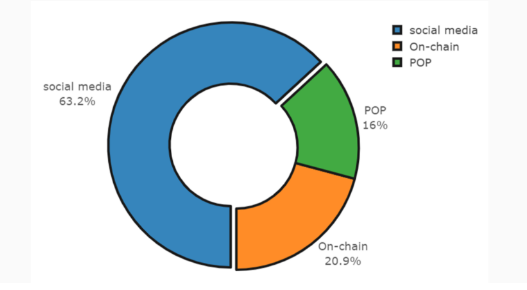
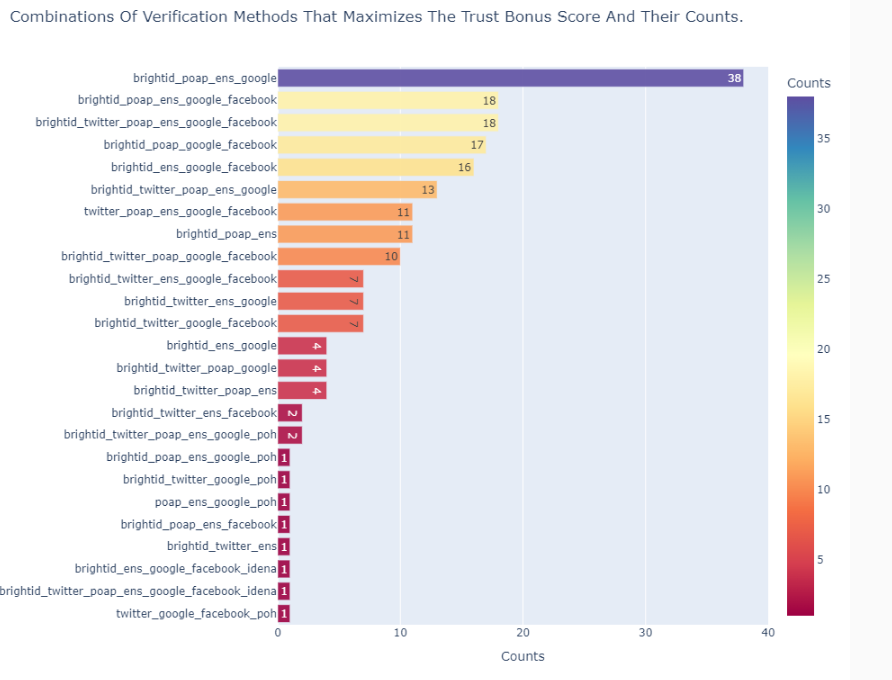
Interestingly, the popularity is roughly inverse to the effect on the trust Bonus score. The following plot shows the combinations of verification methods that maximize the trust score. Google and Facebook accounts are included in the top performers, but only when they are alongside non-social on-chain or proof-of-personhood evidence. The best performing combination includes BrightID and ENS domain name ownership. Social-media only is not a very effective trust-booster.
It seems simple to weight on-chain or proof-of-personhood verification heavily in GP or SAD, but new users, who may also be new entrants to Web3 need to prove themselves as non-Sybil even though they have fresh wallets without much of a transaction history. Social media accounts are generally good for this, but there are likely populations of users who choose not to use social media and also keep their on-chain activity private for all kinds of valid reasons but still wish to participate in Gitcoin GRs. These people might be susceptible to being squelched or silenced in a GR.
GP and SAD synergies
SAD currently uses some GP data but also data from the existing centralized grants system as features in its machine learning pipeline. This gives more information to the model for making Sybil classifications but will need to be phased out to support Grants 2.0 because that same grant data will not exist. SAD also returns a binary outcome for a user, which is not very conducive to round-on-round growth and learning for new users and potentially quite unfriendly in edge cases where non-Sybil but low-competence users or users with an unusual profile that the model determines to be Sybils are ejected from the system altogether. A continuous measure that scales a user’s voice according to their trustability might provide a smoother experience for users and enable them to gradually grow their influence over successive rounds. Interestingly the ML model used by SAD already outputs a score between 0-1 representing the probability that a user is Sybil. This value is then thresholded to provide a binary outcome, but it doesn’t necessarily have to be. In a given GR one could imagine a GP stamp representing a user’s SAD score in the previous GR, if they participated. This makes proactive use of retrospective analysis and may incentivize good behaviour because users know that honest actions are rewarded in future rounds, and that Gitcoin has a memory for bad actions built into the passport.
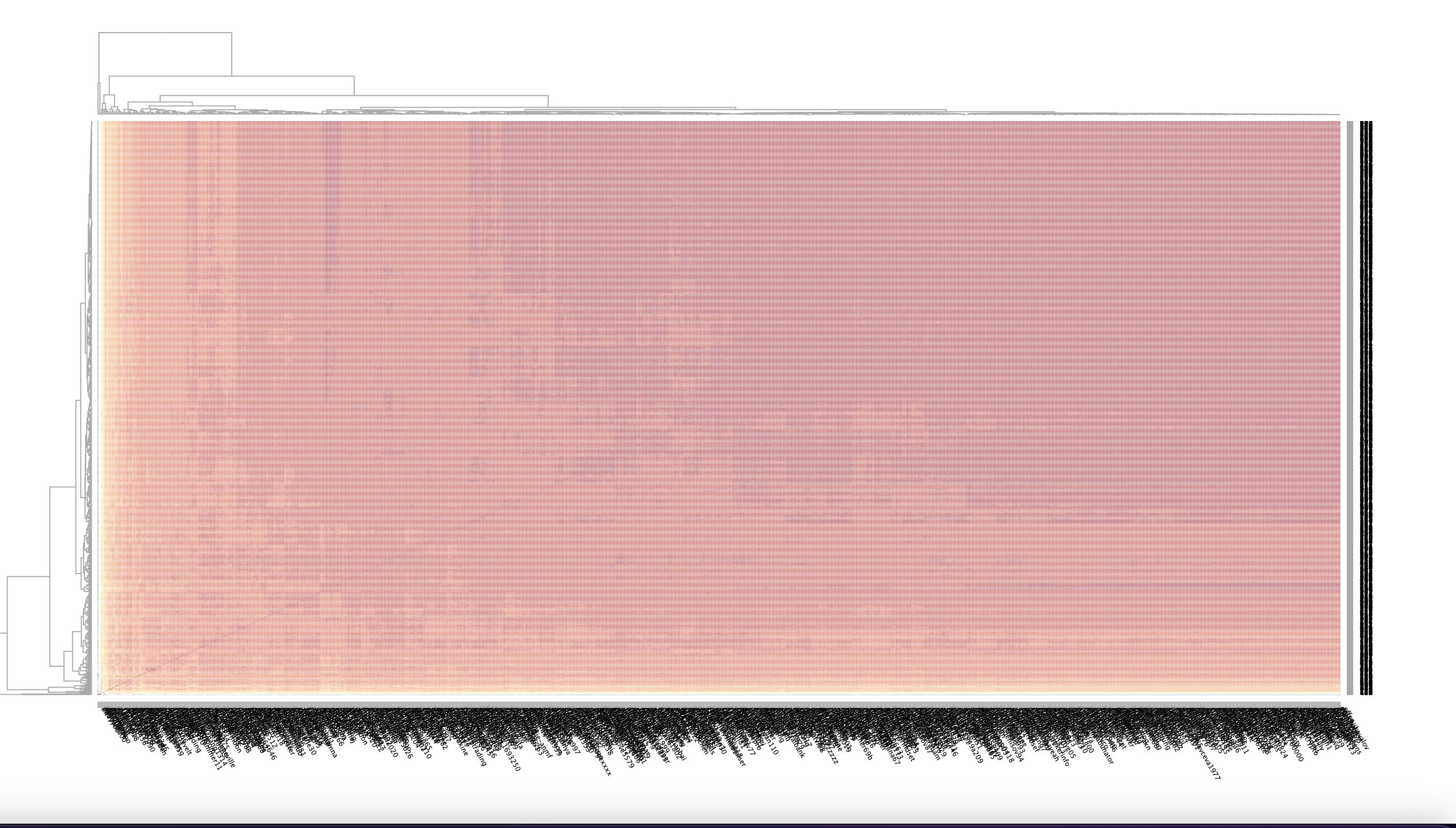
A related idea is DonorDNA - a vector of Booleans for a given user where each position in the vector maps to a specific grant. The value is 0 if the user did not donate to the grant and 1 if they did. The vectors can act as an identifier for a specific user that can be compared with other users quantitatively using lexicographic metrics such as the Hamming distance between them. This gives an efficient way to compare donation profiles between users, especially if this can be combined with knowledge of the users’ Sybil/non-Sybil status so that a typical Sybil DonorDNA fingerprint can be established. The Hamming distance from that benchmark fingerprint could be used as a component in the Sybil-probability calculation and also be included as a field in the user’s Gitcoin Passport. Eventually, more degrees of freedom could be used in each position in the vector to give a very information-dense fingerprint in a user passport. The plot below shows a visual representation of the donorDNA vectors for accounts in GR14.
GP provides a way to get the right data information into the SAD model without relying on access to personally identifiable information about the users - the trust score abstracts that away. The trust scoring used by GP could be used as a “clean” feature to feed into the SAD model. This might make some of the existing features redundant, leading to efficiency gains. At the same time, data from GP can also be used to implement heuristics in the SAD model, acting as an initial filter for obvious outcomes that further reduces SADs computational burden. Reciprocally, the analysis undertaken by SAD can infleunce the weightings given to GP stamps and provide GR-level insights into GP effectiveness.
SAD could become an auditing system for a GR that is protected using GP. GP, tuned using SAD insights, is used as the primary Sybil defense and SAD retrospectively analyses the round to determine how well GP performed and makes recommendations for tuning in advance of the next round.
Composability
Other differences between SAD and GP include the degree of “forkability”. Being quite computationally heavy and requiring Gitcoin grant data, SAD is not very composable in that it would be difficult for individual projects to run it for themselves with their own parameter tuning. GP, on the other hand,is very forkable. Individual grant owners can interact using a simple API and tune the anti-Sybil defenses of an individual project to their own individual needs. SAD can inform projects of their recommendations but cannot really adapt to individual projects needs. It could be that in a Grants 2.0 world, the value of SAD is in a) providing recommendations about individual users ‘on request’ rather than squelching suspected Sybils from the round unilaterally, and b) providing insights that tune the GP trust scores, possible providing recommended ‘default settings’ for GP.
Passport value and cost-of-forgery
One of the potential metrics that can arise from a combination of GP and SAD is a cost per fraudulent account. The SAD model can provide a list of accounts tagged as Sybils, while all users’ passports contain stamps relating them to specific real world actions or assets that have a monetary cost associated with them (this is easy for, for example NFTs or subscriptions that have a queryable purchase price, less easy for POAPs that represent some time spent or some achievement). This means that by calculating the “value” of the population of Sybil and non-Sybil accounts and creating a simple model, it is possible to attach a minimum cost required for a Sybil to look like a real user. This would be a useful metric because the whole idea is to maximize the cost-of-participation for Sybils while minimizing it for real users. The cost-per-forgery could be used as a foundational metric for assessing the overall anti-Sybil processes across Gitcoin. The top-level goal could then be to make the cost-of-forgery increase round on round.
It would also be possible to extend the idea of cost-of-forgery to monetary staking. Instead of generating a passport value using proof of past actions a user could fast track their way to an equivalent passport-value by staking $GTC in a deposit contract. By directly staking the $GTC they fast-track their way to a non-Sybil status in the GR. This works only if the threshold monetary value of the passport is greater than a rational Sybil attacker would be able to lock up in a deposit contract. By staking $GTC a user can buy proof of personhood using an amount of money slightly greater than a rational Sybil would be willing to spend. By generating the equivalent passport value through stamps, you buy proof-of-personhood with time, effort or expertise instead of $GTC. It is almost analogous to being able choose to participate using proof-of-work or proof-of-stake depending on the resources you have available - be provably anti-Sybil by showing you did something of value (using passport stamps) or be provably anti-Sybil by showing you staked something of value using $GTC.
Project-level incentives
Sybil defence often focuses in on identifying and “squelching” individual users, but a lot of Sybil behaviour is explicitly or tacitly encouraged by projects themselves, for example by incentivizing Sybils with the promise of future airdrops. One way to manage this is to “tax” a project for their Sybil engagement. SAD makes it possible for Sybil’s to be identified retrospectively, so the number of Sybil accounts that donate to a specific project can be known shortly after the grant round ends. GP also makes it possible to attach a minimum cost to a Sybil. These metrics could be used to tax a project proportionally to their Sybil/nonSybil ratio, with the money diverted to other projects in the next GR, or this could be a continuous stream where projects are taxed in near real-time and the money flows back into the matching pool, incentivizing projects to actively discourage their communities from using Sybil tactics. This also pushes some responsibility for Sybil defense away from Gitcoin and into communities.
Conclusions
Both GP and SAD aim to minimize the influence of Sybil’s on a GR. They take different approaches to achieving this, with SAD focusing on retroactive identification and removal of Sybils and GP providing preventative measures in the form of a user passport that contains evidence of personhood. Both these approaches are highly valuable in their own right but Gitcoin can level up its Sybil defense by combining them in creative ways. As we approach Grants 2.0 this is important preparatory work that lays the foundations for composable, independent Sybil resistance mechanisms that can be deployed and customized by individual grant owners.