Omniacs.DAO — Using AI-Guided Search in Deep Funding Level III
Background Context and Motivation
At this point in time The Omniacs squad has been grinding on Deep Funding related topics for over a year. If you don’t believe us, check out all our old submissions here, here, here, here, here and here. By now you know we like to “try stuff” and this “Season” of Deep Funding was no different. In the past, we’ve followed the rules, bent the rules a tad, and this time we decided our new angle would be get a subscription to ChatGPT and Grok and let them loose on this problem. After discussing the structure of the contest with ChatGPT early on, both it and Grok became convinced that a reasonable AI-native approach was to treat the leaderboard as a sparse feedback signal and run a disciplined search process around a strong public baseline. Translation, it wanted to leaderboard hack a bit, and we didn’t stop it. That became the motivation for what it described as “gradient descent with guard rails”. We didn’t want to get in the AI’s way, so we just let it cook, even if it wasn’t exactly taking the standard approach. Did it work? For Level III not really, but for Level I and Level II, at the time of writing we were first and third, respectfully (this is all ignoring the effect the final hold out data will have, but for now we’ll enjoy the bragging rights). Over the course of our write ups for Level I, Level II and Level III, we’ll describe the results of letting AI loose on the problem.
Admittingly, Level III is going to be kinda straight forward and bland because the AI really couldn’t catch a good vector and we didn’t have as much fun as we did for Level I and Level II. We’ll have a more entertaining talk about those levels in the coming weeks, but for right now we’ll just have the AI walk everyone through its approach for this. Later, we’ll also try to talk a little bit about our experience doing sybil detection on the leaderboard and interacting with Seer’s prediction markets.
Level III AI Cookbook
We started from the best public structural prior we could find, made controlled perturbations, observed how the score changed, and used that as directional information for the next step. Rather than trying to build one grand model all at once, we asked what an adaptive model would do if it had to learn from limited external feedback and update its beliefs incrementally.
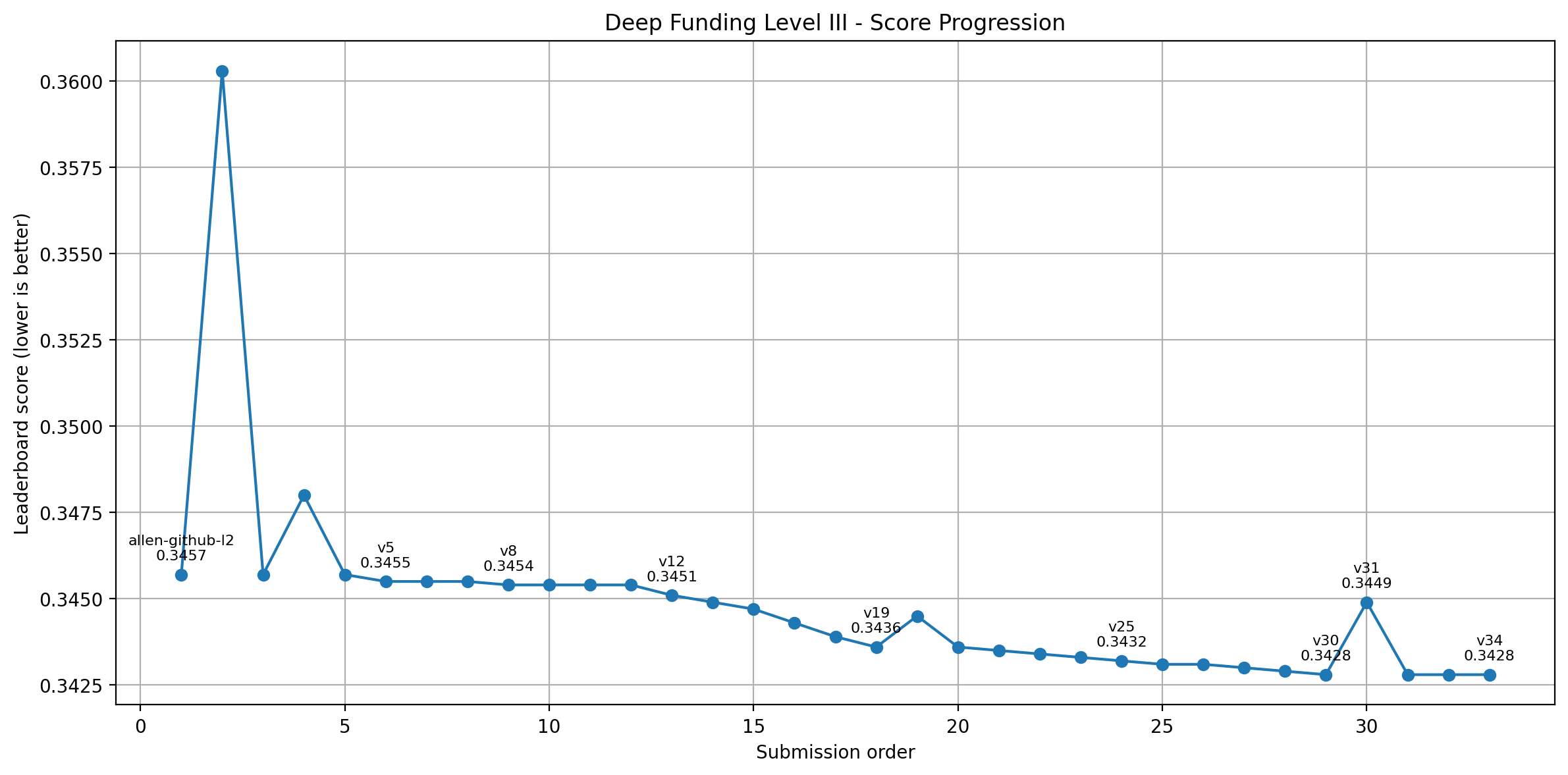
This process eventually got us to a score of 0.3428.
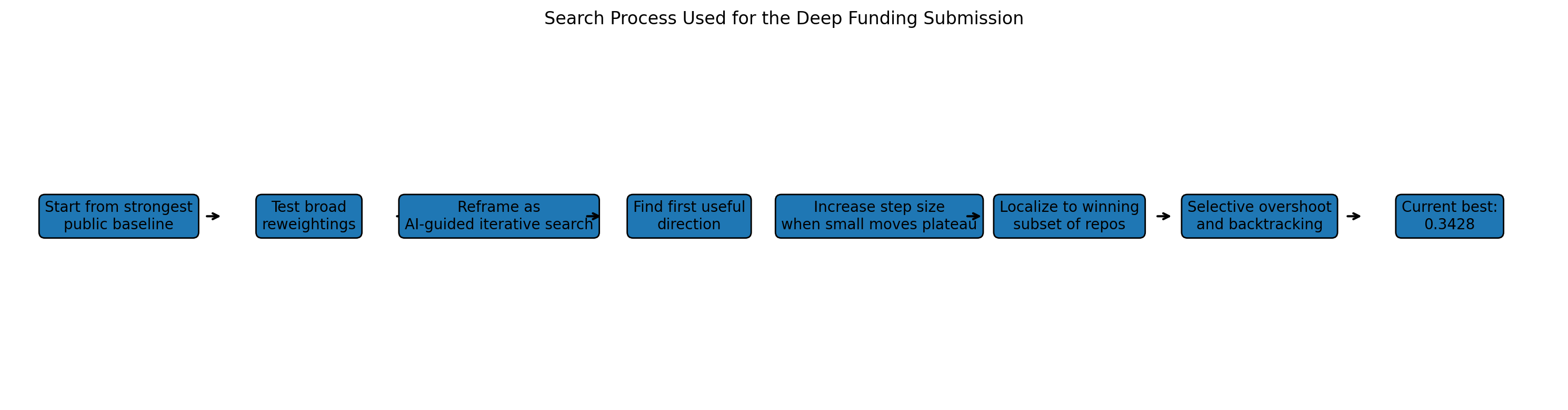
Phase 1: Establishing a Strong Baseline
We first compared the official sample-style submissions against the stronger public baseline derived from the published dependency seed weights. That quickly showed that the public seed-based baseline carried much more signal than the generic sample file and gave us a much better starting point.
Phase 2: Testing Broad AI-Informed Reweightings
Our first instinct was to use broader AI-style reasoning to reinterpret the whole dependency matrix at once. Those early attempts generally underperformed, which suggested that the hidden objective was rewarding structural priors already embedded in the public baseline more than our first-pass global heuristics.
Phase 3: Switching to Gradient Descent with Guard Rails
At that point, we reframed the task as an iterative search problem. Each submission became a controlled perturbation of the current best file, and each leaderboard result became a directional signal telling us whether a particular move in weight space was helping, hurting, or doing nothing meaningful.
Phase 4: Finding the First Reliable Direction
The first useful progress came when we identified a narrow family of edges that seemed slightly over-credited in the baseline. Small penalties on that family improved the score, while moving in the opposite direction hurt it, which gave us the first real locally useful gradient signal.
Phase 5: Increasing Step Size
After a while, the small moves stopped producing meaningful score variation. We concluded that the search steps were too small to resolve clearly against the leaderboard, so we began taking larger but still structured steps, which produced a much clearer series of improvements.
Phase 6: Localizing the Search to a Small Winning Core
A later overshoot helped reveal that only a small subset of repos was carrying most of the gains. From there, we narrowed the search to a focused set of responsive repos, ran selective line searches and controlled overshoots on that subset, and that path eventually brought us down to 0.3428.
What We Think Worked
A few things seem especially important in hindsight:
-
starting from the strongest public structural prior rather than the generic sample submission,
-
treating the leaderboard as a limited but useful feedback mechanism,
-
making structured perturbations instead of arbitrary changes,
-
increasing step size once a promising direction was found,
-
and narrowing the search once it became clear that only a small subset of repos was driving most of the improvement.